*해당논문은 Vision Transformer for NeRF를 위한 논문 리뷰 글입니다! 궁금한 점은 댓글로 남겨주세요!
Vision Transformer for NeRF paper: [2207.05736] Vision Transformer for NeRF-Based View Synthesis from a Single Input Image (arxiv.org)
Vision Transformer for NeRF-Based View Synthesis from a Single Input Image
Although neural radiance fields (NeRF) have shown impressive advances for novel view synthesis, most methods typically require multiple input images of the same scene with accurate camera poses. In this work, we seek to substantially reduce the inputs to a
arxiv.org
Vision Transformer for NeRF github: GitHub - ken2576/vision-nerf: Official PyTorch Implementation of paper "Vision Transformer for NeRF-Based View Synthesis from a Single Input Image", WACV 2023.
GitHub - ken2576/vision-nerf: Official PyTorch Implementation of paper "Vision Transformer for NeRF-Based View Synthesis from a
Official PyTorch Implementation of paper "Vision Transformer for NeRF-Based View Synthesis from a Single Input Image", WACV 2023. - GitHub - ken2576/vision-nerf: Official PyTorch Implemen...
github.com
Contents
2. Background Knowledge: ViT, NeRF
- Multi-level feature maps and Concatenation
Simple Introduction

역시나 컴퓨터 비전 분야든, 딥러닝 분야든 모델을 결합하는 것은 공학자의 임무이다(?)
기대했던 대로, Vision Transformer와 NeRF과 함께 쓰인 모델이 있었다.
Transformer가 현재 컴퓨터 비전 분야를 꽉 잡고 있는 만큼, 언젠가 NeRF도 오직 Transformer으로 구성되어서 학습되는 모델이 나왔으면 좋겠다!!
한번 ViT와 NeRF과 어떻게 활용되는지 알아보자.
Background Knowledge: ViT, NeRF
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
NeRF 논문 리뷰: https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
해당 논문리뷰는 ViT와 NeRF에 대한 지식이 갖춰있다고 생각하고 진행됩니다!
Method
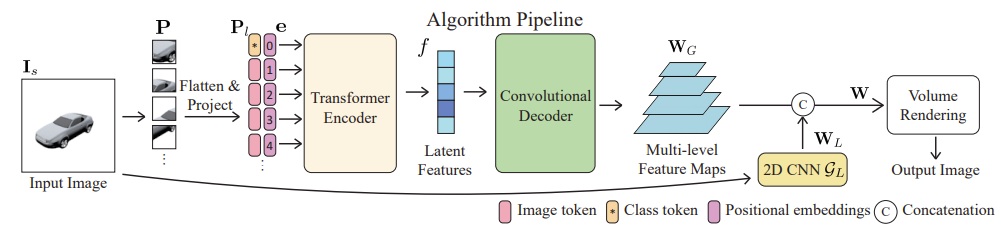
1. Vision Transformer와 똑같은 방법으로 처음에 진행된다.
- Image를 8x8 patch로 나눈다.
- Flatten을 한 후 linear projection을 진행한다.
- 처음은 Class token, 그리고 나머지는 patch token으로 설정한다.
- Positional encoding을 적용 한다.
- Transformer encoder에 넣는다.
2. 1D Latent features을 transformer encoder에서 얻은 후 convolutional decoder에 넣는다.
3. input image를 2D CNN에 2D feature map을 얻는다.
4. Convolutional decoder에서 나온 multi-level feature maps과 2D feature map을 concatenation을 한다.
5. 그리고 NeRF를 통해서 volume rendering을 진행한다.


+) NeRF를 통해서 똑같이 volume rendering을 진행한다.

+) Transformer encoder와 Convolutional Decoder의 구조이다.
1. Multi-level feature maps and Concatenation

일단 Transformer encoder의 구조를 보면, Jx transformer encoder가 있고 각각에서 나온 j번째 latent features를 만들어낸다.


그리고 형성된 j번째 latent feautures들은 각각 Convolutional decoder에 들어가서 각각의 features map이 된다.
그래서 Multi-level feature maps이다.

최종적으로 Multi-level feature map(global feature map)과 2D CNN에서 형성된 local feature map을 concatenate하기 위해서 convolutional layer을 통해서 모든 정보가 fuse된 hybrid feature map을 만들어낸다.
Convolution meanings
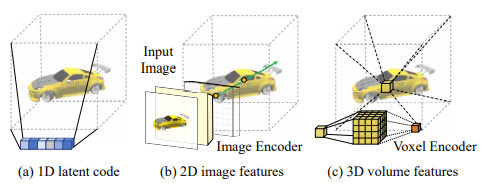
이 논문에서는 1D latent, 2D feature, 3D volume에서 각각 volume rendering을 했을 때의 장단점을 얘기하고 접근법을 소개한다.


1. 1D latent variables은 compact한 format안에서 전반적인 shape에 대해서 encode 하는 역할.
2. 2D features은 visual quality를 높이는 역할.
3. 3D volumes은 shape을 refine 해주는 역할.
이렇게 생각하고 모델의 접근법을 만들어내었다.
이런 meanings이 나중에 모델을 상상하고 만들어낼 때 큰 도움이 될 것 같아서 정리하였다.




+) Feature의 dimension이 1D, 2D, 3D에 따른 장단점을 논문의 저자들이 적어둔 것이다.
- 2023.01.14 Kyujinpy 작성.



