*DETR 논문 리뷰를 위한 글입니다! 궁금하신 점이 있다면 댓글로 남겨주세요.
DETR paper: [2005.12872] End-to-End Object Detection with Transformers (arxiv.org)
End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
DETR github: GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
GitHub - facebookresearch/detr: End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers. Contribute to facebookresearch/detr development by creating an account on GitHub.
github.com
Contents
2. Background Knowledge: Vision Transformer
Simple Introduction

오늘날 object detection은 매우 높은 성능과 정확도를 보인다.
또 실제 우리 현실에서 여러 방면에서 이용이 되고, 우리가 느끼지 못할 정도로 광범위하게 퍼져있다.
Object Detection은 원래 CNN으로 많이 task를 만들고 작업했는데,
Transformers의 등장으로, 이제 vision분야에서는 transformer가 압도적인 성능과 함께 자리를 잡았다.
그렇다면 Transformer를 이용해서 어떻게 object detection을 수행할 수 있을까?
같이 살펴보자!
Background Knowledge: Vision Transformer
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
DETR은 image path와 Transformer를 이용하는 구조를 가지고 있기 때문에, 반드시 ViT에 대해서 알고 계셔야 합니다!
*해당 논문 리뷰 글은 ViT에 대해서 알고 있다는 가정 하에 이루어집니다.
Method
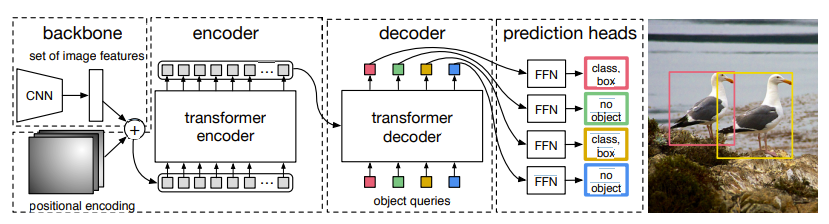
DETR은 매우 간단한 과정으로 이루어져 있다
1. CNN을 통해서 image feature를 만든다.
2. Image feature에 positional encoding을 적용시킨 후, 일정 patch로 flatten한다.
3. Patch를 각각 transformer encoder에서 넣어서 embedding을 학습한다
4. Encoder에서 나온 embedding을 활용해서 decoder를 학습한다.
- 이때 Object queries가 decoder의 input으로 들어간다.
5. Decoder의 output에 FFN을 적용해서 class와 box를 출력한다.
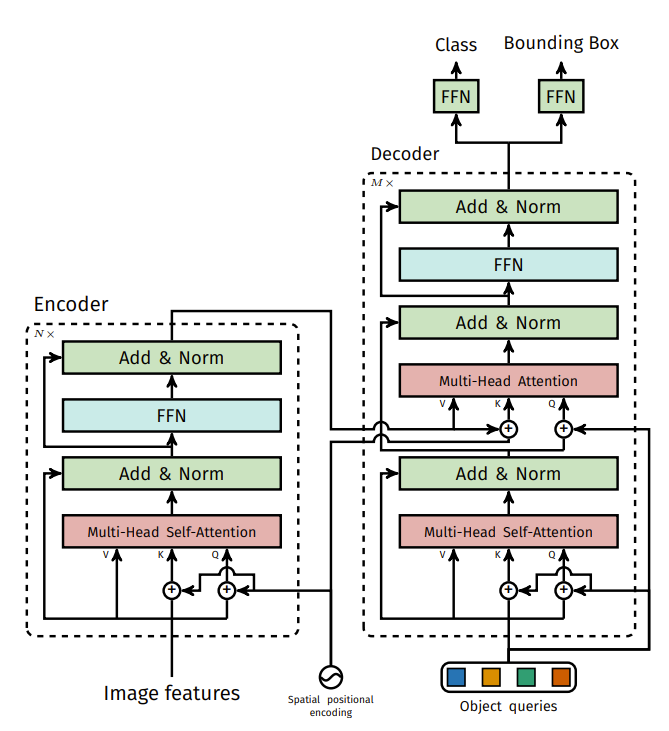
+) encoder와 decoder의 자세한 구조는 다음과 같다.
+) 기존 Transformer의 구조를 가져왔다고 생각하면 편하다.

+) DETR의 encoder가 객체가 어디있는지 잘 표현해줄 수 있는 embeddings을 만든다는 사실을 알 수 있다.
1. Object queries
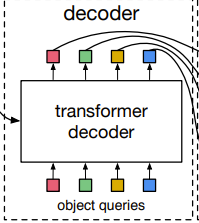
Object queries에 대해서 설명을 하도록 하겠습니다.
저도 처음에 DETR을 할 때, Object queries가 무엇인지 정확하게 몰라서 모델을 이해하는데 어려움을 겪었습니다..ㅎㅎ
Object queries는 일단 small fixed number of learned positional embeddings이라고 표현이 가능합니다.
이 Object queries는 encoder에서 생성된 N개의 embedding 개수와 동일하게 N개를 생성하고, encoder embeddings와 함께 decoder로 들어가서 학습합니다.
Decoder로 통해서 학습된 object queries를 마지막 FFN layer에 넣어서 No class or class, bounding box coordinates 좌표에 대한 정보를 출력하게 됩니다. 결국 N개의 predictions 결과가 나오게 됩니다.
미리 사전에 몇개의 object가 최대로 나올 수 있는지에 대해서 미리 정의가 되어있는 임의의 patch 벡터 값을 queries라고 생각하면 편합니다!
그래서 그 queries를 decoder를 통해서 learnable하게 해서 최종적으로 각각 queries가 object를 표현할 수 있도록 만들어 주는 것이 DETR의 목적이 되는 것입니다.

+) N은 일단 기본적으로 ground truth set의 object label보다 많이 설정합니다.
- 2023.01.05 Kyujinpy 작성.



