*NeRF-Art 논문 리뷰 글입니다! 궁금하신 점이 있다면 댓글로 남겨주세요!
NeRF-Art paper: [2212.08070] NeRF-Art: Text-Driven Neural Radiance Fields Stylization (arxiv.org)
NeRF-Art: Text-Driven Neural Radiance Fields Stylization
As a powerful representation of 3D scenes, the neural radiance field (NeRF) enables high-quality novel view synthesis from multi-view images. Stylizing NeRF, however, remains challenging, especially on simulating a text-guided style with both the appearanc
arxiv.org
NeRF-Art github: GitHub - cassiePython/NeRF-Art: NeRF-Art: Text-Driven Neural Radiance Fields Stylization
GitHub - cassiePython/NeRF-Art: NeRF-Art: Text-Driven Neural Radiance Fields Stylization
NeRF-Art: Text-Driven Neural Radiance Fields Stylization - GitHub - cassiePython/NeRF-Art: NeRF-Art: Text-Driven Neural Radiance Fields Stylization
github.com
Contents
2. Background Knowledge: NeRF, CLIP
- Global and local contrastive loss
Simple Introduction

기존의 ray를 활용하여 3D rendering을 짧은 시간 안에 완료해주는 NeRF 모델과 후속연구들은 엄청난 Vision 분야에 폭풍을 몰아오고 있다.
하지만 vision분야가 그렇듯(?), NeRF에 다른 분야를 접목하는 시도가 매우 늘어났고, 그 중 가장 대표적인 text를 이용한 stylization이다.
기존의 일반적인 2D image stylization이 아니라, 3D rendering view에서 다양한 stylization을 표현할 수 있게 하였는데, 과연 어떻게 stylization을 하였고, 어떻게 모델 pipeline을 구성했는지 같이 살펴보자!
Background Knowledge: NeRF, CLIP
NeRF 논문 리뷰: https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
CLIP 논문 리뷰: https://kyujinpy.tistory.com/47
[CLIP 논문 리뷰] - Learning Transferable Visual Models From Natural Language Supervision
*CLIP 논문 리뷰를 위한 글입니다. 질문이 있다면 댓글로 남겨주시길 바랍니다! CLIP paper: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org) Learning Transferable Visual Models From Natu
kyujinpy.tistory.com
NeRF-Art는 text input과 ray rendering을 같이 이용하여 기존의 image에 새로운 stylization을 추가하는 모델이다.
따라서, text를 vision분야에서 비교할 수 있게 만들어주는 CLIP과 3D rendering을 진행하는 기본적인 모델 NeRF의 개념에 대해서 이해를 하여야 이해가 가능하다.
*해당 논문 리뷰는 CLIP과 NeRF를 이해하고 있다는 가정하에 이루어집니다.
Method
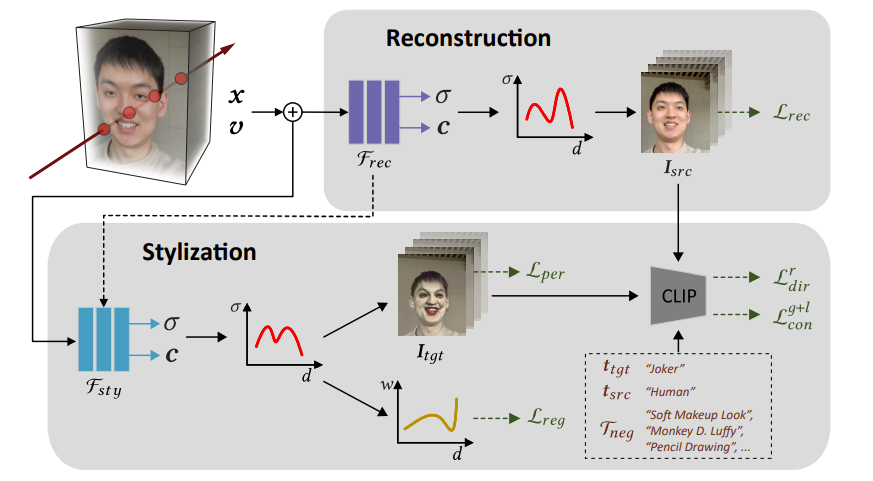
모델 구조를 step by step으로 살펴보자!
1. 일단 처음에 기본적인 NeRF를 학습한다.
- 먼저 pre training을 시킨다.
2. Stylization 단계에서는 기존의 NeRF 모형 Frec를 Fsty로 학습되는 과정을 걸친다.
- 이때 stylization이 되는 것은 text prompt의 guide에 따라서 학습이 진행된다.
3. Stylization 단계에서 나온 rendering rgb map과 stylization을 시켜주는 text prompt간의 유사도를 CLIP를 통해서 계산해서 loss function을 계산한다.
+) Network의 baseline을 NeRF가 아닌 VolSDF, Neus 모델을 이용하였다.
+) 위의 두 모델 전부 NeRF와 같은 개념으로 3D rendering을 하지만, 다른 방법을 이용하여 NeRF보다 좋은 성능을 보여준다.
+) 관심있으면 찾아보길 추천하고, 추후에 논문리뷰도 한번 진행해보겠습니다.
1. CLIP-Guided losses

CLIP-Guidede stylization loss에는 정말 여러 종류가 있다.
1-1. Absolute directional loss
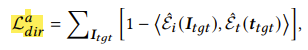
이것은 stylizaiton이 적용된 rendering rgb map과 text prompt간의 embedding 유사도를 의미한다.
유사도는 cosine similarity를 이용한다.
1-2. Relative directional loss

이것은 stylization이 적용된 rgb map과 original rgb map의 차이와 style text prompt와 original text prompt의 차이를 계산 한 후, 만들어진 2개의 embedding에 대하여 유사도를 계산하는 것이다.
예를 들어서,
ttgt: 'joker'이고, tsrc: 'human'으로 설정했을 때, original과 style 이미지 간의 차이가 text간의 차이와 유사해야 학습이 잘 된 것이라고 판단할 수 있다.
1-3. Global and local contrastive loss

Global과 local에서 loss를 계산하는 것인데, 일단 기본적인 식은 위에와 같다.


위에 v, v+, v-에 각각 Itgt, ttgt, tneg를 대입하면 Global contrastive loss이고,
만약 Ptgt, ttgt, tneg를 대입하면 Local contrastive loss이다.
좀 더 구체적으로 설명하면,
tneg는 위의 tsrc와 다르게 human이 아니라, 'animal', 'dog', 'flower', 'sun', 'pixar' 등등의 다른 label을 의미하는데, 이 모든 라벨을 이용하는 것이 아니라 negative sample 집합 Tneg에서 sampling을 진행해서 선택하게 된다.
그리고 Ptgt는 이미지의 Patch를 의미한다.
그래서 image 전체에 대한 embedding을 계산한 것이 아닌, patch에 대한 embedding을 계산한 것이다.
위의 3가지 loss function 소개에 대한 사진에서 (c)를 보면 좀 더 이해가 잘 될 수 있다!
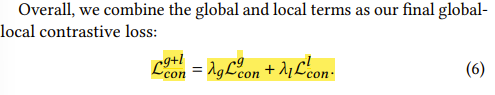
최종적인 Global and contrastive loss는 위의 수식과 같다!
2. Weight Regularization loss

.Weight Regularizaiton loss의 경우 density에 대한 geometry 정보를 유지하게 위해서 생겨났다.
이 loss에 보면 r은 이제 Itgt에서 임의로 뽑은 ray를 의미하고, w는 i, j번째에서 color를 생성할 때 곱하는 weight를 의미한다.
3. Perceptual loss

Perceptual loss는 VGG layer를 이용해서 얻은 각각의 embeddings으로 Itgt와 Isrc간의 euclidean distance를 계산한 loss를 의미한다.
이 loss는 기존에 있는 content를 어느정도 보존하기 위해서 만들어진 loss function으로 일종의 regularization 역할을 한다.

+) 최종적인 loss function의 식은 다음과 같다.
Result

1. Style change 뿐만 아니라, geometry 형상의 모습도 잘 변화시킨다.

2. 기존의 여러 SOTA 모델들과 비교했을 때, 자연스럽게 style를 changing 하면서 3D reconstruction을 한다.

3. 몇몇 케이스에서 Ambigulty한 결과가 나오거나, words의 의미가 잘 표현되지 않으면 결과가 잘 안 나오기도 한다는 점이 한계점이다.
(만약 end-to-end로 학습할 수 있는 방법이 있다면 더 멋지지(?) 않을까..?)
- 2022.01.04 Kyujinpy 작성.



