*Barlow Twins 논문 리뷰를 코드와 같이 분석한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요.
Barlow Twins paper: https://arxiv.org/abs/2103.03230
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue wi
arxiv.org
Barlow Twins github: https://github.com/facebookresearch/barlowtwins
GitHub - facebookresearch/barlowtwins: PyTorch implementation of Barlow Twins.
PyTorch implementation of Barlow Twins. Contribute to facebookresearch/barlowtwins development by creating an account on GitHub.
github.com
Contents
Simple Introduction

Simsiam 논문 리뷰: https://kyujinpy.tistory.com/45
[Simsiam 논문 리뷰] - Exploring Simple Siamese Representation Learning
*Simsiam 논문 리뷰를 코드와 같이 분석한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요. *Simsiam는 Non-contrastive learning입니다. Simsiam paper: https://arxiv.org/abs/2011
kyujinpy.tistory.com
기존의 Simsiam은 momentum encoder를 없애고, stop gradient가 학습에 큰 도움이 된다는 것을 증명하는데 큰 공헌을 하였다.
그러나 Simsiam처럼 asymmetric network의 구조는 downstream task에 적용하기가 까다로운 점이 있다.
하지만 asymmetric network는 positive sample만 이용했을 때 생기는 collapse problem을 해결한다는 장점이 있었다.
그래서 Simsiam의 특성을 모두 가져가면서, symmetric한 구조를 만들 수는 없는가에 대해서 사람들이 생각했고,
Barlow Twins는 symmetric한 구조로 collapse problem도 해결한 구조를 제시했다.
*해당 논문 리뷰는 Simsiam의 개념에 대해서 알고 있다고 가정하고 진행됩니다.
Method

Step by step으로 구조를 살펴보자.
1. 같은 데이터셋 x에 대해서 Augmentation을 통해서 두개의 batch input을 만든다.
2. Symmetric한 구조를 가진 network에 넣는다.
- Encoder와 Projector에 넣는다.
- 보통 Encoder는 ResNet-50이고, Projector는 MLP로 구성되어 있다.
3. Projector에서 나온 두 개의 Embeddings값에 각각 BN(batch normalization)을 적용한다.
- 여기서 특이한 점은, feature dimension 방향이 아닌, batch 방향으로 적용한다. (밑에서 자세히 언급)
4. Embeddings을 가지고 Cross-correlation Matrix를 구한다.
5. Identitiy matrix와의 비교를 통해서 loss function을 계산하고 학습을 진행한다. (loss function은 밑에서 자세히 언급)
- Stop gradient는 없기 때문에 양방향 backpropagation이다.
1. Loss Function


Loss function 중 먼저 C를 살펴보겠다.
C는 Cross-Correlation matrix를 만드는 과정으로, 상관관계를 각 feature 마다의 상관관계를 구하는 것이다.
그리고 위의 matrix를 구하기 전에 Batch Normalization을 batch의 방향, 행 방향으로 적용하는데 이는 각 feature column마다 의미를 담고 있다고 생각하기 때문이다.
예를 들어 x라는 image 50개가 각각 256개의 feature dimension으로 나왔다고 생각해보자.
그러면 (50, 256)인 형태의 embedding 인데, Barlow Twins는 각 feature column 마다 image를 설명하는 정보가 들어있다고 생각한다.
만약 '사자'라는 image에서 만들어진 embedding의 첫번째 column이 '육식 동물이다' 라는 것을 설명하고 있다면, 두번째 column 정보는 '이빨이 있다', 세번째는 '털이 있다' 등등을 representation하고 있는 것이다.
따라서 column에 대해서 normalization을 진행을 해서 두 개의 embedding vector를 동일선상에서 비교할 수 있게 된다.
그리고 두 개의 embedding을 dot-product를 통해서 (256, 256) 형태의 Cross-Correlation matrix를 만든다.
즉 이 matrix가 최적화 될려면, 상관관계의 성질에 의해서 diagonal term이 1이 되고, 나머지 off-diagonal term은 0이 되어야 하므로, identity matrix와의 loss function계산을 진행하는 것이다.
그래서 loss function, LBT를 최종적으로 정리하면
invariance term은 diagonal에 대한 loss term이고, redundancy reduction term은 off-diagonal에 대한 loss term이 된다.

따라서, 만약 두번째 column과 다섯번째 column이 image에 대해서 같은 정보를 갖고 있는 항목이라면, 이것을 redundancy reduction term을 통해서 중복되는 정보가 사라지고, 새로운 정보를 갖는 column으로 대체될 수 있도록 만들어 준다는 것이 Barlow Twins 중요한 목적이다!!!
+) 기존의 방식과 다르게, feature dimension 방향으로 normalization을 진행하지 않고, batch 방향으로 진행하는 것에 있어서 익숙하지 않을 수 있다.
+) 만약 이해가 안된다면 댓글로 남겨주세요..!
+) Redundancy reduction term을 이용해서 embedding vector에서 중복되는 정보가 없도록 만들어주기 때문에 projection layer의 dimension이 클수록 성능이 올라간다는 것을 논문에서 증명했다.
Ablations

1. Barlow Twins는 Batch size에 민감하지 않다.
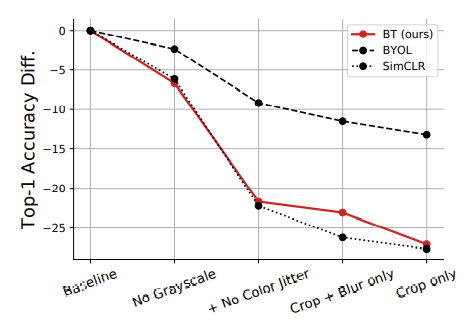
2. Augmentation method에서는 SimCLR보다 민감하다. (한계점)

3. Projection layer의 hidden dimension이 높을 수록 성능이 올라간다.
- 많은 정보를 담을 수 있기 때문이다.

4. Asymmetric한 구조를 만들어도, collapse problem이 일어나진 않는다.
- 2023.01.02 Kyujinpy 작성.



