*BYOL 논문 리뷰를 코드와 같이 분석한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요.
*BYOL는 Non-contrastive learning입니다.
BYOL paper: https://arxiv.org/abs/2006.07733
Bootstrap your own latent: A new approach to self-supervised Learning
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view o
arxiv.org
BYOL github: https://github.com/sthalles/PyTorch-BYOL
GitHub - sthalles/PyTorch-BYOL: PyTorch implementation of Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
PyTorch implementation of Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning - GitHub - sthalles/PyTorch-BYOL: PyTorch implementation of Bootstrap Your Own Latent: A New Approach...
github.com
Contents
- Online Network, Target Network
Simple Introduction

BYOL의 가장 큰 장점은, negative sample 없이 positive sample만 이용해서 supervised learning과 comparable한 성능을 보여준다는 것이다.
이렇게, positive sample만 이용한 것을 Non-contrastive learning이라고 한다!
어떻게 이런 성능을 보일 수 있을까요?
Negative sample이 없이 positive sample하고만 비교하면 과연 학습이 될까?
이러한 의문점을 해결해보자!
(Background Knowledge: MoCo)
MoCo 논문 리뷰: https://kyujinpy.tistory.com/40
[MoCo 논문 리뷰] - Momentum Contrast for Unsupervised Visual Representation Learning
*MoCo 논문 리뷰를 코드와 같이 분석한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요. *SSL(Self-Supervised-Learning) 중 contrastive learning을 위주로 다룹니다! Moco pap
kyujinpy.tistory.com
MoCo, SimCLR과 같은 Contrastive learning의 한계점은 negative sample이 필요하다는 것이였다.
바로 이러한 문제점을 해결했고, momentum encoder를 이용했기 때문에 MoCo를 미리 알고 오셔야 이해가 편하게 되실꺼라고 생각이 듭니다.
*해당 논문 리뷰는 MoCo의 개념을 알고 있다는 가정하에 진행됩니다!
Method

BYOL를 간단한 overview로 살펴보자.
일단 positive sample만 이용하는 점을 유의하자!
두 개의 network로 이루어져 있고, x1, x2가 각각의 network로 들어간다.
위의 network는 online network, 아래는 target network이다.
그리고 특이한 점이 target network에는 마지막 prediciton layer가 없다.
그리고 마지막 target network에 sg(stop gradient)가 적용되어 있다.
따라서 구조는 MoCo와 매우 유사하다.
좀 더 자세히 확인해보자!
1. Online Network, Target Network
Step by step으로 모델의 구조를 설명해보겠다.
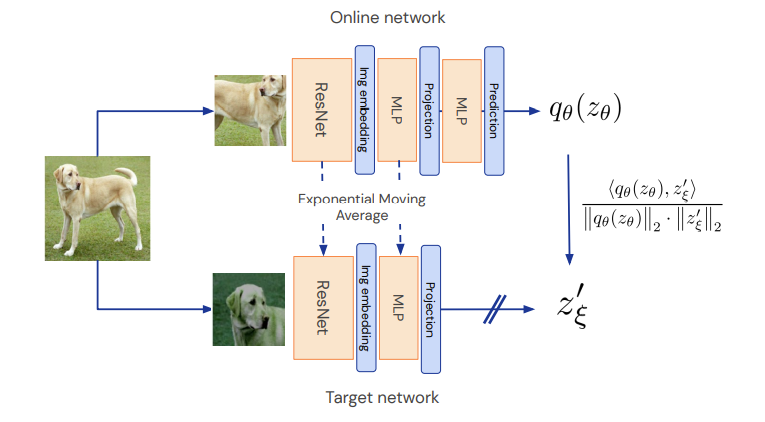
1. x에 대해서 augmentation을 진행하여 x1, x2를 만들어 낸다.
2. 각각의 x1, x2를 online network(upper), target network(lower)에 넣는다.
3. f(x)에 넣어서, representation을 만들어 낸다. (embedding 제작)
- 여기서 f(x)는 encoder로, ResNet-50을 보통 이용한다.
- Target network에서는 momentum encoder가 된다.
4. Projection layer을 이용해서 augmentation에 대한 값들을 좌표상에 위치시킨다. (기하학적 의미; 밑에서 설명)
5. online network에서는 prediction layer를 통해서 final embedding을 생성하고, target network에서는 stop gradient를 적용해서 모델이 단방향으로 학습될 수 있도록 만들어 준다.
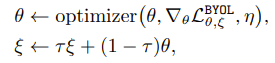
6. Backpropagation을 online network만 적용하고, target network는 MoCo와 동일한 방식으로 momentum update를 진행한다.
+) positive sample만 이용하면은 shortcut 학습이 되기 때문에, collapsing problem이 있었다.
+) 이것을 해결하기 위해 BYOL은 asymmetric model network(distillation)와 momentum update를 이용하여 문제를 해결하였다.
2. Loss function
기존의 Contrastive learning의 경우 InfoNCE를 이용했는데,
Non-Contrastive learning의 경우에는 InfoNCE를 이용하지 않는다.
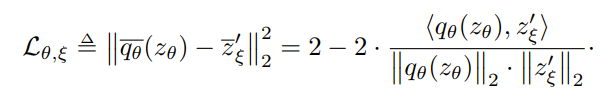
BYOL에서는 Negative Cosine similarity와 L2 loss를 함께 이용한 형태를 활용하였다.
이 loss function은 online network의 prediciton layer에서 나온 값과 target network의 projection layer에서 나온 값의 negative cosine similarity를 계산하는 방식으로 진행된다.

그리고 한가지 중요한 점으로 symmetric loss function을 이용했다는 점이다.
위의 이미지 처럼, 두 개의 augmentation set을 각각 서로 online network, target network에 넣어서 각각의 loss를 더해주는 형태를 활용했다.

+) 위에서 말한 기하학적 의미에 대해서 설명하면, target network의 projection layer를 통해서 augmentation에 대한 embedding들이 임의의 space위에 mapping이 된다고 생각해보자.
+) 이때, online network의 prediciton layer를 통해서 나온 embedding값은 target network의 projection embedding들의 평균값에 가까워져야 loss function이 최소화가 된다.
Experiment
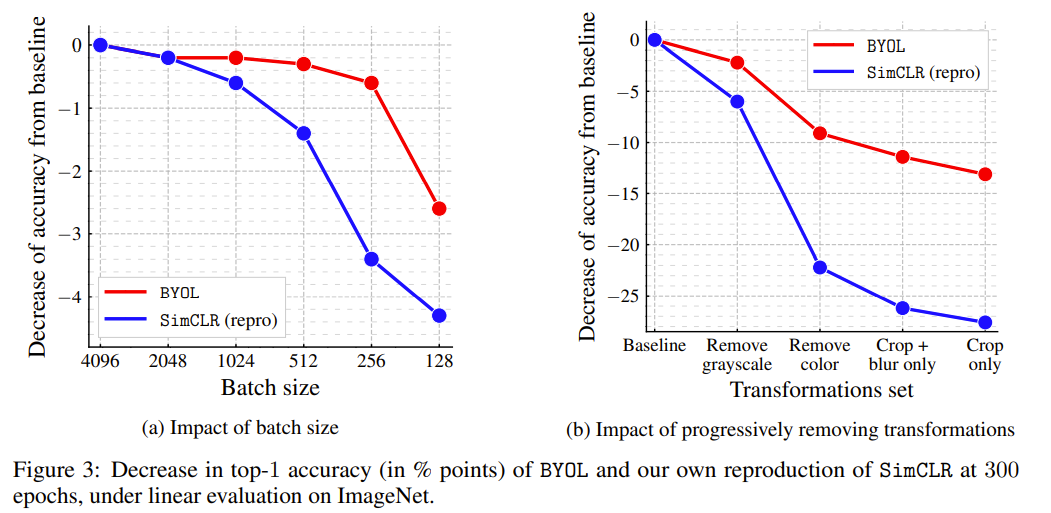
1. BYOL은 기존의 contrastive learning과 다르게 negative sample에 대한 영향이 없으므로, batch size에 대해서 어느정도 robust한 성능을 보였다.

2. 대부분 SOTA를 달성하였고, 기존의 supervised learning과 comparable한 성능을 보인다.
- 2023.01.01 Kyujinpy 작성.



