*SimCLR 논문 리뷰를 위한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요.
*SSL(Self-Supervised-Learning) 중 contrastive learning을 위주로 다룹니다!
*해당 글에서는 Proxy task 논문, Exemplar, Jigsaw Puzzle에 대한 간단한 설명도 포함되어 있습니다.
SimCLR paper: [2002.05709] A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org)
A Simple Framework for Contrastive Learning of Visual Representations
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to under
arxiv.org
SimCLR github: GitHub - sthalles/SimCLR: PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
GitHub - sthalles/SimCLR: PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representation
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations - GitHub - sthalles/SimCLR: PyTorch implementation of SimCLR: A Simple Framework for Contrast...
github.com
Contents
2. Background Knowledge: Self-Supervised-Learning, Contrastive Learning
Simple Introduction
우리가 얘기할 SimCLR을 얘기하기전에 그 전에 Self-Supervised-Learning(SSL)은 어떤식으로 진행되었는지 간단히 알아보자.
초반에 제안된 SSL의 방법은 Generative Learning과 Proxy task이다.
1. Generative Learning

Autoencoder와 같이 Encoder와 Decoder로 구성되어 있는 모델로 SSL은 하는 것이 Generative Learning이다.
이 Generative Leanring은 Encoder와 Decoder 둘 다 학습해야하기 때문에 computational cost가 크다는 것이 단점이였다.
또한 SSL 모델을 Image classification과 같은 학습에 이용될 때에는 Decoder의 의미가 무색해졌다.
2. Proxy task
Proxy task는 Generative learning과 다르게 Decoder의 구조가 없고, 미리 사용자가 label을 만들어서 작업을 수행하는 것이다.
하지만 여기서 여러 문제점이 있는데, 대표적으로 "사용자가 만든 label이 기존보다 과연 고차원적인 정보를 만드는데 도움이 될까?"라는 점이였다.
Proxy task의 대표적인 모델인 Exemplar와 Jigsaw Puzzle에 대해서 언급을 하고 넘어가겠다.
2-1. Exemplar
Exemplar의 방법론은 매우 간단하다.
만약 이미지가 50만장이 있다면, 각각의 이미지를 하나의 label로 생각해서 총 50만개의 label을 사용자가 만든다.
그 각각의 이미지마다 Random Augmentation을 만들어서, 하나의 집단을 original image의 label에 전부 할당한다.
위의 과정을 모델이 학습시킨다.
2-2. Jigsaw Puzzle
Jigsaw Puzzle는 총 9개의 patch들을 서로 섞어서 그 순서를 맞추는 문제이다.
이때 9! = 362,880개의 엄청난 가짓수가 있기 때문에 각 이미지당 69개만 활용해서 이용한다.
즉, 각 이미지 patch들이 몇번째 이미지인지 해결하는 Pretext task인데, 이러한 puzzle를 풀면서 학습된 모델이 Image classificaiton이나 Object Detection에 좋다고 논문의 저자들은 얘기합니다.
하지만 이런 Proxy task의 경우 사람이 직접 labeling을 만들어야 한다는 것이 가장 큰 문제점이 되었다.
Proxy task를 통해서 학습된 모델이 과연 기존의 이미지보다 고차원적인 information을 갖는다고 말할 수 있을지 의문이 있었기 때문에 Contrastive learning이 나오게 되었다.
여기까지 설명을 들었다면, 여러분들은 의문점이 들 수도 있다.
가장 근본적인 질문
>> "그래서 SSL은 어떻게 이용되는 건데요? 학습하는 건 알겠는데, 이게 어떻게 문제를 해결하는데 도움이 되는거죠?"
밑에서 이 부분에 대해서 명확하게 설명을 해드리겠습니다.
Background Knowledge: Self-Supervised-Learning, Contrastive Learning
SSL이 어떻게 적용되는지 한번 자세히 알아봅시다.
일단 용어를 간단히 정리하면,
Pretext task: Self-Supervised-Learning을 학습하기 위해서, 사용자가 만든 문제.
Downstream task: Self-Supervised-Learning을 적용해서 풀 문제.
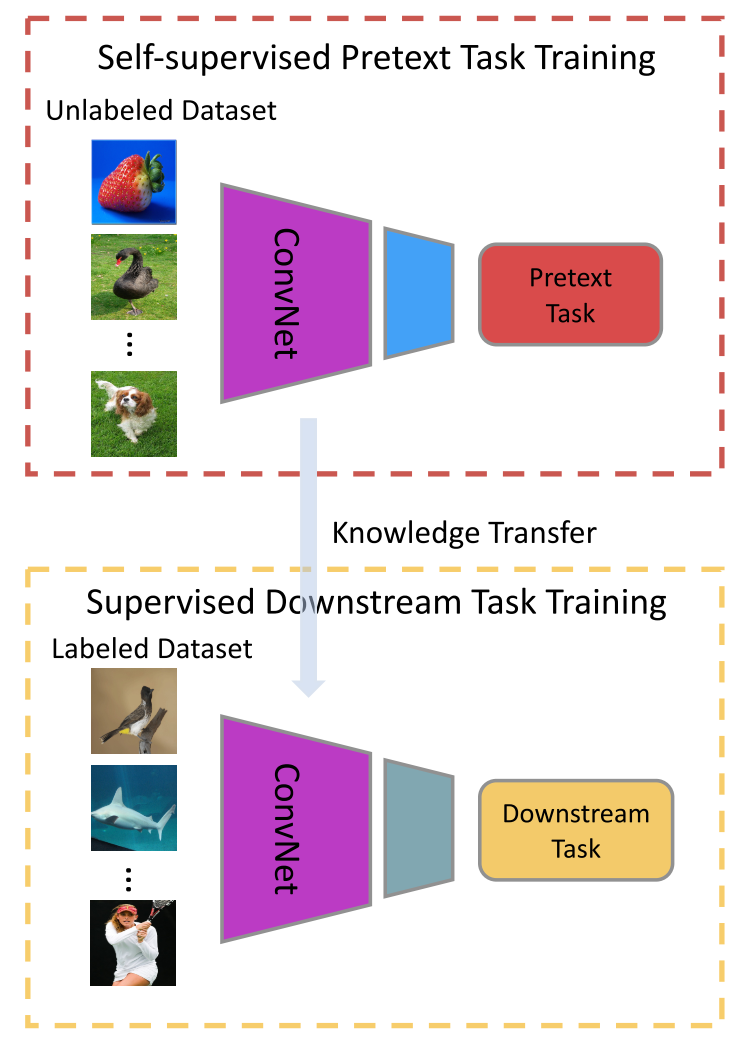
1. SSL은 처음에 label이 없는 데이터셋을 가지고, 학습을 진행합니다. (Pretext task)
- 예를 들어서, 위의 Exemplar처럼, 각 image에 대한 label를 사용자가 임의로 만들어서 학습되도록 합니다.
- 여기서 나오는 output은 보통 embedding 형태로, 실제 이미지와 output간의 similarity를 계산해서 판단할 수도 있다.
2. SSL을 통해 학습한 모델을 기존의 모델에 적용해서 평가합니다. (Downstream task에 적용)
- 적용방법에는 크게 3가지가 있습니다. Linear evaluation, Semi Supervised Learning, Transfer Learning입니다.
- 예를 들어서 ImageNet을 활용해서 Image classification을 진행한다고 해봅시다.
- Linear evaluation: Pretext task를 통해서 학습했던 모델의 weights를 freeze 시키고 난 후, 뒤에 FC layer를 붙여서 fine-tunning을 진행합니다.
- Semi Supervised Learning: 데이터셋의 label을 1%~10% 사이만 이용해서 학습시키는 것입니다.
- Transfer learning: ImageNet으로 학습한 모델을 transfer-learning 시켜서 다른 dataset(CIFAR 등등)을 평가합니다.
Contrastive Learning이란?
1. No decoder
2. Contrastive loss(InfoNCE loss)
3. Positive와 Negative sample를 비교하면서 학습을 진행.
4. Augmentation 활용
이제 조금 이해가 되셨나요?
SimCLR을 설명하면서 평가하는 방법을 다시 들으면 이해가 완벽하게 되실 것으로 생각됩니다.
Method

SimCLR의 구조는 위와 같다.
1. X라는 데이터셋을 각각 2번 augmentation 시켜서 xi, xj를 얻는다.
2. 각각 xi와 xj에 f(x)를 적용한다.
- f(x)는 보통 ResNet-50이다.
3. 그 다음 Projection head라고 불리는 g(x)를 적용한다.

4. Projection head에서 나온 embedding을 값을 InfoNCE(Contrastive loss)를 이용해서 서로의 유사도를 계산해서 loss function을 계산한다.
- 여기서 보면 분자는 positive sample에 대한 서로의 유사도이고, 분모는 전체 데이터 셋
(positive sample + negative sample)에 대한 유사도의 총합을 이용해서 probability를 계산한다.
- 실제 코드에서는 Cross_Entropy loss를 이용한다. (Cross_Entropy의 x에 simiarity를 대입한 것과 같음)

+) Linear Evaluation에 대한 성능평가 인데, 단일 augmentation을 이용했을 때 성능이 가장 좋지 않았다.
+) Color + Crop 조합을 이용했을 때 가장 성능이 좋다는 것을 확인할 수 있다.

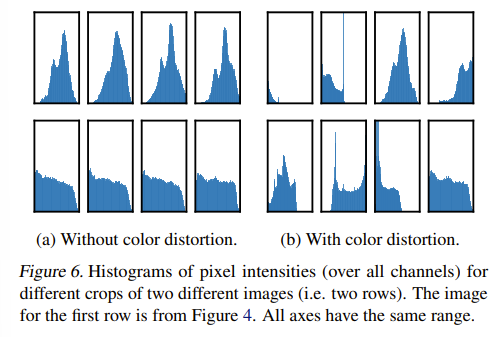
+) Color distortion을 사용해야, deep learning의 shortcut학습을 방지할 수 있음을 증명했다.
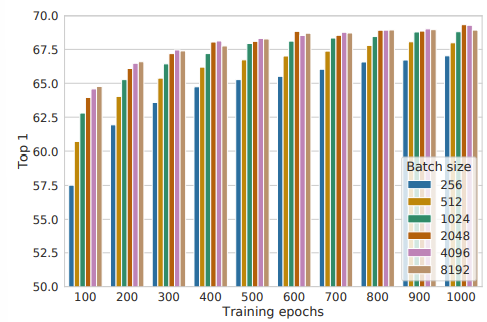
+) Training Epoch와 Batch Size가 클수록 성능이 좋다는 것을 확인하였다.
+) 이 부분이 바로 한계점과 이어진다.
Limitations
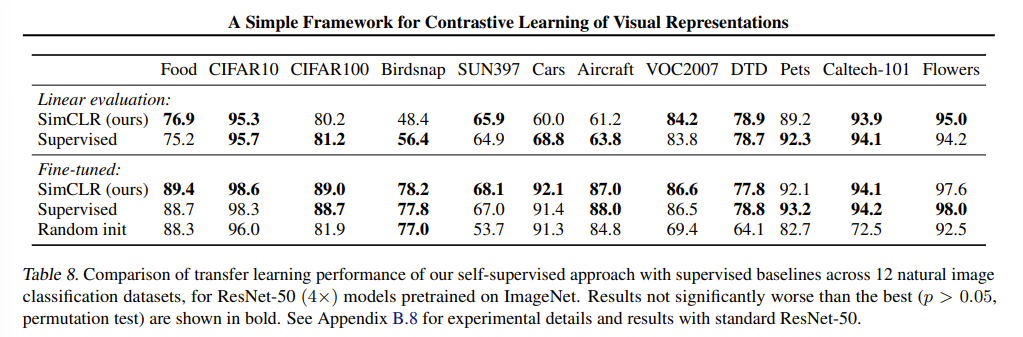
SimCLR을 사용하고 나서, 기존의 모델에 적용했을 때 성능이 기존의 supervised learning 보다 좋다는 것을 알 수 있다.
다만 한계점은, 앞에서 언급한 것처럼, batch size가 커야 성능이 높아진다는 것이다.
이는 computational cost에 대한 한계가 있다는 것이고, negative sample에 대한 의존성이 높다는 것을 알 수 있다.
또한 SSL 특성상 많은 데이터셋을 이용하기 때문에 보통 multi-GPU로 학습하는데, computationl cost problem이 있다는 것은 명확한 한계점이다.
- 2022.12.31 kyujinpy 작성.



