*UNETR++ 논문 리뷰를 위한 글입니다. 질문이 있다면 댓글로 남겨주시길 바랍니다!
UNETR++ paper: [2212.04497] UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation (arxiv.org)
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
Owing to the success of transformer models, recent works study their applicability in 3D medical segmentation tasks. Within the transformer models, the self-attention mechanism is one of the main building blocks that strives to capture long-range dependenc
arxiv.org
UNETR++ github: GitHub - Amshaker/unetr_plus_plus: UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
GitHub - Amshaker/unetr_plus_plus: UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation - GitHub - Amshaker/unetr_plus_plus: UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
github.com
Contents
2. Background Knowledge: UNETR
- Efficient Paired-Attention Block
Simple Introduction


Background Knowledge: UNETR
UNETR 논문 리뷰: https://kyujinpy.tistory.com/37
[UNETR 논문 리뷰] - UNETR: Transformers for 3D Medical Image Segmentation
*UNETR 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! UNETR paper: [2103.10504] UNETR: Transformers for 3D Medical Image Segmentation (arxiv.org) UNETR: Transformers for 3D Medical Image Segmentation Fu
kyujinpy.tistory.com
*해당 논문 리뷰는 UNETR의 기본 개념을 알고 있다는 가정하에 진행됩니다! UNETR에서 한 층 진화된 구조인 만큼 숙지하시면 도움이 됩니다!
Method

UNETR++의 간단한 구조이다.
구조를 보면 UNETR과 매우 유사한데, 다만 중간에 EPA라는 것이 보인다.
EPA는 Efficient Paired-Attention Block의 약자로, 논문의 저자들이 새롭게 제시한 attention network이다.
즉, UNETR++는 EPA block을 이용해서 기존의 UNETR에 있었던 Transformer block와 CNN을 모두 대체하였다.
그러면 EPA block을 자세히 알아보자.
1. Efficient Paired-Attention (EPA)
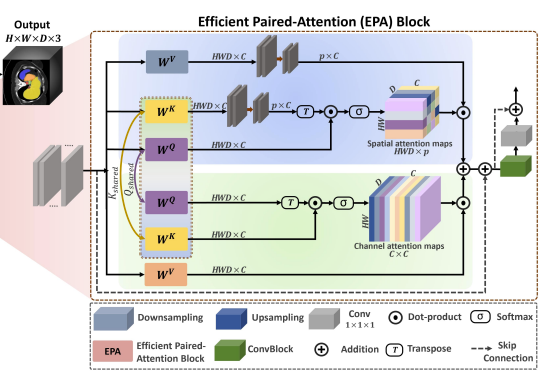
EPA block은 안에 Transformer 구조처럼, Attention mechanism을 이용하였는데, Multi-head-attention을 이용하진 않았다.

EPA를 구성하는 간단한 식을 살펴보면 Xs와 Xc가 있다.
SA는 spatial attention module이고, CA는 channel attention module이다.
그리고 수식을 구성하는 Q, K, V를 보면 Q, K는 spatial, channel attention에서 서로 공유되는 matrix이고, V는 공유되지 않고 개별적으로 있다.
즉, 기존의 attention과 다르게 Qshared, Kshared, Vspatial, Vchannel으로 matrix가 생성된다.
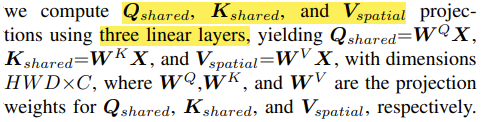

+) Qshared, Kshared, Vspatial, Vchannel는 X input에 각각의 가중치가 곱해진 형태이다.
2. Spatial attention
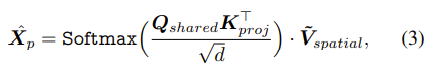
Spatial attention의 수식은 위와 같이 표현이 된다.
Step by step으로 자세히 설명하면,
1. Kshared, Vspatial를 layer를 통해서 HWD X C dimensition에서 p X C dimension으로 projection 시킨다.
2. p X C 형태의 Kshared를 Transpose 시킨 후 Cshared와 dot-product 연산을 통해서 Spatial attention map을 만든다.
3. 차원 d로 normalization을 시켜주고 Softmax를 적용한다.
4. Sptial attention map과 Vspatial을 최종적으로 dot-product를 하여 HWD X C shape을 가진 final spatial attention map을 만든다.
+) 2번의 과정에서 나오는 Sptial attention map의 경우 shape이 HWD X p이다.
+) 왜나하면, HWD X C ⊙ C X p 형태의 연산이기 때문이다.
3. Channel attention

Channel attention의 수식은 위와 같이 표현이 된다.
Step by step으로 자세히 설명하면,
1. Qshared를 Transpose를 시킨 후 Kshared와 dot-product를 진행하여 channel attention map을 만든다.
2. 차원 d로 normalization을 진행 한 후, Softmax를 적용한다.
3. Vchannel과 Channel attention map을 최종적으로 dot-product를 하여 HWD X C shape를 가진 final channel attention map을 만든다.
+) 1번의 과정에서 나오는 channel attention map의 shape은 C X C이다.
+) 왜냐하면, C X HWD ⊙ HWD X C 형태의 연산이기 때문이다.
4. Summary
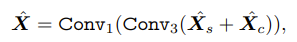
위에서 만들어진 spatial attention map, channel attention map을 서로 sum을 한 다음에 두 개의 convolution layers에 넣어준다.
이러한 과정을 걸치는 EPA block과 3D-UNet을 함께 이용한 UNETR++의 성능은 여러 segmentation 분야에서 이용되고 있던 기존의 모델들의 성능을 뛰어 넘었다.

+) Conv1은 1 x 1 x 1이고, Conv3는 3 x 3 x 3 형식의 layer이다.
- 2022.12.31 kyujinpy 작성.



