* 해당 글은 논문 리뷰를 위한 글이고, 궁금하신 점이 있다면 댓글로 남겨주세요!
FissureNet paper: FissureNet: A Deep Learning Approach For Pulmonary Fissure Detection in CT Images - PMC (nih.gov)
FissureNet: A Deep Learning Approach For Pulmonary Fissure Detection in CT Images
Pulmonary fissure detection in computed tomography (CT) is a critical component for automatic lobar segmentation. The majority of fissure detection methods use feature descriptors that are hand-crafted, low-level, and have local spatial extent. The design
www.ncbi.nlm.nih.gov
Contents
2. Background Knowledge: 3D U-Net
Simple Introduction


Lung에 있는 Fissure를 예측하기 위한 움직임은 계속해서 진행되어 왔다.
Fissure는 하지만 CT 상에서도 매우 희미하게 보이고, 직접 manually하게 labeling하는 작업은 극한의 노동이며, 특히 right lung에 있는 horizontal fissure를 segmentation하는 작업은 쉽지 않다.
그리고 머신러닝을 이용한 fissure segmentation의 성능도 보통 정도였고, 일상에 적용되기에는 아직 성능이 부족했다.
FissureNet segmentation을 아마(?) 처음으로 딥러닝으로 예측한 논문이고, 이 논문을 토대로 앞으로 Transformer와 같은 모델들이 이 분야에 적용되면서 좋은 성능을 가진 모델들이 나오길 개인적으로 소망한다.

+) 위의 사진을 보면 Fissure가 무엇인지 쉽게 이해할 수 있을 것이다.
+) Fissure라는 것은, lung의 region을 구분해주는 선으로, fissure를 기준으로 lung의 lobe가 결정된다.
+) 오른쪽은 fissure가 2개, 왼쪽은 fissure가 1개라는 점을 유의깊게 보자!
Background Knowledge: 3D U-Net
3D U-Net 논문 리뷰: https://kyujinpy.tistory.com/9
[(3D) U-Net 논문 리뷰] - 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
*U-Net 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! 3D U-Net paper: [1606.06650] 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation (arxiv.org) 3D U-Net: Learning Dense Volumetric
kyujinpy.tistory.com
*해당 논문 리뷰는 3D U-Net에 대한 기본적인 개념을 이해하고 있다는 가정하에 진행됩니다! 3D U-Net을 모른다면 구조를 이해하기 힘들 수도 있습니다.
<간단한 용어정리>
ROI: Region Of Interest
ROR: Right Oblique ROI
RHR: Right Horizontal ROI
NR: Non-ROI
ROF: Right Oblique Fissure
RHF: Right Horizontal Fissure
NF: Non-Fissure
LOR: Left Oblique ROI
LOF: Left Oblique Fissure
Method
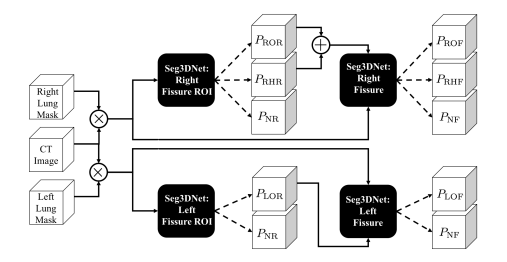
FissureNet의 전체적인 구조는 위의 사진과 같다.
첫번째로, right lung과 left lung을 구분해주기 위해서 segmentation을 진행하여 masking을 씌워준다.
두번째로, 각각의 right lung과 left lung을 구분해서 두 개의 process에 각각 넣어서 학습을 진행한다.
이 부분이 가장 중요한 포인트 인데,
위쪽의 모델은 right lung에 있는 fissure를 학습하는 부분이고,
아래쪽의 모델은 left lung에 있는 fissure를 학습하는 부분이다.
그리고 Introduciton 부분에 잠깐 언급된 lung의 사진을 보면 right는 horizontal, oblique fissure가 있고, left에는 oblique fissure 밖에 없다.
따라서 right lung process에서는 총 3개의 output(ROF, RHF, NF)가 나온다.
Left lung process에서는 총 2개의 output(LOF, NF)가 나온다.
또 추가적으로, Segmentation block을 Seg3DNet을 이용하여 구성한 다음에 각각의 process마다 총 2번의 output이 나온다.
여기서 첫번째 output은 Fissure가 있을 위치에 대한 지역(region; ROI)을 예측하는 것이고, 최종 output은 Fissure line을 예측하는 것이다.


+) 부가설명으로, 각 process에서 첫번째 output은 ROI를 예측하는 것이다.
+) ROI는 Region Of Interest의 약자로, Fissure line을 dilation을 통해서 5mm로 만들고 이것을 Ground truth라고 설정하고 학습을 진행한다.
+) ROI에서 학습된 결과를 두번째 process의 Seg3DNet에 넣어서 Fissure line을 예측하게 된다.
+) End-to-End 학습이 아니다!
이제 Seg3DNet구조를 살펴보자.
1. Seg3DNet
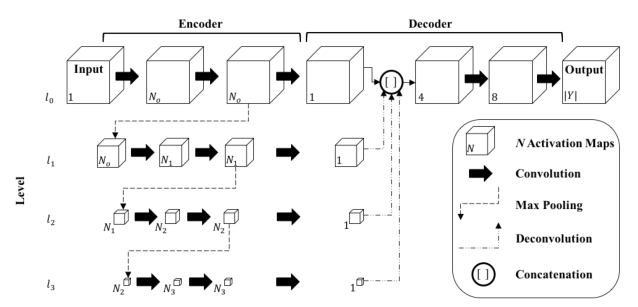
Seg3DNet은 Encoder와 Decoder로 이루어져 있는 3D U-Net 형태이다.
3D U-Net과 다른점이라고 한다면,
3D U-Net은 Deconvolution(Upsampling)을 진행할 때, 가장 낮은 level부터 천천히 deconvolution하면서 그 위에 level가 skip-connection 통해서 합쳐지는 과정이였는데,
Seg3DNet은 가장 낮은 level이 dimension이 가장 위의 level의 dimension으로 한번에 upsampling을 하고 skip-connection으로 original dimension과 합쳐진다.
다른 level에서 나온 feature voxel map들도 전부 original dimension으로 바로 upsampling 후에 한번에 skip-connection이 된다.
그리고 나서 Decoder를 통해서 channel을 조절하면서 segmentation 결과값을 추출한다.
여기서 channel은 left면 2, right면 3이다. (위에 FissureNet 구조 참고)
Furthermore
FissureNet을 통해서 Medical field의 computer vision에 많이 관심을 갖게 되었는데,
여러분들도 흥미롭게 보셨다면, 다른 논문들도 찾아서 계속 공부하길 바란다.
개인적으로는 UNETR 논문을 추천한다!
UNETR 논문 리뷰: https://kyujinpy.tistory.com/37
[UNETR 논문 리뷰] - UNETR: Transformers for 3D Medical Image Segmentation
*UNETR 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! UNETR paper: [2103.10504] UNETR: Transformers for 3D Medical Image Segmentation (arxiv.org) UNETR: Transformers for 3D Medical Image Segmentation Fu
kyujinpy.tistory.com
- 2022.12.30 kyujinpy 작성.



