*GLPDepth 논문 리뷰를 위한 글입니다! 궁금한 점이 있다면 댓글로 질문주세요!
GLPDepth paper: [2201.07436] Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth (arxiv.org)
Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth
Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strate
arxiv.org
GLPDepth github: GitHub - vinvino02/GLPDepth: GLPDepth PyTorch Implementation: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth
GitHub - vinvino02/GLPDepth: GLPDepth PyTorch Implementation: Global-Local Path Networks for Monocular Depth Estimation with Ver
GLPDepth PyTorch Implementation: Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth - GitHub - vinvino02/GLPDepth: GLPDepth PyTorch Implementation: Global-Local Path N...
github.com
Contents
2. Background Knowledge: Vision Transformer
- Selective Feature Fusion(SFF)
Simple Introduction


2D image에서 3D information 정보인 depth를 추출하는 일은 쉽지 않은 일이다.
하지만 Vision 분야에서는 여러 방면에서 depth estimation이 진행되고, 그 연구가 활발히 진행되고 있다.
기존의 SOTA 모델이였던 AdaBins보다 높은 성능을 보이는 GLPDepth를 소개할려고 한다.
이 역시도, Transformer가 기반이 되어서 만들어진 모델로, transformer가 vision 분야의 영역에서의 미치는 영향을 다시 알 수 있었다.
Background Knowledge: Vision Transformer
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
GLPDepth도 이미지를 patch화 시킨 후 merging 시키는 방법으로 network를 구성하기 때문에 위의 개념을 알고 들으면 훨씬 도움이 된다!
*해당 논문 리뷰는 ViT의 개념을 알고 있다고 가정하고 진행됩니다!
Method
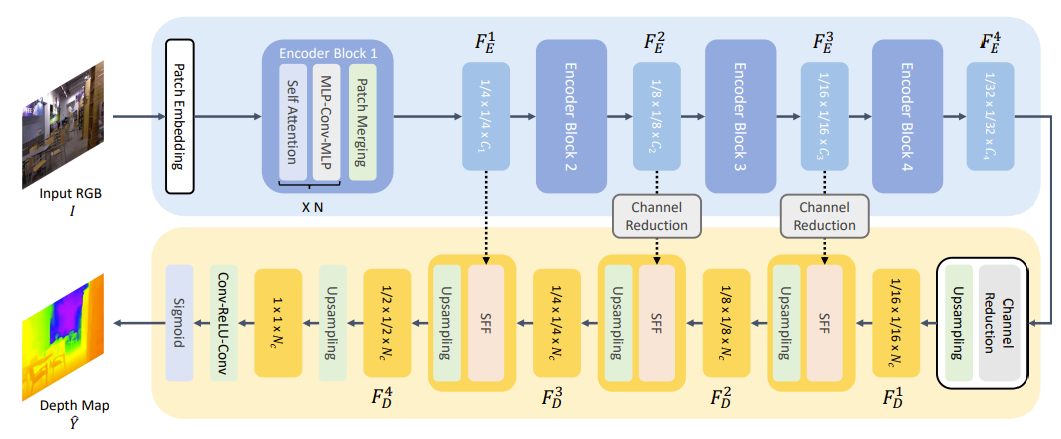
GLPDepth는 Global path, Local path로 구성이 되어 있다.
Global path의 구성
1. Image를 Patch로 나눠서 1D로 flatten 시킨다.
2. Transformer Encoder block에 넣어서, attention과 MLP+Conv+MLP를 적용한 후, Patch를 merging한다.
- 총 4번의 Transformer encoder block을 적용한다.
- 결과적으로, Block을 1/4, 1/8, 1/16, 1/32 사이즈로 scaling된 bottleneck feature 4개를 얻는다.
Local path의 구성
1. Global path에서 나온 embedding의 channel을 reduction한 후, upsampling을 진행한다.
2. 각 decoder stage마다 Global Path에서 나온 bottleneck feature를 SFF라는 network에 넣어서 embedding을 만든다. (밑에서 언급)
3. 마지막에 Conv-ReLU-Conv와 sigmoid를 적용해서 최종적으로 depth-map을 만들어낸다.
1. Selective Feature Fusion(SFF)
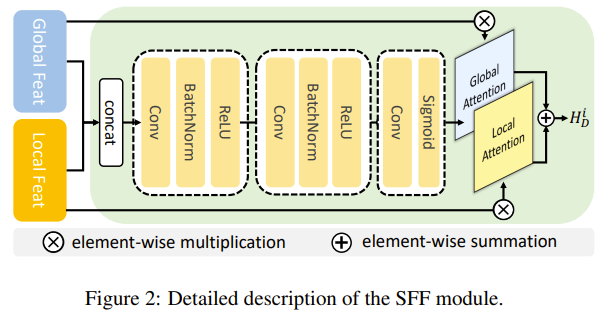
Local path에서 다뤘던 SFF에 대해서 한번 더 알아보자.
1. Global path와 Local path에서 나왔던 embedding concat한다.
2. Conv-BN-ReLU block을 2번 적용하고, 마지막에 Conv-Sigmoid를 적용한다.
3. 그리고 각각 global embedding과 local embedding을 이용해서 attention을 적용한다.
4. 그리고 최종적으로 값을 합해서 SFF embedding을 출력한다.
- 2023.01.05 Kyujinpy 작성.



