*DoRA를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
DoRA paper: https://arxiv.org/abs/2402.09353
DoRA: Weight-Decomposed Low-Rank Adaptation
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full
arxiv.org
DoRA github: https://github.com/NVlabs/DoRA
GitHub - NVlabs/DoRA: [ICML2024 (Oral)] Official PyTorch implementation of DoRA: Weight-Decomposed Low-Rank Adaptation
[ICML2024 (Oral)] Official PyTorch implementation of DoRA: Weight-Decomposed Low-Rank Adaptation - NVlabs/DoRA
github.com
Contents
Simple Introduction
최근에 wan-alpha 논문을 읽으면서, diffusion training에 DoRA를 활용하는 방법을 보았다.
DoRA에 대해서 좀 조사해보니, LoRA보다 성능 향상이 더 좋고 domain adaptation에 더 좋다는 경험담들이 reddit에 많이 있었다.
DoRA는 LoRA와 크게 다른건 없지만 심플하게 weight-decomposition을 통한 analysis를 토대로 훈련하는 방법을 살짝 바꿨을 뿐인데 더 좋은 성능과 robustness를 챙긴 논문이다.
DoRA에서는 weight을 magnitude와 direction 부분을 나눠서 생각하는데, 어떤식으로 접근한 것인지 살펴보자!
Background Knowledge: LoRA
LoRA 논문리뷰: https://kyujinpy.tistory.com/83
[LoRA 논문 리뷰] - LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
*LoRA를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! LoRA paper: https://arxiv.org/abs/2106.09685 LoRA: Low-Rank Adaptation of Large Language Models An important paradigm of natural language processing consists of larg
kyujinpy.tistory.com
*LoRA를 반드시 알고 오셔야 합니다!
Method
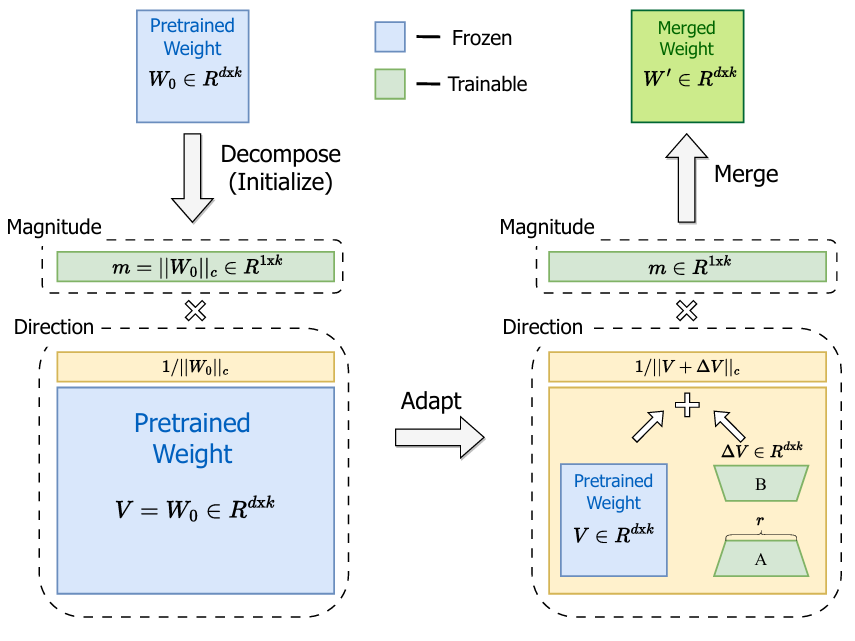
기본적으로, LoRA와 FT는 weight decompose와 관련된 analysis없이 제한된 parameters를 학습한다는 점을 논문에서 지적하고 있다.
논문의 저자들은 여러 논문들을 바탕으로, weight-decomposition을 다음과 같이 소개했다:
Pretrained weight를 magnitude와 direction으로 분해해서 생각하면 더 좋다.

Weight decompose 식은 eq. (2)를 기반으로 시작된다.
기본적으로 weight가 magnitude m과 direction V로 구성되어 있고 각각이 특정 learning을 담당하고 있다고 생각한다.
여기서 m과 V는 같은 값이라고 볼 수 있는데, pretrained weight W의 norm 값이라고 생각하면 된다.

기존에 LoRA가 단순하게 pretrained weight W0 + BA의 형태였다면, DoRA는 eq. (5)처럼 표현된다.
- magnitude m은 learnable parameter로 지정이 된다
- 그리고, direction인 V에서 LoRA를 적용하여 분모가 W0+BA가 되는 것을 확인할 수 있다.
(*여기서 BA는 learnable matrix parameter)
매우 단순한 아이디어이고 적용 방법이지만, 효과는 엄청났다! 그렇다면 왜 효과가 있었던 것일까?
Analysis
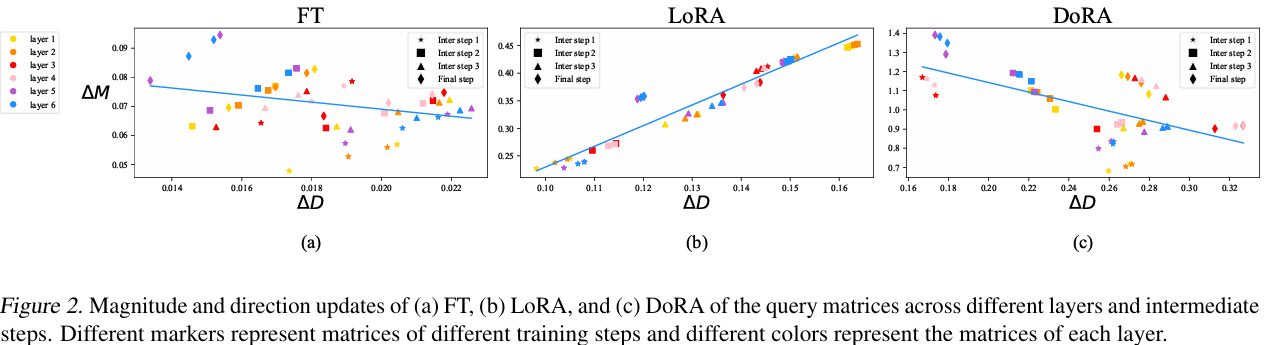
일단 기본적으로, weight decomposition의 아이디어를 얻은건 figure 2라고 할 수 있다.
그래프를 간단하게 설명하면, 기존 weight와 학습된 parameter 사이의 차이를 비교하는 그래프이고 파란색은 경향성을 나타낸다.
(x축은 magnitude, y축은 direction 변화량을 의미)
여기서 FT와 LoRA를 보면 서로의 경향성이 거의 반대인 것을 확인할 수 있다.
이는 FT와 다르게 LoRA에서는 direction과 magnitude 사이의 관계가 명백하게 재정립되었다고 볼 수 있다.
게다가 LoRA에서 direction의 변화량은 크진 않은데, magnitude의 변화량이 매우 컸다.
이러한 점들로 인해서, magnitude와 direction을 분리해서 고려하지 않는 것이 LoRA 학습의 complex로 이어져서 FT와 다른 경향성을 보이는 것이라고 분석했다.
하지만 DoRA의 경우, magnitude와 direction의 경향성이 FT와 유사한 것을 볼 수 있다.
이러한 이유로는
- DoRA는 norm을 통한 weight normalization이 안에 있기 때문에 training stable 하다.
- FT에서 magnitude와 direction의 변화량이 negative-slope을 보이는 이유는, 이미 pretraining 과정에서 충분히 학습되었기 때문에 domain-adaptation training에서 두 factors가 크게 흔들릴 필요는 없는 것이다. 이러한 현상을 LoRA는 반영하지 못하지만, DoRA는 magnitude와 direction으로 구분하여 trainable하게 훈련하기 때문에, 적절한 learning을 할 수 있는 것이다.
Result
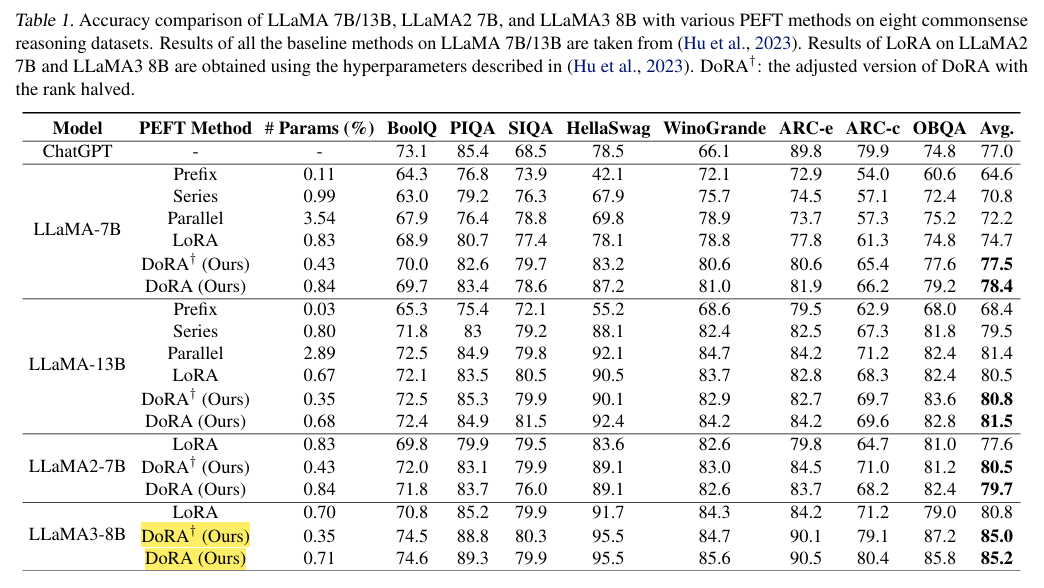
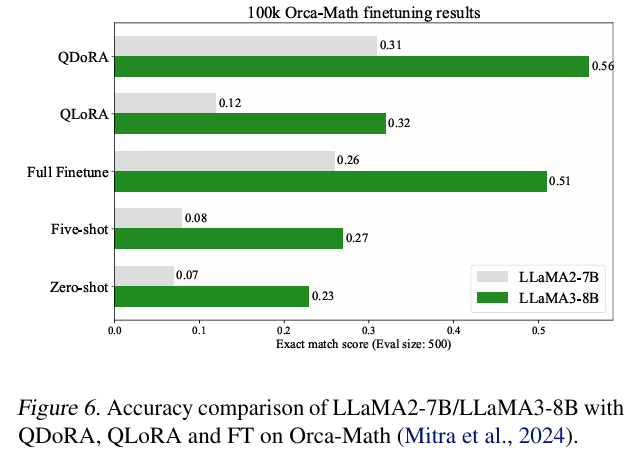
- 기본적으로 DoRA가 모두 우세하다!
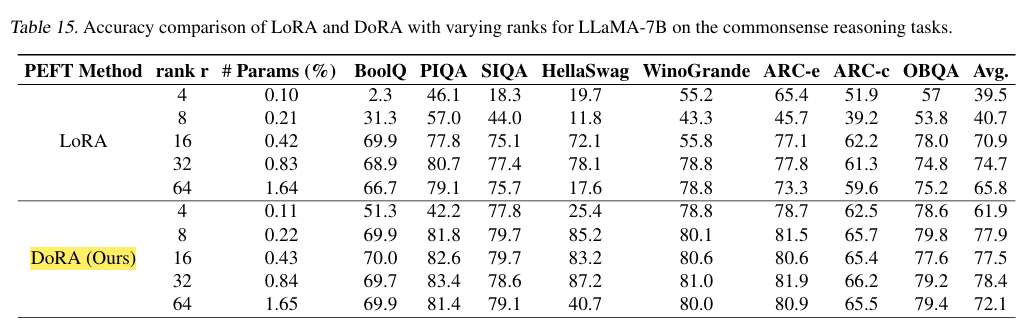
- rank에 따른 성능 평가인데, lora보다 모두 성능이 높은걸 확인할 수 있다.

- Image 분야에서도 lora보다 더 좋은 결과물을 보인다!
- 2026.01.21 Kyujinpy 작성.



