*FlowAlign를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
FlowAlign paper: https://arxiv.org/abs/2505.23145
FlowAlign: Trajectory-Regularized, Inversion-Free Flow-based Image Editing
Recent inversion-free, flow-based image editing methods such as FlowEdit leverages a pre-trained noise-to-image flow model such as Stable Diffusion 3, enabling text-driven manipulation by solving an ordinary differential equation (ODE). While the lack of e
arxiv.org
Contents
2. Background Knowledge: FlowEdit
Simple Introduction

최근 inversion-free 방법으로 image editing하는 방법들이 떠오르고 있다!
특히 rectified flow를 활용한 FLUX와 같은 모델들을 사용해서 해당 분야에서 좋은 효과를 보이고 있는데, 최근에는 flowedit 방법론이 대표적이었다.
하지만 flowedit은 editing이 잘 되긴 하지만, source image와의 consistency를 고려하지 못하여 source image가 가지는 특징들이 약간 손실된다는 단점이 있었다.
FlowAlign은 flowedit의 inversion-free 방법에서 source consistency를 고려할 수 있는 term을 추가해서 editing 성능을 높인 방법이다!
가볍게 설명들으러 가시죠!
Background Knowledge: FlowEdit
FlowEdit 리뷰: https://kyujinpy.tistory.com/175
[FlowEdit 논문 리뷰] - Inversion-Free Text-Based Editing Using Pre-Trained Flow Models
*FlowEdit를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! FlowEdit paper: https://arxiv.org/abs/2412.08629 FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow ModelsEditing real images using a pre-trained
kyujinpy.tistory.com
*FlowEdit의 한계점을 극복한 논문이기 때문에, 알고오시면 좋습니다!
Method

기존의 sampling (denoising) 과정에서는 classifier-free-gudiance (CFG)에 관한 scale value만 있었다.
하지만, FlowAlign에서는 source consistency를 고려하는 scale value도 추가한다.
여기에는 총 3개의 input이 들어간다!
- [source latent (q), source prompt]
- [target latent (p), source prompt]
- [target latent, target prompt]
알고리즘1에서 주의깊게 볼 수식은 line 7,8,10이다.
line7: target latent에 대한 velocity 계산.
=> source/target prompt에 대한 차이를 활용해서 CFG 계산
line8: source latent에 대한 velocity
line10: Semantic Guidance와 source consistency에 대한 latent를 x_t에 추가
=> x_t는 source에서 target으로 서서히 변해가는 t 시점의 latent
=> Source image에서 target image로 가는 path에 대해서 guidance를 주는 것이, semantic guidance
=> 변화하는 path에서 regularization term으로 활용되는 것이, source consistency
*자세한 수식 전개와 증명은 논문 참고!
Result

- Source와 edited image 결과물

- 다른 모델에 비해서, background consistency 유지가 잘 된다.
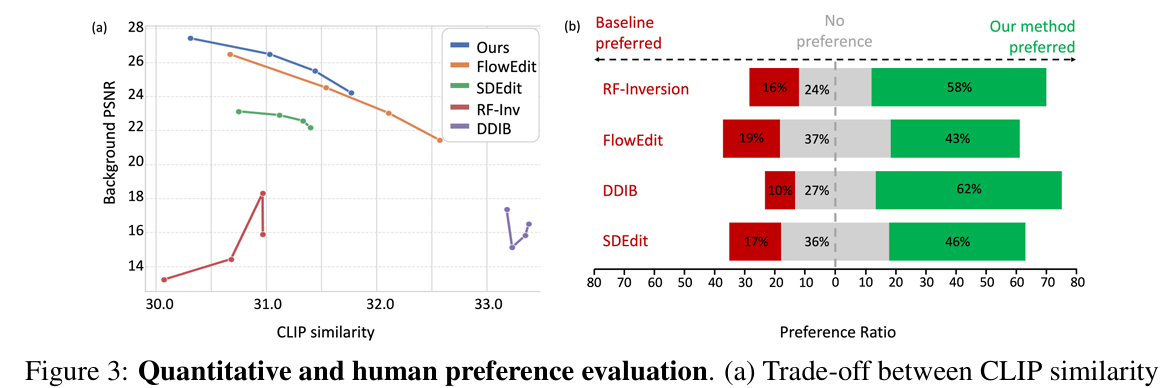
- Quantitative result에서도 flowalign의 성능이 가장 좋다.
- 2025.08.16 Kyujinpy 작성.



