*UniCon를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
UniCon paper: https://arxiv.org/abs/2410.11439
A Simple Approach to Unifying Diffusion-based Conditional Generation
Recent progress in image generation has sparked research into controlling these models through condition signals, with various methods addressing specific challenges in conditional generation. Instead of proposing another specialized technique, we introduc
arxiv.org
UniCon github: https://lixirui142.github.io/unicon-diffusion/
UniCon: A Simple Approach to Unifying Diffusion-based Conditional Generation
project webpage
lixirui142.github.io
Contents
Simple Introduction

오늘날 image/video diffusion model을 훈련할 때, depth나 pose와 같은 정보를 condition으로 많이 활용한다.
해당 연구에서 가장 많이 쓰이는 방법이 바로 controlnet이었다.
오늘 소개할 Unicon은 controlnet보다 더 강력하게 condition prior를 모델에 훈련시킬 수 있는 방법을 보여준다!
특히 논문에서 소개하는 joint cross attention 기법은 매우 심플하면서도 강력한 성능을 보인다!
Method
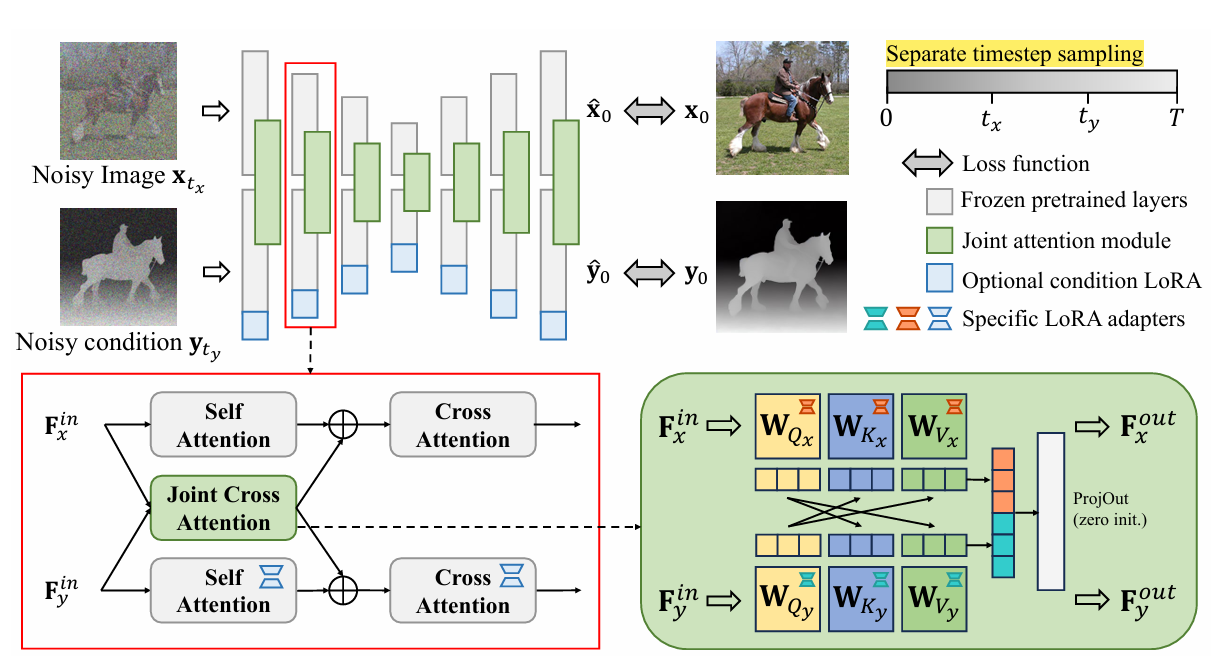
일단 모델 전체 구조를 살펴보면, two-branch로 구성이 되어있다.
- X 부분은 image (rgb)에 대한 diffusion 학습
- Y 부분은 depth (or other condition)에 대한 diffusion 학습
여기서 활용하는 diffusion model의 prior는 RGB이므로, depth 부분을 학습하는 diffusion에는 LoRA를 활용하여 fine-tuning을 한다.
이제부터 모델의 핵심 포인트인데, unicon 논문에서는 image와 depth (condition)에 대한 정보를 잘 교환하기 위해서 joint cross attention 방법을 활용한다!
방법은 되게 간단하다!
- X에 대한 query + Y에 대한 key/value를 활용하여 self-attn
- Y에 대한 query + X에 대한 key/value를 활용하여 self-attn
- 연산을 통해 나온 2개의 latent vectors를 concatenate한 후, linear projection layer 통과
- 그리고 다시 seperate하여, 각 branch의 cross-attn 직전에 add operation 수행
해당 방법은, image와 depth가 가지고 있는 서로의 정보를 attention 방법을 통해 효율적으로 교환하도록 도와준다!
이 방법은 모델 내부에서 정보 교환이 일어나고, condition의 noise 정도에 따라 다양한 generation task를 수행할 수 있다!
(밑에 결과들 참고)
*추가로 joint cross attention은 기존 diffusion model의 self-attn pre-trained weight를 copy한 것이고, 각각의 query/key/value에 대한 모든 linear layer에 lora module을 붙여 training한다!

추가적으로 해당 모델을 학습할 때, [x,y]에 각각 서로 다른 noise를 활용하여 disentagled training을 한다!
Result

- Diverse image-depth generation task results

- Sampling step control로 image generation 수행
(예시: 왼쪽의 사자는 text와 depth condition을 주는데, depth의 sampling step을 T가 아닌 중간부터 시작하면 depth information이 어느정도 남아있는 상태로 de-noising이 되므로 depth condition에 대한 initial guidance를 주는 것과 같다.)
- 2026.01.20 Kyujinpy 작성.



