WANAlign2.1⚡ is released!!
Awesome-Training-Free Video Editing Open Source Project with WAN2.1@!!
Awensome-OpenSource!!!
WANAlign2.1⚡ github: https://github.com/KyujinHan/Awesome-Training-Free-WAN2.1-Editing
GitHub - KyujinHan/Awesome-Training-Free-WAN2.1-Editing: Training-Free (Inversion-Free) methods meet WAN2.1-T2V
Training-Free (Inversion-Free) methods meet WAN2.1-T2V - KyujinHan/Awesome-Training-Free-WAN2.1-Editing
github.com
Contents
Simple Introduction

안녕하세요!
간만에 인사드리는 kyujinpy 입니다😄
오늘은 간만에 computer vision (CV) 오픈소스 프로젝트를 들고 왔습니다!🤗
최근에 training-free 방법론들이 많이 등장하면서 text-guidance를 기반으로 image editing하는 방법들이 많이 등장하고 있습니다! 또한 rectified flow 기반의 inversion-free 방법인 flowedit이 나온 이후, flowdirector와 같은 inversion-free video editing 방법도 등장을 하고 있는데요..!🫠
저는 최근에 나온 flowalign과 rectified flow 기반 video generation model인 WAN2.1을 통합하여 기존보다 더 빠르고 퀄리티 높게 video를 editing하는 WANAlign2.1⚡을 제작하여 공개합니다!😎😎
WANAlign2.1은 flowalign에서 제안한 inversion-free editing 수식을 sampling (denoising) 과정에 적용하여 훈련없이 input text에 맞춰 source video로부터 video editing을 가능하게 합니다!🐦🔥
또한 기존 방법들은 sampling 과정에서 foreground와 background가 구분되지 않아, 같은 강도로 editing이 진행되어 source video와의 consistency가 떨어지는 일이 많았습니다.😵😵
저는 이러한 한계점을 극복하기 위해, Decoupled Inversion-Free Sampling (DIFS) 방법을 도입하였습니다.😎
DIFS는 attention feature로부터 얻은 masking을 latent value에 적용하여 fg/bg region으로 구분하고, 구분된 latent를 서로 다른 editing 강도로 sampling 한 후 다시 merge하게 됩니다.
WANAlign2.1은 실제로 inference speed나 qualitative results에서 기존 방법보다 훨씬 좋은 성능을 보이고 있습니다.
많은 관심은 저에게 힘이 됩니다!! 🤗 🤗
WANAlign2.1 프로젝트와 더불어 제가 공개한 github는 아래의 주요 코드들이 나와있습니다!
- Attention masking 방법 코드
- WAN2.1 + FlowEdit (inversion-free) 코드
- WAN2.1 + FlowAlign (Inversion-free) 코드
- WANAlign2.1⚡ 코드
또한 해당 코드를 diffusers library 🤗 와 연동하여 사용성도 매우 용이합니다!✨
모든 예제에 대한 예시 코드들과 config file도 있으니 자유롭게 활용하시길 바랍니다.🍷
(simple english version)
I present WANAlign2.1⚡, an inversion-free video editing framework that combines the inversion-free editing method FlowAlign with WAN2.1.
By integrating FlowAlign’s inversion-free sampling equation into WAN2.1, my approach preserves the intrinsic characteristics of the source video during editing.
To further enhance control, I introduce Decoupled Inversion-Free Sampling (DIFS), which leverages attention masking to independently adjust the editing strength between preserved and modified regions.
The previous methods frequently modified regions that should have been preserved, thereby degrading overall consistency. Our WANAlign2.1⚡ achieves improved spatial-temporal consistency and enhanced text-guided editing performance through DIFS.
As shown in the results, qualitative results demonstrate that our method is state-of-the-art.
Method
위에는 WANAlign2.1 구조입니다.
FlowAlign의 inversion-free 구조를 활용하기 때문에, 위와 같은 구조로 editing이 이루어집니다.
간단하게 설명하면, input은 3개가 주어지게 됩니다.
1. [source latent, source text] ==(WAN2.1)==> source velocity
2. [target latent, source text]
3. [target latent, target text] ==(WAN2.1)==> target velocity
여기서, 첫번째와 세번째 input에서 각각 main object (bear, tiger)에 대한 attention mask를 추출하게 됩니다.
이후, attention mask와 3개의 input에 대한 velocity vector를 DIFS에 넣어서 효과적으로 sampling을 진행합니다.
DIFS로부터 나온 최종적인 target velocity를 활용하여 source video에서 target video로 editing을 수행하게 됩니다.
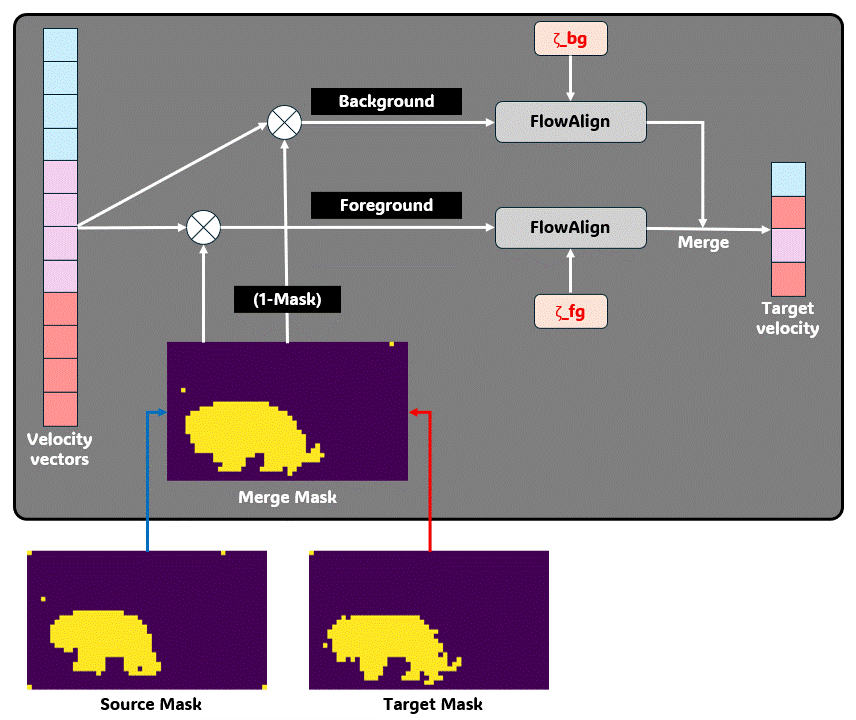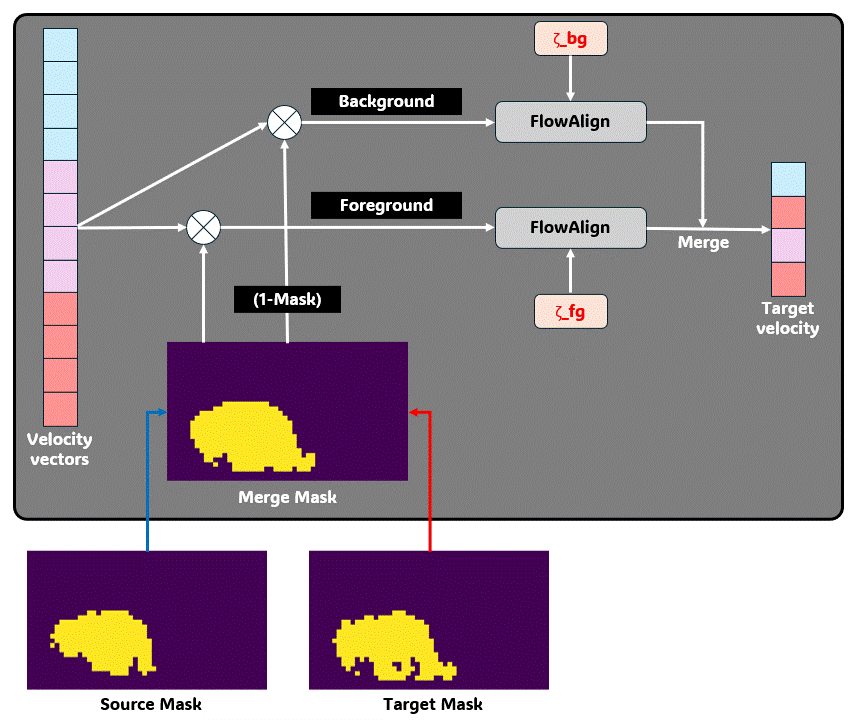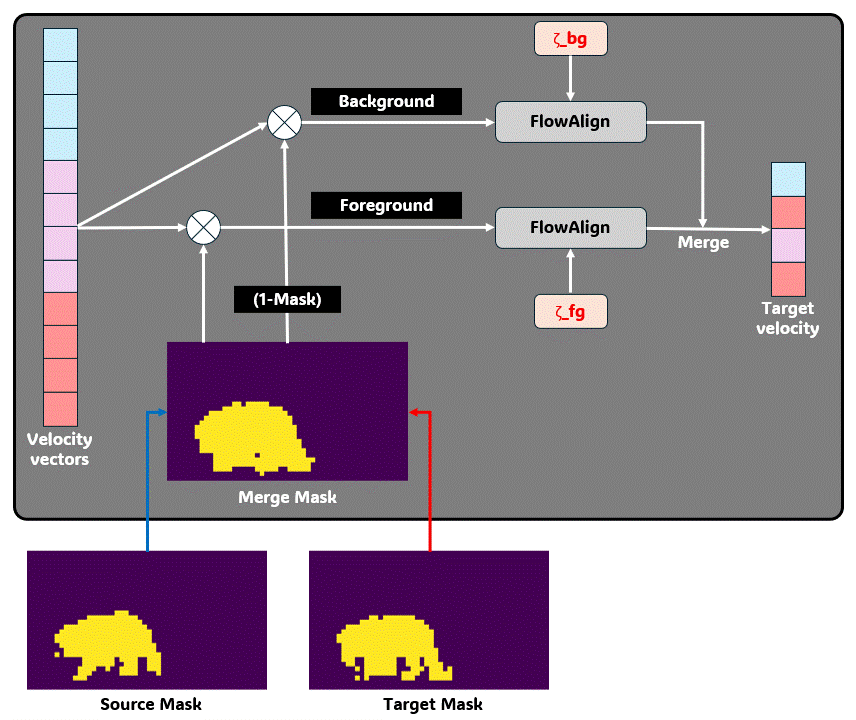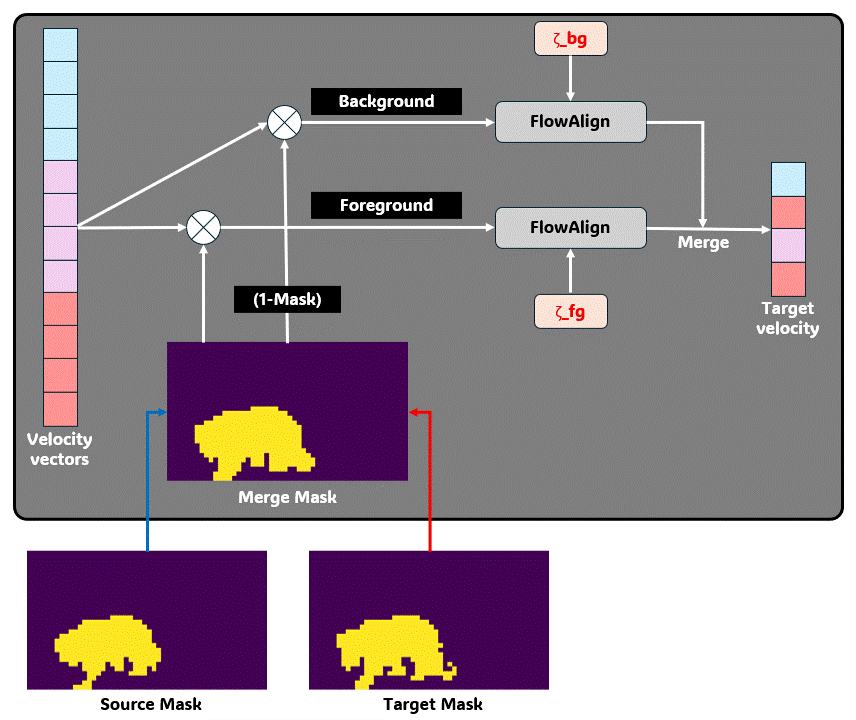
Decoupled Inversion-Free Sampling (DIFS)는 아주 심플하지만 효과적으로 bg/fg 영역을 다르게 editing할 수 있도록 도와줍니다!
여기서 zeta scale 값은 flowalign의 source consistency를 조절하는 값입니다!
즉 zeta가 클수록 source video와의 consistency가 높아지게 되는데, DIFS에서는 fg/bg에 따라서 zeta 값을 다르게 설정할 수 있기 때문에 editing할 영역을 독립적으로 구분하여 계산할 수 있게 됩니다.
*FlowAlign에 대한 리뷰는 아래 글을 참고해주세요!
FlowAlign 논문 리뷰: https://kyujinpy.tistory.com/179
[FlowAlign 논문 리뷰] - Trajectory-Regularized, Inversion-Free Flow-based Image Editing
*FlowAlign를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! FlowAlign paper: https://arxiv.org/abs/2505.23145 FlowAlign: Trajectory-Regularized, Inversion-Free Flow-based Image EditingRecent inversion-free, flow-based im
kyujinpy.tistory.com
Result

- Inference에서, WANAlign2.1이 가장 빠름!

- Color/Background editing에서 다른 모델은 object 특징이 손실되지만, WANAlign2.1⚡은 잘 유지됨
- Object Editing에서도 robust하게 좋은 성능을 보임.

- Texture editing에서도, text-guidance를 잘 따르는 것을 볼 수 있음.
- Add effect/object에서는 다른 모델들은 motion이 부자연스럽거나 source video consistency가 떨어지지만, WANAlign2.1은 잘 작동한다.
- 2025.08.16 Kyujinpy 작성.
(이 프로젝트를 소개하기 위해서, 앞에 수많은 논문리뷰를..ㅎㅎ)
'AI > CV project' 카테고리의 다른 글
| [CIKM' 25 LOD] - Learnable Orthogonal Decomposition for Non-Regressive Prediction for PDE (3) | 2025.11.30 |
|---|---|
| [DiT-3D or DDPM Code 분석] (0) | 2024.09.24 |
| [SMPL-X Implementation] KyujinHan/Smplify-X-Perfect-Implementation (30) | 2024.03.18 |
| [DDPM 코드 리뷰] (6) | 2023.12.30 |
| [Tune-A-VideKO] - 한국어 기반 One-shot Tuning of diffusion for Text-to-Video 모델 (0) | 2023.08.18 |



