Github Link
https://github.com/DiT-3D/DiT-3D/blob/main/train.py
DiT-3D/train.py at main · DiT-3D/DiT-3D
🔥🔥🔥Official Codebase of "DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation" - DiT-3D/DiT-3D
github.com
*매우매우 글이 긴 초장문입니다..!
각 코드별로 엄청 상세하게 리뷰했고, 최대한 흐름에 따라서 코드와 수식을 붙여서 설명하였습니다.
*DiT-3D 코드를 기반으로 설명하고 있지만, dataloader를 제외한 나머지 리뷰는 2D 기반의 DDPM or Diffusion Transformer 코드의 흐름으로 이해하셔도 무관합니다.
Contents
🦎DataLoader Code
# train.py line 565
train_dataset, _ = get_dataset(opt.dataroot, opt.npoints, opt.category)
## get_dataset function
def get_dataset(dataroot, npoints,category):
tr_dataset = ShapeNet15kPointClouds(root_dir=dataroot,
categories=category.split(','), split='train',
tr_sample_size=npoints, # 2048
te_sample_size=npoints,
scale=1.,
normalize_per_shape=False,
normalize_std_per_axis=False,
random_subsample=True)
te_dataset = ShapeNet15kPointClouds(root_dir=dataroot,
categories=category.split(','), split='val',
tr_sample_size=npoints,
te_sample_size=npoints,
scale=1.,
normalize_per_shape=False,
normalize_std_per_axis=False,
all_points_mean=tr_dataset.all_points_mean,
all_points_std=tr_dataset.all_points_std,
)
return tr_dataset, te_dataset
# tr_sample_size = 2048
# te_sample_size = 2048
class ShapeNet15kPointClouds(Uniform15KPC):
def __init__(self, root_dir="data/ShapeNetCore.v2.PC15k",
categories=['airplane'], tr_sample_size=10000, te_sample_size=2048,
split='train', scale=1., normalize_per_shape=False,
normalize_std_per_axis=False, box_per_shape=False,
random_subsample=False,
all_points_mean=None, all_points_std=None,
use_mask=False):
self.root_dir = root_dir
self.split = split
assert self.split in ['train', 'test', 'val']
self.tr_sample_size = tr_sample_size
self.te_sample_size = te_sample_size
self.cates = categories
if 'all' in categories:
self.synset_ids = list(cate_to_synsetid.values())
else:
self.synset_ids = [cate_to_synsetid[c] for c in self.cates]
# assert 'v2' in root_dir, "Only supporting v2 right now."
self.gravity_axis = 1
self.display_axis_order = [0, 2, 1]
super(ShapeNet15kPointClouds, self).__init__(
root_dir, self.synset_ids,
tr_sample_size=tr_sample_size,
te_sample_size=te_sample_size,
split=split, scale=scale,
normalize_per_shape=normalize_per_shape, box_per_shape=box_per_shape,
normalize_std_per_axis=normalize_std_per_axis,
random_subsample=random_subsample,
all_points_mean=all_points_mean, all_points_std=all_points_std,
input_dim=3, use_mask=use_mask)
- https://github.com/DiT-3D/DiT-3D/blob/main/datasets/shapenet_data_pc.py#L201
- → ShapeNet15kPointClouds class는 Uniform15KPC class를 상속받음.
class Uniform15KPC(Dataset):
def __init__(self, root_dir, subdirs, tr_sample_size=10000,
te_sample_size=10000, split='train', scale=1.,
normalize_per_shape=False, box_per_shape=False,
random_subsample=False,
normalize_std_per_axis=False,
all_points_mean=None, all_points_std=None,
input_dim=3, use_mask=False):
self.root_dir = root_dir
self.split = split
self.in_tr_sample_size = tr_sample_size
self.in_te_sample_size = te_sample_size
self.subdirs = subdirs
self.scale = scale
self.random_subsample = random_subsample
self.input_dim = input_dim
self.use_mask = use_mask
self.box_per_shape = box_per_shape
if use_mask:
self.mask_transform = PointCloudMasks(radius=5, elev=5, azim=90)
self.all_cate_mids = []
self.cate_idx_lst = []
self.all_points = []
for cate_idx, subd in enumerate(self.subdirs):
# NOTE: [subd] here is synset id
sub_path = os.path.join(root_dir, subd, self.split)
if not os.path.isdir(sub_path):
print("Directory missing : %s" % sub_path)
continue
all_mids = []
for x in os.listdir(sub_path):
if not x.endswith('.npy'):
continue
all_mids.append(os.path.join(self.split, x[:-len('.npy')]))
# NOTE: [mid] contains the split: i.e. "train/<mid>" or "val/<mid>" or "test/<mid>"
for mid in all_mids:
# obj_fname = os.path.join(sub_path, x)
obj_fname = os.path.join(root_dir, subd, mid + ".npy")
try:
point_cloud = np.load(obj_fname) # (15k, 3)
except:
continue
assert point_cloud.shape[0] == 15000
self.all_points.append(point_cloud[np.newaxis, ...])
self.cate_idx_lst.append(cate_idx)
self.all_cate_mids.append((subd, mid))
# Shuffle the index deterministically (based on the number of examples)
self.shuffle_idx = list(range(len(self.all_points)))
random.Random(38383).shuffle(self.shuffle_idx)
self.cate_idx_lst = [self.cate_idx_lst[i] for i in self.shuffle_idx]
self.all_points = [self.all_points[i] for i in self.shuffle_idx]
self.all_cate_mids = [self.all_cate_mids[i] for i in self.shuffle_idx]
# Normalization
self.all_points = np.concatenate(self.all_points) # (N, 15000, 3)
self.normalize_per_shape = normalize_per_shape
self.normalize_std_per_axis = normalize_std_per_axis
if all_points_mean is not None and all_points_std is not None: # using loaded dataset stats
self.all_points_mean = all_points_mean
self.all_points_std = all_points_std
elif self.normalize_per_shape: # per shape normalization
B, N = self.all_points.shape[:2]
self.all_points_mean = self.all_points.mean(axis=1).reshape(B, 1, input_dim)
if normalize_std_per_axis:
self.all_points_std = self.all_points.reshape(B, N, -1).std(axis=1).reshape(B, 1, input_dim)
else:
self.all_points_std = self.all_points.reshape(B, -1).std(axis=1).reshape(B, 1, 1)
elif self.box_per_shape:
B, N = self.all_points.shape[:2]
self.all_points_mean = self.all_points.min(axis=1).reshape(B, 1, input_dim)
self.all_points_std = self.all_points.max(axis=1).reshape(B, 1, input_dim) - self.all_points.min(axis=1).reshape(B, 1, input_dim)
else: # normalize across the dataset
self.all_points_mean = self.all_points.reshape(-1, input_dim).mean(axis=0).reshape(1, 1, input_dim)
if normalize_std_per_axis:
self.all_points_std = self.all_points.reshape(-1, input_dim).std(axis=0).reshape(1, 1, input_dim)
else:
self.all_points_std = self.all_points.reshape(-1).std(axis=0).reshape(1, 1, 1)
self.all_points = (self.all_points - self.all_points_mean) / self.all_points_std
if self.box_per_shape:
self.all_points = self.all_points - 0.5
self.train_points = self.all_points[:, :10000]
self.test_points = self.all_points[:, 10000:]
self.tr_sample_size = min(10000, tr_sample_size)
self.te_sample_size = min(5000, te_sample_size)
print("Total number of data:%d" % len(self.train_points))
print("Min number of points: (train)%d (test)%d"
% (self.tr_sample_size, self.te_sample_size))
assert self.scale == 1, "Scale (!= 1) is deprecated"
def get_pc_stats(self, idx):
if self.normalize_per_shape or self.box_per_shape:
m = self.all_points_mean[idx].reshape(1, self.input_dim)
s = self.all_points_std[idx].reshape(1, -1)
return m, s
return self.all_points_mean.reshape(1, -1), self.all_points_std.reshape(1, -1)
def renormalize(self, mean, std):
self.all_points = self.all_points * self.all_points_std + self.all_points_mean
self.all_points_mean = mean
self.all_points_std = std
self.all_points = (self.all_points - self.all_points_mean) / self.all_points_std
self.train_points = self.all_points[:, :10000]
self.test_points = self.all_points[:, 10000:]
def __len__(self):
return len(self.train_points)
def __getitem__(self, idx):
tr_out = self.train_points[idx]
if self.random_subsample:
tr_idxs = np.random.choice(tr_out.shape[0], self.tr_sample_size)
else:
tr_idxs = np.arange(self.tr_sample_size)
tr_out = torch.from_numpy(tr_out[tr_idxs, :]).float()
te_out = self.test_points[idx]
if self.random_subsample:
te_idxs = np.random.choice(te_out.shape[0], self.te_sample_size)
else:
te_idxs = np.arange(self.te_sample_size)
te_out = torch.from_numpy(te_out[te_idxs, :]).float()
m, s = self.get_pc_stats(idx)
cate_idx = self.cate_idx_lst[idx]
sid, mid = self.all_cate_mids[idx]
out = {
'idx': idx,
'train_points': tr_out,
'test_points': te_out,
'mean': m, 'std': s, 'cate_idx': cate_idx,
'sid': sid, 'mid': mid
}
if self.use_mask:
# masked = torch.from_numpy(self.mask_transform(self.all_points[idx]))
# ss = min(masked.shape[0], self.in_tr_sample_size//2)
# masked = masked[:ss]
#
# tr_mask = torch.ones_like(masked)
# masked = torch.cat([masked, torch.zeros(self.in_tr_sample_size - ss, 3)],dim=0)#F.pad(masked, (self.in_tr_sample_size-masked.shape[0], 0), "constant", 0)
#
# tr_mask = torch.cat([tr_mask, torch.zeros(self.in_tr_sample_size- ss, 3)],dim=0)#F.pad(tr_mask, (self.in_tr_sample_size-tr_mask.shape[0], 0), "constant", 0)
# out['train_points_masked'] = masked
# out['train_masks'] = tr_mask
tr_mask = self.mask_transform(tr_out)
out['train_masks'] = tr_mask
return out
- PointFlow 논문에 근거하여 pre-processing을 진행하고 있음.
- self.all_points ⇒ (N, 15000, 3)
- (1) Normalization: Points axis를 기준으로, mean과 std를 계산하여 아래와 같이 적용
self.all_points = (self.all_points - self.all_points_mean) / self.all_points_std- (2) Training과 Testing할 때 2048개의 points를 random하게 sampling함.
def __getitem__(self, idx): tr_out = self.train_points[idx] if self.random_subsample: # True임. tr_idxs = np.random.choice(tr_out.shape[0], self.tr_sample_size) else: tr_idxs = np.arange(self.tr_sample_size) tr_out = torch.from_numpy(tr_out[tr_idxs, :]).float() te_out = self.test_points[idx] if self.random_subsample: te_idxs = np.random.choice(te_out.shape[0], self.te_sample_size) else: te_idxs = np.arange(self.te_sample_size) te_out = torch.from_numpy(te_out[te_idxs, :]).float() m, s = self.get_pc_stats(idx) # m은 mean # s는 std값 out = { 'idx': idx, 'train_points': tr_out, 'test_points': te_out, 'mean': m, 'std': s, 'cate_idx': cate_idx, 'sid': sid, 'mid': mid } return out
의문점 1가지
*근데 train-test를 구분할 때, point를 기준으로 하나?
- 처음 본 point cloud 좌표라서 괜찮은건가?
self.train_points = self.all_points[:, :10000]
self.test_points = self.all_points[:, 10000:]
🐍 Model Training
# <https://github.com/DiT-3D/DiT-3D/blob/cfcc16b62004d735e935d14e0e8dc2d00a96041d/train.py#L410>
class Model(nn.Module):
def __init__(self, args, betas, loss_type: str, model_mean_type: str, model_var_type:str):
super(Model, self).__init__()
self.diffusion = GaussianDiffusion(betas, loss_type, model_mean_type, model_var_type)
# Check DiT3D_models_WindAttn
if args.window_size > 0:
self.model = DiT3D_models_WindAttn[args.model_type](pretrained=args.use_pretrained,
input_size=args.voxel_size,
window_size=args.window_size,
window_block_indexes=args.window_block_indexes,
num_classes=args.num_classes
)
else:
self.model = DiT3D_models[args.model_type](pretrained=args.use_pretrained,
input_size=args.voxel_size,
num_classes=args.num_classes
)
def prior_kl(self, x0):
return self.diffusion._prior_bpd(x0)
def all_kl(self, x0, y, clip_denoised=True):
total_bpd_b, vals_bt, prior_bpd_b, mse_bt = self.diffusion.calc_bpd_loop(self._denoise, x0, y, clip_denoised)
return {
'total_bpd_b': total_bpd_b,
'terms_bpd': vals_bt,
'prior_bpd_b': prior_bpd_b,
'mse_bt':mse_bt
}
def _denoise(self, data, t, y):
B, D, N= data.shape
assert data.dtype == torch.float
assert t.shape == torch.Size([B]) and t.dtype == torch.int64
out = self.model(data, t, y)
assert out.shape == torch.Size([B, D, N])
return out
def get_loss_iter(self, data, noises=None, y=None):
B, D, N = data.shape # [16, 3, 2048]
t = torch.randint(0, self.diffusion.num_timesteps, size=(B,), device=data.device)
if noises is not None:
noises[t!=0] = torch.randn((t!=0).sum(), *noises.shape[1:]).to(noises)
losses = self.diffusion.p_losses(
denoise_fn=self._denoise, data_start=data, t=t, noise=noises, y=y)
assert losses.shape == t.shape == torch.Size([B])
return losses
def gen_samples(self, shape, device, y, noise_fn=torch.randn,
clip_denoised=True,
keep_running=False):
return self.diffusion.p_sample_loop(self._denoise, shape=shape, device=device, y=y, noise_fn=noise_fn,
clip_denoised=clip_denoised,
keep_running=keep_running)
def gen_sample_traj(self, shape, device, y, freq, noise_fn=torch.randn,
clip_denoised=True,keep_running=False):
return self.diffusion.p_sample_loop_trajectory(self._denoise, shape=shape, device=device, y=y, noise_fn=noise_fn, freq=freq,
clip_denoised=clip_denoised,
keep_running=keep_running)
def train(self):
self.model.train()
def eval(self):
self.model.eval()
def multi_gpu_wrapper(self, f):
self.model = f(self.model)
- get_loss_iter 함수를 통해서 훈련
- self.diffusion → GaussianDiffusion class
# p loss 부분 (denoising)
def p_losses(self, denoise_fn, data_start, t, noise=None, y=None):
"""
Training loss calculation
"""
B, D, N = data_start.shape
assert t.shape == torch.Size([B])
if noise is None:
noise = torch.randn(data_start.shape, dtype=data_start.dtype, device=data_start.device)
assert noise.shape == data_start.shape and noise.dtype == data_start.dtype
# 밑에 함수 있음 (diffusion)
data_t = self.q_sample(x_start=data_start, t=t, noise=noise)
if self.loss_type == 'mse':
# predict the noise instead of x_start. seems to be weighted naturally like SNR
eps_recon = denoise_fn(data_t, t, y)
assert data_t.shape == data_start.shape
assert eps_recon.shape == torch.Size([B, D, N])
assert eps_recon.shape == data_start.shape
losses = ((noise - eps_recon)**2).mean(dim=list(range(1, len(data_start.shape))))
elif self.loss_type == 'kl':
losses = self._vb_terms_bpd(
denoise_fn=denoise_fn, data_start=data_start, data_t=data_t, t=t, y=y, clip_denoised=False,
return_pred_xstart=False)
else:
raise NotImplementedError(self.loss_type)
assert losses.shape == torch.Size([B])
return losses
# q_sample: noise가 입혀진 x값 추출됨
def q_sample(self, x_start, t, noise=None):
"""
Diffuse the data (t == 0 means diffused for 1 step)
"""
if noise is None:
noise = torch.randn(x_start.shape, device=x_start.device)
assert noise.shape == x_start.shape
# 모델 initialization 될 때 만들어진 값 활용
## alphas: 1 - beta
## self.sqrt_alphas_cumprod: sqrt(t시점까지의 alpha cumprod 연산된 값들)
## self.sqrt_one_minus_alphas_cumprod: sqrt(1-cum_alphas)
#### x_start * self.sqrt_alphas + sqrt(1-alphas) * noises
#### DDPM의 11번째 수식(?)
return (
self._extract(self.sqrt_alphas_cumprod.to(x_start.device), t, x_start.shape) * x_start +
self._extract(self.sqrt_one_minus_alphas_cumprod.to(x_start.device), t, x_start.shape) * noise
)
def _extract(a, t, x_shape):
"""
Extract some coefficients at specified timesteps,
then reshape to [batch_size, 1, 1, 1, 1, ...] for broadcasting purposes.
"""
bs, = t.shape
assert x_shape[0] == bs
out = torch.gather(a, 0, t)
assert out.shape == torch.Size([bs])
return torch.reshape(out, [bs] + ((len(x_shape) - 1) * [1]))
- p_losses → q_sample → p_losses (mse 연산)
- q_sample로 부터, x input 값을 noise로 입힘.
- denoise_fn(data_t, t, y)로 들어감
- Model class의 _denoise function → DiT-3D 블럭 forward로 들어감

DiT3D_models_WindAttn = {
'DiT-XL/2': DiT_XL_2, 'DiT-XL/4': DiT_XL_4, 'DiT-XL/8': DiT_XL_8,
'DiT-L/2': DiT_L_2, 'DiT-L/4': DiT_L_4, 'DiT-L/8': DiT_L_8,
'DiT-B/2': DiT_B_2, 'DiT-B/4': DiT_B_4, 'DiT-B/8': DiT_B_8,
'DiT-S/2': DiT_S_2, 'DiT-S/4': DiT_S_4, 'DiT-S/8': DiT_S_8,
}
def DiT_S_2(pretrained=False, **kwargs):
return DiT(depth=12, hidden_size=384, patch_size=2, num_heads=6, **kwargs)
- https://github.com/DiT-3D/DiT-3D/blob/main/models/dit3d_window_attn.py
- DiT Class를 return 받음
def forward(self, x, t, y):
"""
Forward pass of DiT.
x: (N, C, P) tensor of spatial inputs (point clouds or latent representations of images)
t: (N,) tensor of diffusion timesteps
y: (N,) tensor of class labels
"""
# Voxelization
features, coords = x, x
x, voxel_coords = self.voxelization(features, coords)
x = self.x_embedder(x)
x = x + self.pos_embed
t = self.t_embedder(t)
y = self.y_embedder(y, self.training)
c = t + y
for block in self.blocks:
x = block(x, c)
x = self.final_layer(x, c)
x = self.unpatchify_voxels(x)
# Devoxelization
x = F.trilinear_devoxelize(x, voxel_coords, self.input_size, self.training)
return x
- self.voxelization → voxel 형태로 변환
- Nx3 → VxVxVx3 (default V: 32)
- self.x_embedder: Conv3D block
- (B, C, X, Y, Z) → (B, E, X, Y, Z)
- C는 coordinates 3을 나타내는 값
- self.t_embedder: t embedding
- t값은 batch size 만큼의 정수 형태임
def timestep_embedding(t, dim, max_period=10000): """ Create sinusoidal timestep embeddings. :param t: a 1-D Tensor of N indices, one per batch element. These may be fractional. :param dim: the dimension of the output. :param max_period: controls the minimum frequency of the embeddings. :return: an (N, D) Tensor of positional embeddings. """ # <https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py> half = dim // 2 freqs = torch.exp( -math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half ).to(device=t.device) args = t[:, None].float() * freqs[None] embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1) if dim % 2: embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1) return embedding def forward(self, t): t_freq = self.timestep_embedding(t, self.frequency_embedding_size) t_emb = self.mlp(t_freq) return t_emb- 위의 코드를 통해서, sincos 함수 적용 + 2개의 MLP & GeLU layer 통과
- self.y_embedder: y(class) embedding
- self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
- block은 DiTBlock class로 들감
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size,
num_heads,
mlp_ratio=4.0,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
use_residual_block=False,
input_size=None, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(
hidden_size,
num_heads=num_heads,
qkv_bias=True,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size, window_size),
)
self.input_size = input_size
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
# approx_gelu = lambda: nn.GELU(approximate="tanh")
approx_gelu = lambda: nn.GELU() # for torch 1.7.1
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
self.window_size = window_size
def forward(self, x, c):
# c가 condition
# MLP를 통해서 shift와 scale factors를 생성
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
shortcut = x
x = self.norm1(x)
B = x.shape[0]
x = x.reshape(B, self.input_size[0], self.input_size[1], self.input_size[2], -1)
# Window partition
if self.window_size > 0:
X, Y, Z = x.shape[1], x.shape[2], x.shape[3]
x, pad_xyz = window_partition(x, self.window_size)
x = x.reshape(B, self.input_size[0] * self.input_size[1] * self.input_size[2], -1)
x = modulate(x, shift_msa, scale_msa)
x = x.reshape(B, self.input_size[0], self.input_size[1], self.input_size[2], -1)
x = self.attn(x)
# Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_xyz, (X, Y, Z))
x = x.reshape(B, self.input_size[0] * self.input_size[1] * self.input_size[2], -1)
x = shortcut + gate_msa.unsqueeze(1) * x
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x- self.adaLN_modulation(c).chunk(6, dim=1)
- 통해서, scale과 shift factors를 생성
- DiTBlock이 다 끝나면, DiT class에서 final layer로 들어감
- out_channels: 3이라서, coordinates 형태로 나옴
-
class FinalLayer(nn.Module): """ The final layer of DiT. """ def __init__(self, hidden_size, patch_size, out_channels): super().__init__() self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) self.linear = nn.Linear(hidden_size, patch_size * patch_size * patch_size * out_channels, bias=True) self.adaLN_modulation = nn.Sequential( nn.SiLU(), nn.Linear(hidden_size, 2 * hidden_size, bias=True) ) def forward(self, x, c): shift, scale = self.adaLN_modulation(c).chunk(2, dim=1) x = modulate(self.norm_final(x), shift, scale) x = self.linear(x) return x # (p, p, p, c)
- Loss 계산은, p_losses 함수에서
- losses = ((noise - eps_recon)**2).mean(dim=list(range(1, len(data_start.shape))))
- 위와 같이 계산됨. (noise 정도를 예측; MSE)

🐲Model Inference
gen = model.gen_samples(x.shape, gpu, new_y_chain(gpu,y.shape[0],opt.num_classes), clip_denoised=False).detach().cpu()
→ Model class에서 gen_samples 함수를 통해서 들어감
# gen_samples 함수
def gen_samples(self, shape, device, y, noise_fn=torch.randn,
clip_denoised=True, # False임
keep_running=False):
# GaussianDiffusion class
return self.diffusion.p_sample_loop(self._denoise, shape=shape, device=device, y=y, noise_fn=noise_fn,
clip_denoised=clip_denoised,
keep_running=keep_running)
# p_sample_loop 함수
def p_sample_loop(self, denoise_fn, shape, device, y,
noise_fn=torch.randn, clip_denoised=True, keep_running=False):
"""
Generate samples
keep_running: True if we run 2 x num_timesteps, False if we just run num_timesteps
"""
assert isinstance(shape, (tuple, list))
#### noise_fn = torch.randn
# img_t = 랜덤 노이즈 point cloud
img_t = noise_fn(size=shape, dtype=torch.float, device=device)
# keep_running = False
# self.num_timesteps = 1000
for t in reversed(range(0, self.num_timesteps if not keep_running else len(self.betas))):
t_ = torch.empty(shape[0], dtype=torch.int64, device=device).fill_(t)
img_t = self.p_sample(denoise_fn=denoise_fn, data=img_t,t=t_, noise_fn=noise_fn, y=y,
clip_denoised=clip_denoised, return_pred_xstart=False)
assert img_t.shape == shape
return img_t
- Sampling할 때, timesteps = 1000으로 설정함.
- p_sample_loop 함수는, p_sample을 timesteps 만큼 반복 수행한 것.
def p_sample(self, denoise_fn, data, t, noise_fn, y, clip_denoised=False, return_pred_xstart=False):
"""
Sample from the model
"""
model_mean, _, model_log_variance, pred_xstart = self.p_mean_variance(denoise_fn, data=data, t=t, y=y, clip_denoised=clip_denoised,
return_pred_xstart=True)
noise = noise_fn(size=data.shape, dtype=data.dtype, device=data.device)
assert noise.shape == data.shape
# no noise when t == 0
nonzero_mask = torch.reshape(1 - (t == 0).float(), [data.shape[0]] + [1] * (len(data.shape) - 1))
# Algorithm 2 -> Sampling
sample = model_mean + nonzero_mask * torch.exp(0.5 * model_log_variance) * noise
assert sample.shape == pred_xstart.shape
return (sample, pred_xstart) if return_pred_xstart else sample
# p_mean_variance 함수
def p_mean_variance(self, denoise_fn, data, t, y, clip_denoised: bool, return_pred_xstart: bool):
model_output = denoise_fn(data, t, y)
## self.model_var_type: fixedsmall
if self.model_var_type in ['fixedsmall', 'fixedlarge']:
# below: only log_variance is used in the KL computations
model_variance, model_log_variance = {
# for fixedlarge, we set the initial (log-)variance like so to get a better decoder log likelihood
'fixedlarge': (self.betas.to(data.device),
torch.log(torch.cat([self.posterior_variance[1:2], self.betas[1:]])).to(data.device)),
'fixedsmall': (self.posterior_variance.to(data.device), self.posterior_log_variance_clipped.to(data.device)),
}[self.model_var_type]
model_variance = self._extract(model_variance, t, data.shape) * torch.ones_like(data)
model_log_variance = self._extract(model_log_variance, t, data.shape) * torch.ones_like(data)
else:
raise NotImplementedError(self.model_var_type)
if self.model_mean_type == 'eps':
x_recon = self._predict_xstart_from_eps(data, t=t, eps=model_output)
if clip_denoised: # False
x_recon = torch.clamp(x_recon, -.5, .5)
model_mean, _, _ = self.q_posterior_mean_variance(x_start=x_recon, x_t=data, t=t)
else:
raise NotImplementedError(self.loss_type)
assert model_mean.shape == x_recon.shape == data.shape
assert model_variance.shape == model_log_variance.shape == data.shape
if return_pred_xstart: # True임.
return model_mean, model_variance, model_log_variance, x_recon
else:
return model_mean, model_variance, model_log_variance

- self.model_var_type: fixedsmall
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t) self.posterior_variance = posterior_variance # below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain self.posterior_log_variance_clipped = torch.log(torch.max(posterior_variance, 1e-20 * torch.ones_like(posterior_variance)))- posterior_variance는 DDPM에서 정의하는 variance 값
- (좀 더 디테일하게는, beta 값이 fixed 되어있으므로 위와 같이 정의할 수 있음)
- posterior_log_variance_clipped: variance의 log값
def _extract(a, t, x_shape):
"""
Extract some coefficients at specified timesteps,
then reshape to [batch_size, 1, 1, 1, 1, ...] for broadcasting purposes.
"""
bs, = t.shape
assert x_shape[0] == bs
out = torch.gather(a, 0, t)
assert out.shape == torch.Size([bs])
return torch.reshape(out, [bs] + ((len(x_shape) - 1) * [1]))
- model_variance = self._extract(model_variance, t, data.shape) * torch.ones_like(data)
- t부분에 해당하는 variance 추출하는 부분 (인 것 같음)
- self.model_mean_type: eps
- x_recon = self._predict_xstart_from_eps(data, t=t, eps=model_output)
- data: T 시점의 noised point cloud
- model_output: T 시점 noised point cloud에 대해서, 입혀진 noise 예측 값
def _predict_xstart_from_eps(self, x_t, t, eps): assert x_t.shape == eps.shape return ( self._extract(self.sqrt_recip_alphas_cumprod.to(x_t.device), t, x_t.shape) * x_t - self._extract(self.sqrt_recipm1_alphas_cumprod.to(x_t.device), t, x_t.shape) * eps )self.sqrt_recip_alphas_cumprod = torch.sqrt(1. / alphas_cumprod).float() self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1. / alphas_cumprod - 1).float()- _predict_xstart_from_eps: Xt와 noise값을 활용해서 X0를 유추하는 단계 (위의 이미지 수식 참고)
- Question: sqrt_recipm1_alphas_cumprod의 분모가 alphas_cumprod - 1 인 것이지?
- 뭔가 위 수식에서 x0를 남기고 다 좌변으로 넘기는게 맞는 수식인 것 같은데..
- 아..분모는 그냥 alphas_cumprod이고 (1/alphas_cumprod) - 1 임..ㅋㅋㅋㅋ
- Question: sqrt_recipm1_alphas_cumprod의 분모가 alphas_cumprod - 1 인 것이지?
- model_mean, _, _ = self.q_posterior_mean_variance(x_start=x_recon, x_t=data, t=t)
-
def q_posterior_mean_variance(self, x_start, x_t, t): """ Compute the mean and variance of the diffusion posterior q(x_{t-1} | x_t, x_0) """ assert x_start.shape == x_t.shape posterior_mean = ( self._extract(self.posterior_mean_coef1.to(x_start.device), t, x_t.shape) * x_start + self._extract(self.posterior_mean_coef2.to(x_start.device), t, x_t.shape) * x_t ) posterior_variance = self._extract(self.posterior_variance.to(x_start.device), t, x_t.shape) posterior_log_variance_clipped = self._extract(self.posterior_log_variance_clipped.to(x_start.device), t, x_t.shape) assert (posterior_mean.shape[0] == posterior_variance.shape[0] == posterior_log_variance_clipped.shape[0] == x_start.shape[0]) return posterior_mean, posterior_variance, posterior_log_variance_clipped ########################### self.posterior_mean_coef1 = betas * torch.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod) self.posterior_mean_coef2 = (1. - alphas_cumprod_prev) * torch.sqrt(alphas) / (1. - alphas_cumprod)
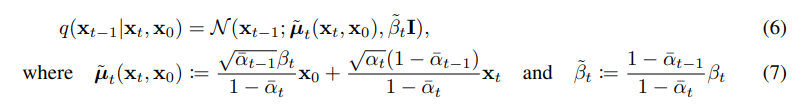
- model_mean = 위의 이미지의 mean 값에 해당하는 부분 (equation 7)
- x_start = X0에 해당하는값

- 마지막, DDPM에 나오는 algorithm 2 수식에 근거하여서 아래와 같이 t-1번째sampling을 시도함.
- sample = model_mean + nonzero_mask * torch.exp(0.5 * model_log_variance) * noise
DDPM의 원리가, decoder (denoising) 과정에서 encoder (diffusion)의 평균을 예측하도록 훈련
- → 즉 decoder의 분포는 encoder와 같아야 하므로, encoder의 분포를 기반으로
- 평균+분산*노이즈 형태가 됨
🐉Inference 요약
p_sample_loop [img_t: 랜덤 노이즈 point cloud]
→ p_sample [img_t의 노이즈를 T → T-1로 점점 줄여나가는 단계; Algorithm2]
→ p_mean_variance [t시점의 q분포의 Mean과 Variance 계산]
→ _predict_xstart_from_eps [Noise와 X_t를 기반으로, X0를 예측]
→ q_posterior_mean_variance [X0와 X_t를 바탕으로, q분포의 평균을 예측]
'AI > CV project' 카테고리의 다른 글
| [CIKM' 25 LOD] - Learnable Orthogonal Decomposition for Non-Regressive Prediction for PDE (3) | 2025.11.30 |
|---|---|
| [WANAlign2.1⚡- Awesome-Training-Free-WAN2.1-Editing] (1) | 2025.08.16 |
| [SMPL-X Implementation] KyujinHan/Smplify-X-Perfect-Implementation (30) | 2024.03.18 |
| [DDPM 코드 리뷰] (6) | 2023.12.30 |
| [Tune-A-VideKO] - 한국어 기반 One-shot Tuning of diffusion for Text-to-Video 모델 (0) | 2023.08.18 |



