*CogVideoX를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
CogVideoX paper: https://arxiv.org/abs/2408.06072
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
We present CogVideoX, a large-scale text-to-video generation model based on diffusion transformer, which can generate 10-second continuous videos aligned with text prompt, with a frame rate of 16 fps and resolution of 768 * 1360 pixels. Previous video gene
arxiv.org
CogVideoX github: https://github.com/THUDM/CogVideo
GitHub - THUDM/CogVideo: text and image to video generation: CogVideoX (2024) and CogVideo (ICLR 2023)
text and image to video generation: CogVideoX (2024) and CogVideo (ICLR 2023) - THUDM/CogVideo
github.com
Contents
- 3D Causal VAE
- Expert Transformer
- Explicit Uniform Sampling
Simple Introduction

최근 Diffusion Transformer(DiT)를 기반으로, 수많은 video generation 연구가 이루어지고 있습니다!
이때 많은 논문들이 backbone model로 CogVideo와 CogVideoX를 활용하고 있어서 video generation 분야에서는 반드시 알아야 할 논문이지 않을까 싶습니다.
CogVideoX는 기존과 다르게 DiT 기반으로 만들어진 text-to-video AI 모델로 엄청나게 핫한 모델인데
모델의 기본적인 아이디어와 구조에 대해서 같이 살펴봅시다!
Background Knowledge: DiT
Diffusion Transformer 논문 리뷰: https://kyujinpy.tistory.com/132
[Diffusion Transformer 논문 리뷰3] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 마지막 3편은 제 온 힘을 다하여서.. 논문리뷰를 했습니다..ㅎㅎ *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://ar
kyujinpy.tistory.com
*DiT 기반으로 만들어진 T2V 모델이기 때문에, 미리 알고 오시는 걸 추천드립니다.
(DiT를 알고 있다는 가정 하에 설명이 진행됩니다)
Method
Model Architecture
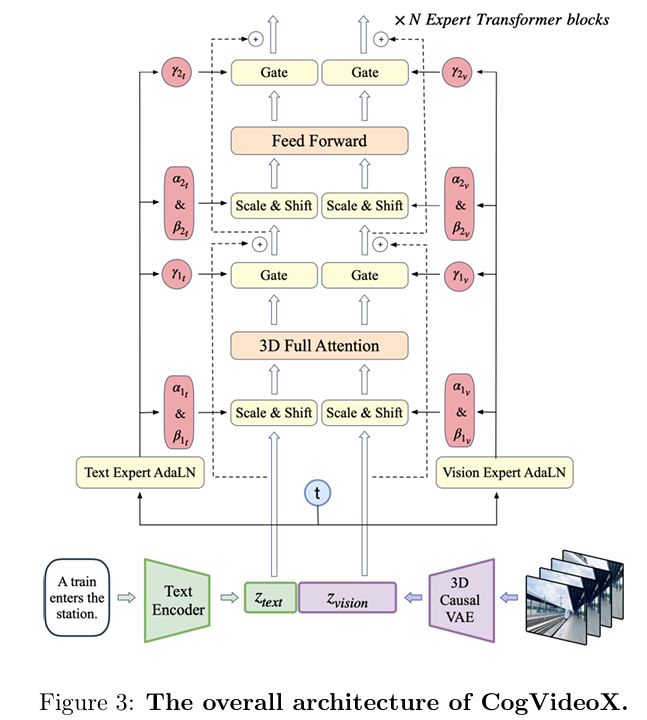
CogVideoX의 구조는 우리가 흔히(?) 알던 구조와 매우 유사합니다!
1. Video frames은 3D VAE Encoder를 통해서 vision embedding으로 생성
2. Text Embedding은 T5를 통해서 생성
3. 특이한 점으로, text와 vision embedding에 각각 다른 AdaLN을 적용
-> 위의 figure3에서 보면, text와 vision에 각각 다른 parameters들을 통해서 scale, shift, gate가 적용됨.
여기서 기존과 약간 다르다고 할 점은, 3D-VAE와 3D full attention입니다!
3D Causal VAE
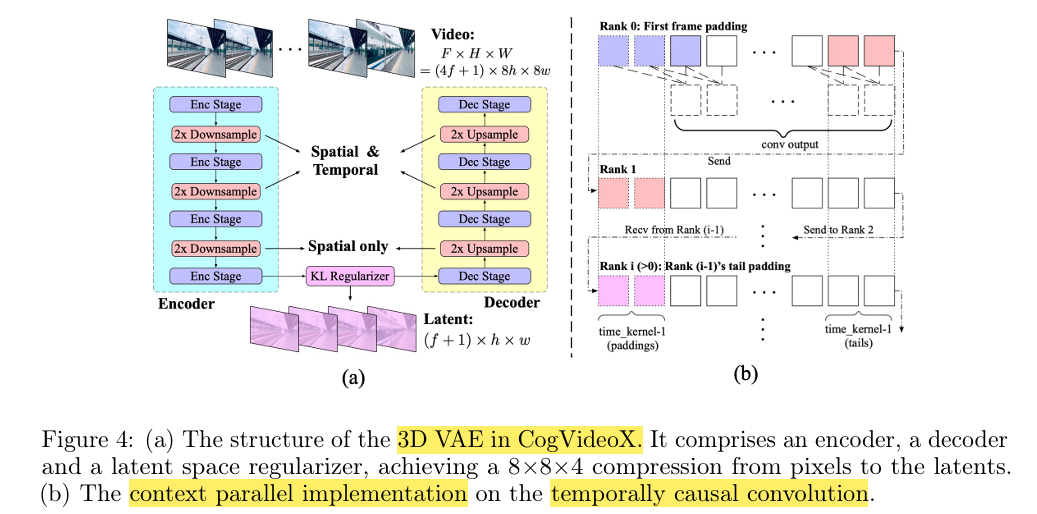
기본적으로, Encoder와 Decoder에서 보면 2x Downsampling이 적용되는 것을 볼 수 있습니다.
Spatial은 8배가 줄어들고, temporal은 4배가 줄어들게 되는 형태를 가집니다!
또한 channel의 경우에는 latent channel을 16으로 설정하게 됩니다.
즉 latent embedding은 figure 4를 토대로 ((f+1), h, w, 16)의 shape을 가지게 됩니다!
한가지 특이한 점으로, figure 4를 보면 temporally causal convolution을 적용하는 것을 확인할 수 있습니다.
해당 방법은, convolution 연산을 수행할 때 future information이 현재와 과거에 영향을 미치지 않도록 하는 효과가 있습니다!
(또한 앞에 padding space를 추가해서, 초기 frames에 대한 conv 연산을 수행할 때 도움을 줍니다.)
(*더불어서 context parallel implementation이 있는데, 해당 부분은 GPU memory usage와 관련해서 효율을 늘려주는 부분이라서 궁금하신 분들은 논문을 참고해주세요!)

3D-VAE training method로 two-stage를 제시하고 있는데
1. 256x256 resolution을 가진 17 frames의 video 활용
2. 161 frames의 video로 fine-tuning 진행
이때 특이하게 훈련 과정에서 256x256 resolution만 활용은 하는데, 그 이유는 저자들이 3D-VAE가 large resolution은 충분히 encoding할 수 있지만 long frames에 대해서는 잘 수행하지 못하는 걸 발견했기 때문이라고 합니다.
3D Full Attention (Expert Transformer)
그 다음으로는, CogVideoX의 main backbone를 구성하는 transformer 구조에 대해서 살펴보겠습니다!
아래에 언급되는 patchify+3D-RoPE+Expert AdaLN+3D full attention을 모두 더한 것이 expert transformer입니다.

Patchify는 3D VAE에서 나온 latent embedding (T, H, W, C)에 대해서 수행하게 됩니다.
(Channel dimension은 유지한채로 height, width에 대해서 patchify를 수행합니다; 논문에서는 q>1에 대한 가정이 있지만 거의 time은 안하신다고 생각하셔도 됩니다!)

3D-RoPE는 video가 가지는 차원 (x,y,t)에 대한 positional information을 효과적으로 주기 위해서 사용되었습니다!
기존 LLM에서 많이 쓰이던 RoPE를 3차원 버전으로 만든 것인데, 적용 방법은 각 (x,y,t)에 1D-RoPE를 적용하고 다시 concatenate하는 것으로 이루어집니다.
(- 논문에서는 (x,y,t)가 hidden states에서 3/8, 3/8, and 2/8의 비율로 channel을 구성하고 있다는데 정확한 dimension까지는 모르겠음.)
Exper AdaLN은 위의 architecture figure 보면서도 잠깐 언급했지만, text와 vision embedding에 대해서 각각 다른 adaLN을 적용해서 scaling을 하는 것을 말하는 구조입니다! (매우 간단하죠!?)


Expert Transformer가 가지는 큰 특징 중 하나가, 바로 3D Full Attention이지 않을까 싶습니다.
기존 수많은 연구에서, video나 3D가지는 spatial and temporal information을 잡기 위해서 spatial-attention과 temporal-attention 2개를 동시에 활용했습니다.
하지만 이럴 경우, 모델의 computation도 올라가고 위에 보이는 예시 이미지처럼 temporal attention과 spatial attention 간의 간극이 발생하기 때문에 consistent한 video를 생성하기 어렵다는 단점이 있었습니다.
그래서 CogVideoX에서는 temporal-spatial를 동시에 수행하는 hybrid transformer 구조를 제안했습니다.
[3D Full Attention에 대한 설명] (아래 간단한 내용 참고)
3D Full Attention 메커니즘은 되게 간단하다.
기존에 spatial attention은 (B, F, H, W)를 (BF, HW)로 생각해서 연산을 하는 것이고,
Temporal attention은 (BHW, F)로 생각해서 연산을 하는 것이다.
여기서 3D Full Attention은 (B, FHW)로 만들어서 attention 연산을 하는 것이다!
(*실제로는 patchify하고나서 image도 text처럼 seq_len이 존재할 것이고 더불어서 embed_dim으로 projection하는 단계도 있을 수도 있는데, 위의 예시는 아마 직관적인 dimension 이해를 돕기 위해서 예시를 든 것이 아닐까 싶다.)
Mixed Training

또 한가지 특징으로, 훈련할 때 image와 video간의 gap을 줄이기 위해서 [image, video]를 같이 활용합니다! (길이가 안 맞으면, padding을 활용)
그리고, 유동성을 위해서 multi-resolution으로 구성된 데이터셋을 활용하여 훈련을 진행합니다!
CogVideoX는 multi-stage training으로 구성되고 있습니다!
1. 256px Video로 훈련
2. 점진적으로 pixel을 늘려서 훈련 (512px, 768px)
3. 마지막으로, high-quality의 video subset만 따로 모아서 fine-tuning 진행
Explicit Uniform Sampling

마지막으로 살펴볼 것은, 바로 CogVideoX의 loss function입니다.
되게 어려운 말로 적혀있는 것 같지만, 제가 읽고 이해한 바로는 아래와 같이 간단하게 정리할 수 있습니다.
'기존에는 1~T 사이에서 랜덤한 t를 추출하는데, 이는 unifomly sampling을 기반으로 하지만 실제로는 그렇지 않을 수 있다. 따라서 [1, T]를 n개의 interval로 구분하고 각 interval에서 uniform하게 t를 추출해서 사용한다.'
이랬을 때, 실제로 훈련이 더 빠르고 잘 된다는 것을 ablation study에서 보여주고 있습니다!
Result


- 2025.03.16 Kyujinpy 작성.
(미루고 미루던 논문리뷰 한편 완성..ㅎㅎ)



