*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다!
*총 3편으로 구성되었고, 마지막 3편은 제 온 힘을 다하여서.. 논문리뷰를 했습니다..ㅎㅎ
*궁금하신 점은 댓글로 남겨주세요!
DiT paper: https://arxiv.org/abs/2212.09748
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our D
arxiv.org
DiT github: https://www.wpeebles.com/DiT
Contents
2. Background Knowledge: DiT Preview
- To embed conditional information
- Adaptive Layer Norm-Zero Block
Simple Introduction

Diffusion Transformer를 논문 리뷰하기 위해서 정말 많은 길을 달려왔다..
DDPM부터, CG, CFG 그리고 LDM 까지!!
이제는 DiT를 완벽히 이해하여, diffusion 마스터(?)가 되어보자!
Background Knowledge: DiT Preview
DiT Preview1: https://kyujinpy.tistory.com/131
[Diffusion Transformer 논문 리뷰1] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 2편으로 구성되었고, 1편은 DiT를 이해하기 위한 지식들을 Preview하는 시간입니다! *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://arxiv.or
kyujinpy.tistory.com
DiT Preview2: https://kyujinpy.tistory.com/133
[Diffusion Transformer 논문 리뷰2] - High-Resolution Image Synthesis with Latent Diffusion Models
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 2편은 DiT를 이해하기 위하여 LDM를 논문리뷰를 진행합니다! *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://arxiv.org
kyujinpy.tistory.com
*DDPM, classifier-guidance, classifier-free guidance, LDM에 대한 설명을 간략하게 담고 있습니다! 한번 보고 오시면 이해하는데 더 도움이 될 것이라고 생각합니다!
Method
Noised Latent & Patchify
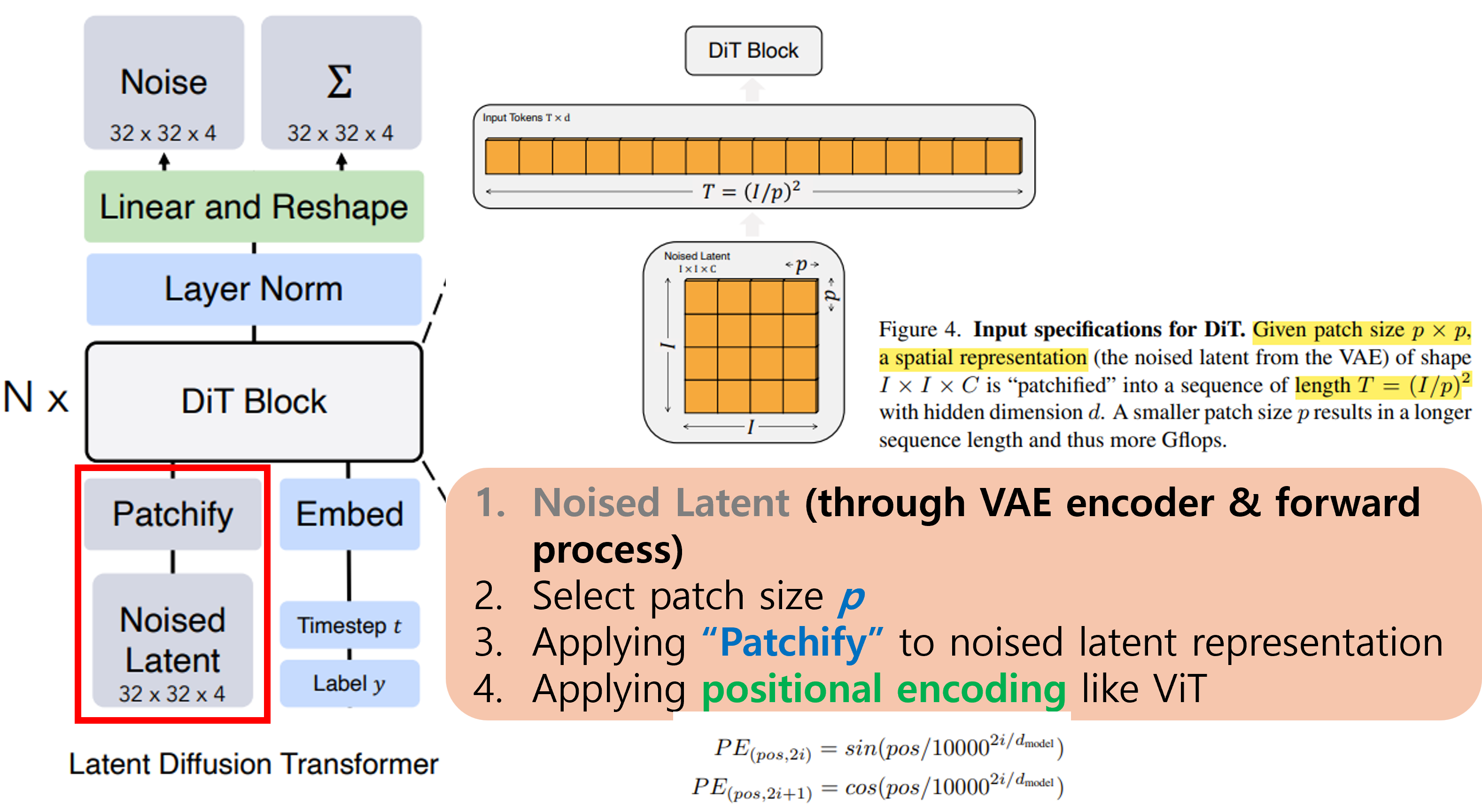
첫번째는 Noised Latent과 Patchify이다!
Latent Diffusion Model (LDM)이 혹시 기억나시나요!? (DiT 논문리뷰 2편에서 다뤘는데..!)
LDM에서는 image X를 VAE encoder에 넣어서 down sampling을 진행한 후에, noise를 더한 형태로 훈련을 진행했습니다!

LDM처럼 DiT도 처음에 Noised Latent을 생성합니다! (위의 이미지참고)
그리고 나서 Patchify를 진행합니다.
Patchify는 Vision Transformer (ViT)에서 다루는 개념인데, 첫번째 그림에서 figure4를 보시면 이해가 편합니다!
논문의 저자들인 patchify에 활용되는 p value를 2,4,8로 설정했다고 합니다!
그렇다면, input인 noised latent representation에서 patch size (pxp)로 분할시켜줍니다!
위의 과정을 수행했다면, patch token의 개수 T는 (I/p)^2 일 것입니다!
여기서 만들어진 patch들을 flatten하게 만들어주고, ViT에서 적용한 sincos positional encoding 방법을 적용하여 Txd shape의 noised latent sequence vector를 생성합니다.
To embed conditional information

우리가 앞선 논문 리뷰에서 살펴봤던 CFG(classifier-free guidance)나 CG(classifier-guidance)처럼 conditional training을 진행할 때는 timestep뿐만 아니라 label 정보 y도 함께 이용해야한다.
따라서, DiT에서는 Embed라는 layer를 통해서 해당 정보를 noise-patch sequence와 같이 DiT Block에 넣어준다.
Embed layer는 appendix에 언급되어 있는데 다음과 같다.
1. 2개의 MLP로 구성
2. SiLU activation이 적용되어 있고, 중간 hidden layer는 transformer's hidden size (DiT 내부에서 사용되는 transformer)와 같다.
3. Output dimension은 256이다.
다음은 DiT의 꽃인 adaLN-Zero Block에 대해서 얘기해보겠다.
Adaptive Layer Norm-Zero Block

Adaptive Layer Norm(adaLN)을 얘기하기전에, FiLM 논문을 잠깐 보고 가자.
해당 논문에서는, CNN layer 중간에 shift와 scale vector를 활용하는 방법론을 소개하고 있다.
여기서 scale값은 앞에 나온 vector에 곱해주는 역할이고, shift는 더해주는 역할이다.
위의 equation (2)를 참고하면 한번에 이해가 될 것이다!

FiLM을 소개한 이유는, FiLM에서 나온 linear modulation 방법을 LN (layer normalization)에 적용한 형태가 바로 adaLN이라고 부르는 것이다! 차이점을 좀 더 구체적으로 설명해보겠다.
기존 LayerNorm의 경우, channel 단위로 normalization을 진행하고, learnable parameters인 shift와 scale를 활용했다.
그러나, DiT에서 사용되는 adaLN의 경우에는 직접적으로 learnable하는 것이 아닌, timestep과 label의 embedding을 shift와 scale값으로 활용한다는 것이다!
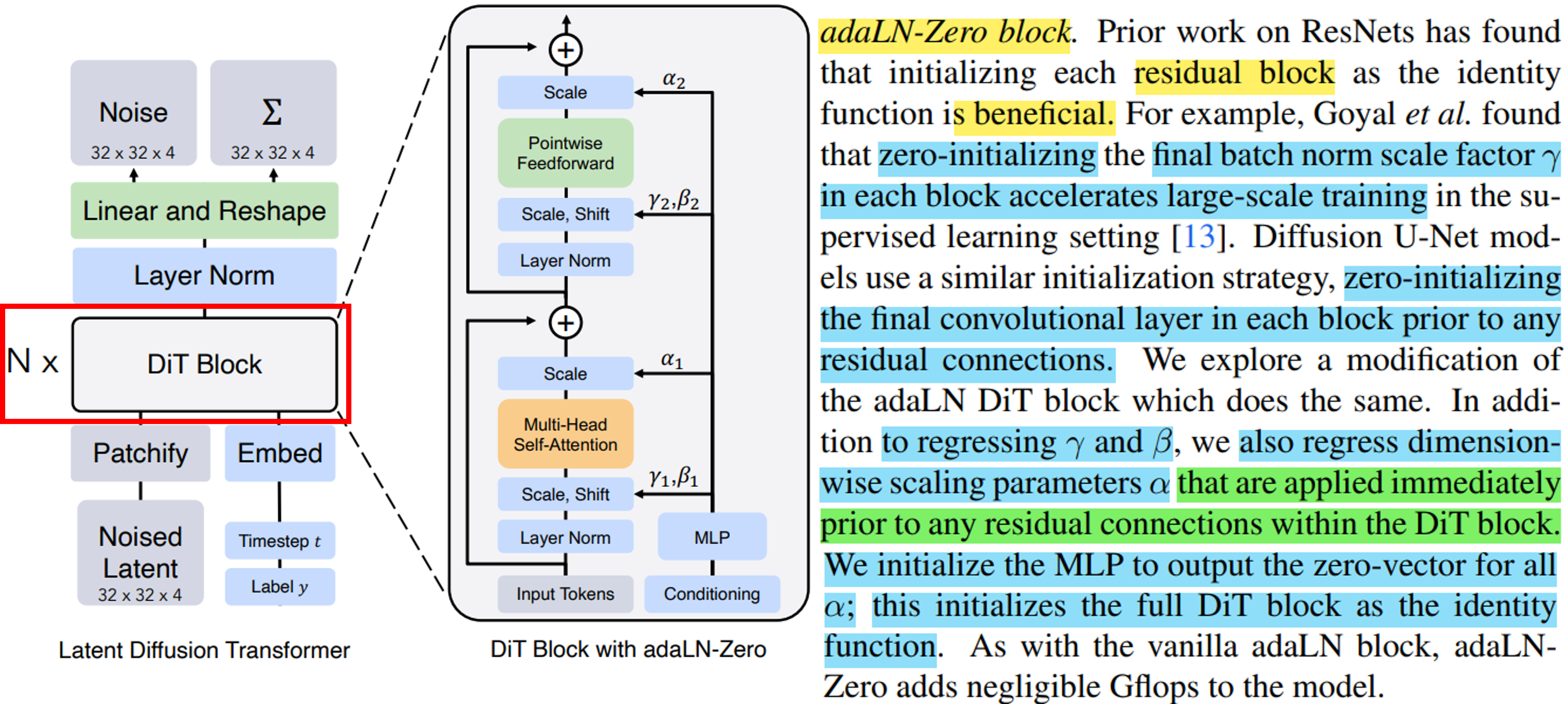
그렇다면 adaLN-Zero는 무엇인가!? 아래에 순차적으로 설명해보겠다.
1. adaLN은 각 2개의 shift와 scale factor가 필요했다. 즉 총 4개의 embedding vector가 MLP로 출력되는 것이다.
2. 그러나 adaLN-Zero는 scale factor a를 추가하여서 총 6개의 output이 나오도록 모델 구조를 설계하였다.
3. 또한 이 scale factor a의 초깃값을 zero로 두고 시작하기 때문에, adaLN-Zero라고 이름이 붙였다.
(Zero로 시작하는 이유는, Goyal et al. 논문의 연구를 참고했다고 언급하고 있다.)
또한 a가 0이기 때문에 input_tokens 값만 살아남게 되므로, 논문에서 언급하는 것처럼, 처음 DiT block은 identity function이다.

+) DiT block 안에 있는 MLP들은 SiLU와 linear layer를 적용하는데, adaLN 또는 adaLN-Zero인지에 따라서 output 차원이 달라진다. adaLN-Zero일 경우에는 transformer's hidden size의 6배에 해당하는 vector를 출력하게 된다.
+) Timesteps과 layer 정보에 대하여 embed로 들어오면 서로 dim-256 사이즈의 vector인데, 두 개의 vector를 더한 상태로 MLP에 넣어주게 된다.
Transformer Decoder

마지막은 Transformer Decoder이다.
굉장히 쉬운 내용이다.
LayerNorm 적용하고, linear와 reshape을 적용한 다음에 각 patch size (pxp)마다 기존 channel size의 2배가 되는 output을 출력한다.
따라서 output은 위에서 보는 것처럼, 예측된 noise 값과 covariance 값이다.
그 이후, VAE decoder에 noise 값을 넣어서 실제 이미지를 생성한다.

여기서 추가적으로, 왜 covariance를 생성하는지 한번 얘기해볼까 한다.
사실 이 내용은, DiT 이전에 classifier-guidance에 소개된 ADM과 연관이 있다.
ADM의 경우 DDPM 처럼 noise간의 차이만 loss로 이용한 것이 아니라, 분산도 학습을 진행했다.
또한 분산에 대한 loss로 vlb_loss를 활용한다. (VLB: variational lower bound)
자세한 내용은 위의 이미지를 참고하면 좋다!
(또는 Improved Denoising Diffusion Probabilistic Models 논문 참고)

+) VLB loss관한 코드이다.
Summary
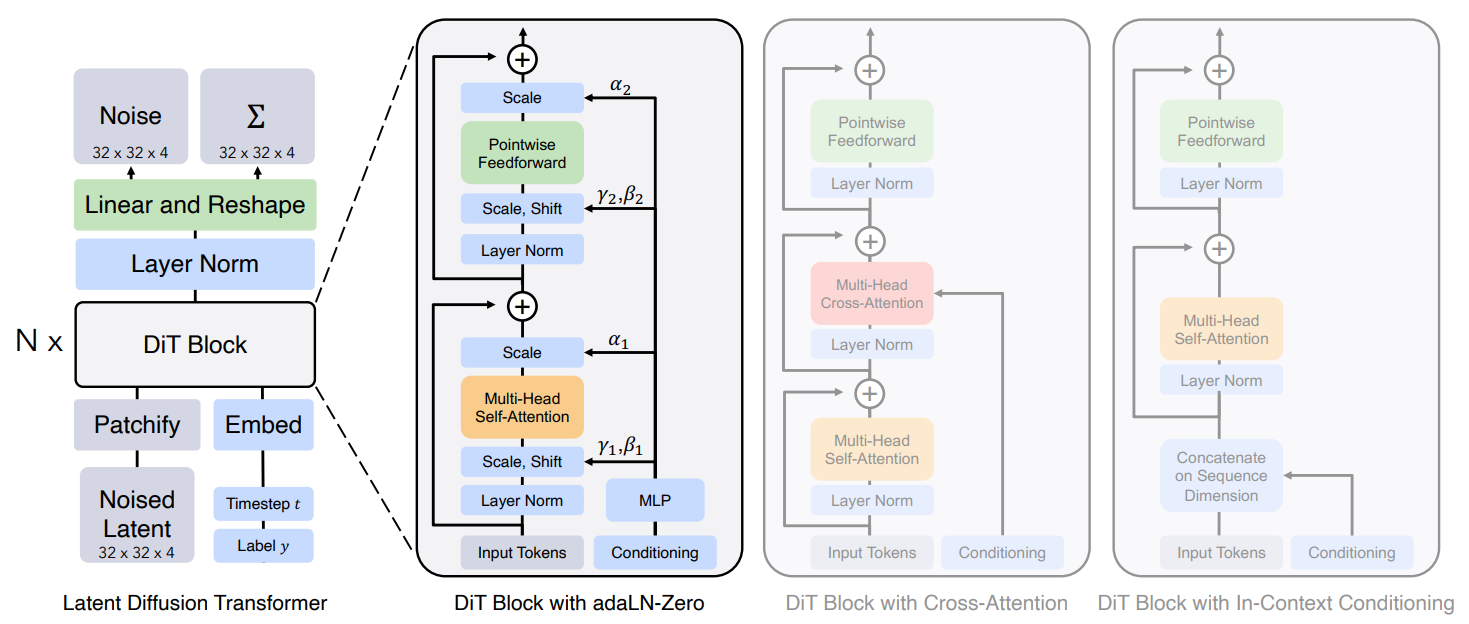
위의 이미지를 보면서, 위에서 같이 얘기를 나눴던 내용들을 연결시켜보길 바란다!
DiT는 기존의 UNet 기반의 diffusion model과 다르게, transformer 기반의 Diffusion model을 소개한 논문으로 매우 의의가 깊다.
또한 transformer와 더불어서 여러 테크닉을 담고 있는 adaLN layer를 소개하면서 연산과정에서 효율성도 챙겼다.
DiT를 적용한 논문들이 계속해서 나오고 있고 DiT의 발전형 모델도 계속해서 나오는 것을 보면, 앞으로의 diffusion model은 무조건 DiT 기반이지 않을까 싶다.

+) 논문에서 In-context conditioning과 Cross-attention block에 대한 구조 설명도 하긴 했는데, 바로 직관적으로 이해할 수 있거나 LDM에서 소개된 방법이여서 생략한다..!
Result

- adaLN-Zero layer가 효율적이라는 것을 FID score를 보여주고 있다.

- 256x256와 512x512 이미지 사이즈에 따른 score를 보면 FID와 IS가 좋은 것을 확인할 수 있다.
SORA Example

Prompt: An extreme close-up of an gray-haired man with a beard in his 60s, he is deep in thought pondering the history of the universe as he sits at a cafe in Paris, his eyes focus on people offscreen as they walk as he sits mostly motionless, he is dressed in a wool coat suit coat with a button-down shirt , he wears a brown beret and glasses and has a very professorial appearance, and the end he offers a subtle closed-mouth smile as if he found the answer to the mystery of life, the lighting is very cinematic with the golden light and the Parisian streets and city in the background, depth of field, cinematic 35mm film.
- 인물의 사실적인 모습과 더불어서, 안경을 통해 들어오는 빛의 굴절 표현까지 깔끔하다..ㅎㅎ
- 2024.02.28 Kyujinpy 작성.



