*LRM를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
LRM paper: https://arxiv.org/abs/2311.04400
LRM: Large Reconstruction Model for Single Image to 3D
We propose the first Large Reconstruction Model (LRM) that predicts the 3D model of an object from a single input image within just 5 seconds. In contrast to many previous methods that are trained on small-scale datasets such as ShapeNet in a category-spec
arxiv.org
LRM page: https://yiconghong.me/LRM/https://yiconghong.me/LRM/
LRM: Large Reconstruction Model for Single Image to 3D
We propose the first Large Reconstruction Model (LRM) that predicts the 3D model of an object from a single input image within just 5 seconds. In contrast to many previous methods that are trained on small-scale datasets such as ShapeNet in a category-spec
yiconghong.me
Contents
Simple Introduction

최근 컴퓨터 비전 분야에서는 한 장의 이미지로 3D object를 만드는 연구가 매우 뜨겁다.
해당 연구의 기반에는 항상 NeRF와 Gaussian splatting이 있다!
NeRF는 다양한 각도를 가진 N장의 이미지를 통해서 3D scene (object)를 만든다.
그렇다면, 어떻게 단 한 장의 이미지로 3D object를 생성할 수 있을까!?
(그나마)최근에 나온 single image-to-3D에서 유명한 모델로, TripoSR이 있다.
Stable-diffusion에서 해당 모델을 공개했는데, LRM 구조가 기본 구조이다!
현재 Single Image-to-3D 분야에서는 LRM이 기본이 되는 모델이므로 함께 알아보자!
(가우시안 splatting은 나중에 simple review 해볼께요..!)
Background Knowledge: NeRF
NeRF 논문 리뷰: https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
*NeRF 안에서 활용되는, camera parameters에 대한 개념이 잡혀있으시면 이해하시기 편합니다!
Method
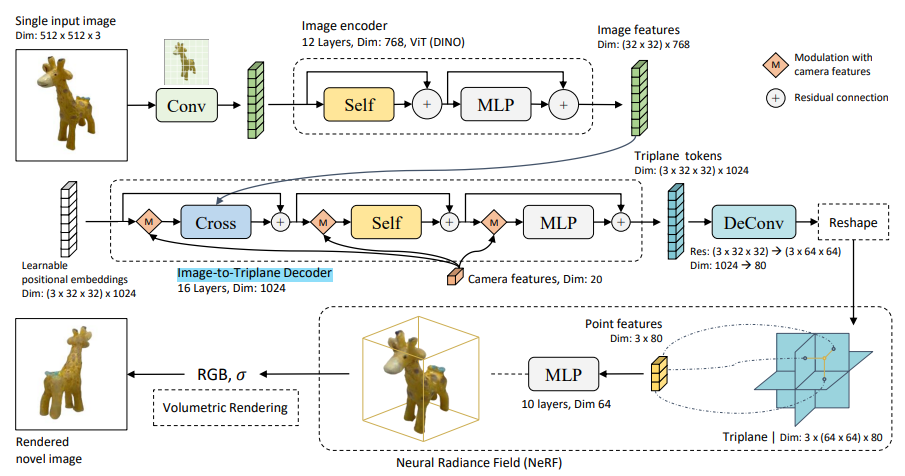
모델 구조를 보면, LRM은 총 3단계 pipeline으로 구성되어 있다.
1. Image Encoder
2. Image-to-Triplane-Decoder
3. Triplane-NeRF
각각이 어떠한 기능을 가진 구조인지 함께 살펴보자!
Image Encoder
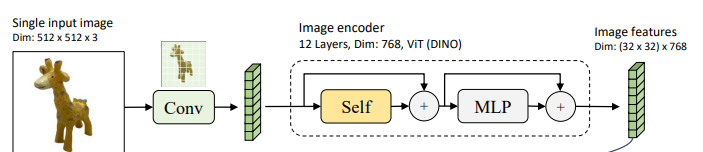


Image Encoder는 DINO에서 제안한 image-encoder의 weight를 사용한다.
해당 모델을 통해서, singe input image가 가지고 있는 image feature를 얻는 것이 포인트이다!
Image-To-Triplane-Decoder
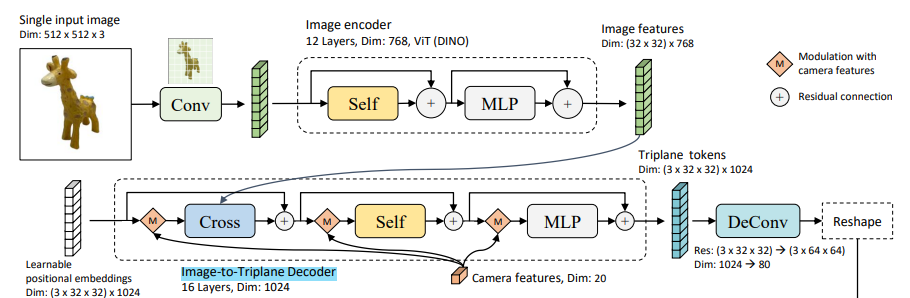
Image-to-3D plane 구조는 image의 position에 대한 정보를 학습한다!
구조는 아래와 같다.
1. Learnable positional embeddings 생성.
2. Camera features 정의
- 20 차원
- extrinsic parameters (camera-to-word로 transformation 해주는 matrix)는 4x4 matrix이므로(3차원 변환이므로), 해당 벡터를 flatten하여서 16차원으로 생성.
- 카메라의 focal length x, y (각각 1차원)
- Principal point pp x, y (각각 1차원)
3. 해당 camera features를 각 cross-attn, self-attn, MLP layer에 들어가기 전에 merge하여 features 생성하도록 함.
4. 최종적으로 Triplane token이 생성됨!
- (3x32x32)x1024
- 여기서 3은 triplane을 의미, 1024는 channel!
- 32x32는 각 plane (xy, xz, yz)의 공간 크기.
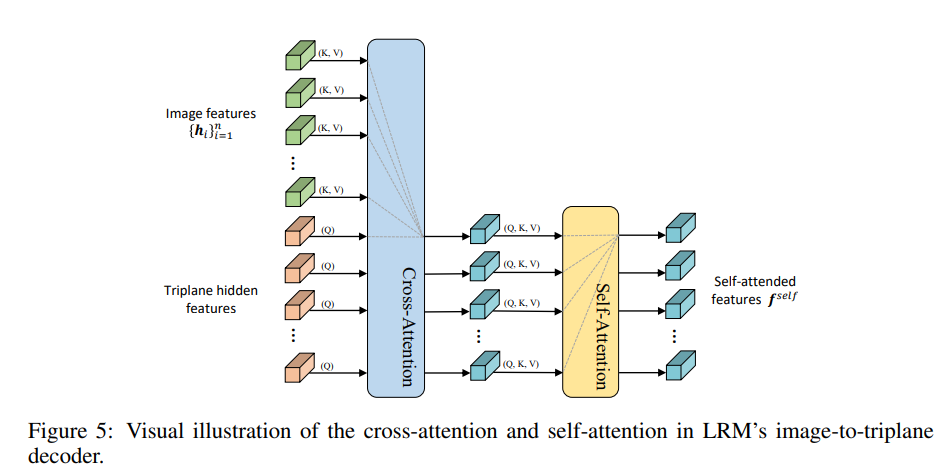
+) 위의 구조에서 활용된 cross-attn의 구조이다!
+) Image features가 key, value로 활용되고, triplane hidden features가 query로 활용된다.
즉, 논문의 아이디어는 "camera parameters의 값만을 가지고 learnable positional embeddings을 학습함으로써, 다양한 각도에 대한 이미지의 triplane features(tokens)을 학습"한다는 것이다
(+참고: 기존 NeRF는 camera parameters 뿐만 아니라, camera parameters에 해당하는 이미지로 부터 ray를 생성하는 작업이 있어야 했음.)


마지막 단계로, DeConv를 수행하여서 각 plane의 크기를 64x64로 늘렸다.
또한 이 과정에서 channel dimension을 1024에서 80으로 줄인다!
Triplane-NeRF



Triplane NeRF는 어렵지 않다! (사실 위에 내용도 어렵지 않다(?))
위에서 만든, 3x64x64의 triplane에서 각 point마다 dimension을 bilinear interpolation을 통해서 3x80으로 만든다!
그리고 MLP network에서 넣어서 density와 colors(3-dim)을 output으로 학습한다!

+) Loss functions으로는 MSE와 LPIPS를 동시에 활용해서 비교한다!

+) 한가지 특이한 점으로, transformer block에서 MLP 대신 ModLN이라는 layer를 활용한다.
+) Diffusion Transformer에 보면, Layer-Norm block을 통해 학습되는 shift와 scale factor를 따로 embedding layer를 통해서 learnable하도록 설정했다. (adaLN block)
+) ModLN도 이와 유사한 아이디어를 적용한 layer로 이것을 transformer block에 접목했다.
+) Diffusion Transformer 논문 리뷰: https://kyujinpy.tistory.com/132
Result

- 기존의 대표적인 single-image-to-3D 모델인 One-2-3보다 성능이 더 좋다는 것을 볼 수 있다.
- 2024.05.03 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다! 인증 글도 계속해서 작성하겠습니다 ㅎㅎ



