*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다!
*총 3편으로 구성되었고, 1편은 DiT를 이해하기 위한 지식들을 Preview하는 시간입니다!
*궁금하신 점은 댓글로 남겨주세요!
DiT paper: https://arxiv.org/abs/2212.09748
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our D
arxiv.org
DiT github: https://www.wpeebles.com/DiT
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion T
www.wpeebles.com
Contents
2. Background Knowledge: DDPM, Vision Transformer
- Classfier-Free Guidance Preview
- Latent Diffusion Model (LDM)
Simple Introduction

최근 OpenAI가 SORA를 발표하면서 엄청난 화두에 올랐다.
여기서 더 핫해진 것은 SORA의 기반 모델이 Diffusion Transformer 였다는 사실이다!
와우..! 기존 Diffusion 모델은 UNet을 결합하여 generation 분야에서 활발히 활동하였다.
(물론 attention은 이용되긴 했지만..ㅎㅎ)
하지만, Transformer와 결합한 구조의 Diffusion은 정말 놀랍다!
더 자세히 말하면, Vision Transformer인 것이다.
한번 같이 살펴보자!
Background Knowledge: DDPM, Vision Transformer
DDPM 논문리뷰: https://kyujinpy.tistory.com/95
[DDPM 논문 리뷰] - Denoising Diffusion Probabilistic Models
*DDPM를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! DDPM paper: https://arxiv.org/abs/2006.11239 Denoising Diffusion Probabilistic Models We present high quality image synthesis results using diffusion probabilistic m
kyujinpy.tistory.com
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
*DDPM의 수식과, Vision Transformer의 개념을 모른다면, 따라가기 어려우실 수 있습니다!
Method
DDPM Preview






Classifier Guidance Preview
Paper: Diffusion Models Beat GANs on Image Synthesis
Link: https://arxiv.org/abs/2105.05233
Diffusion Models Beat GANs on Image Synthesis
We show that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models. We achieve this on unconditional image synthesis by finding a better architecture through a series of ablations. For conditional imag
arxiv.org



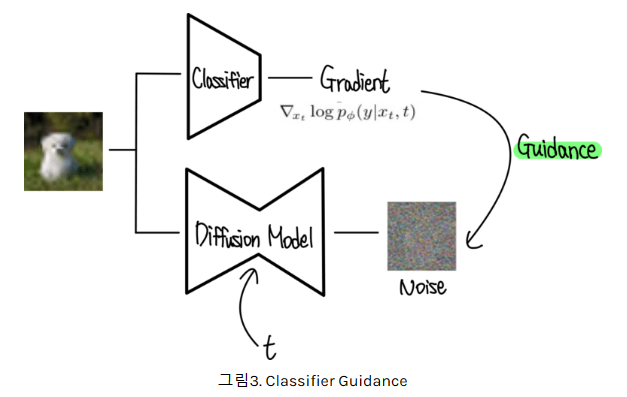
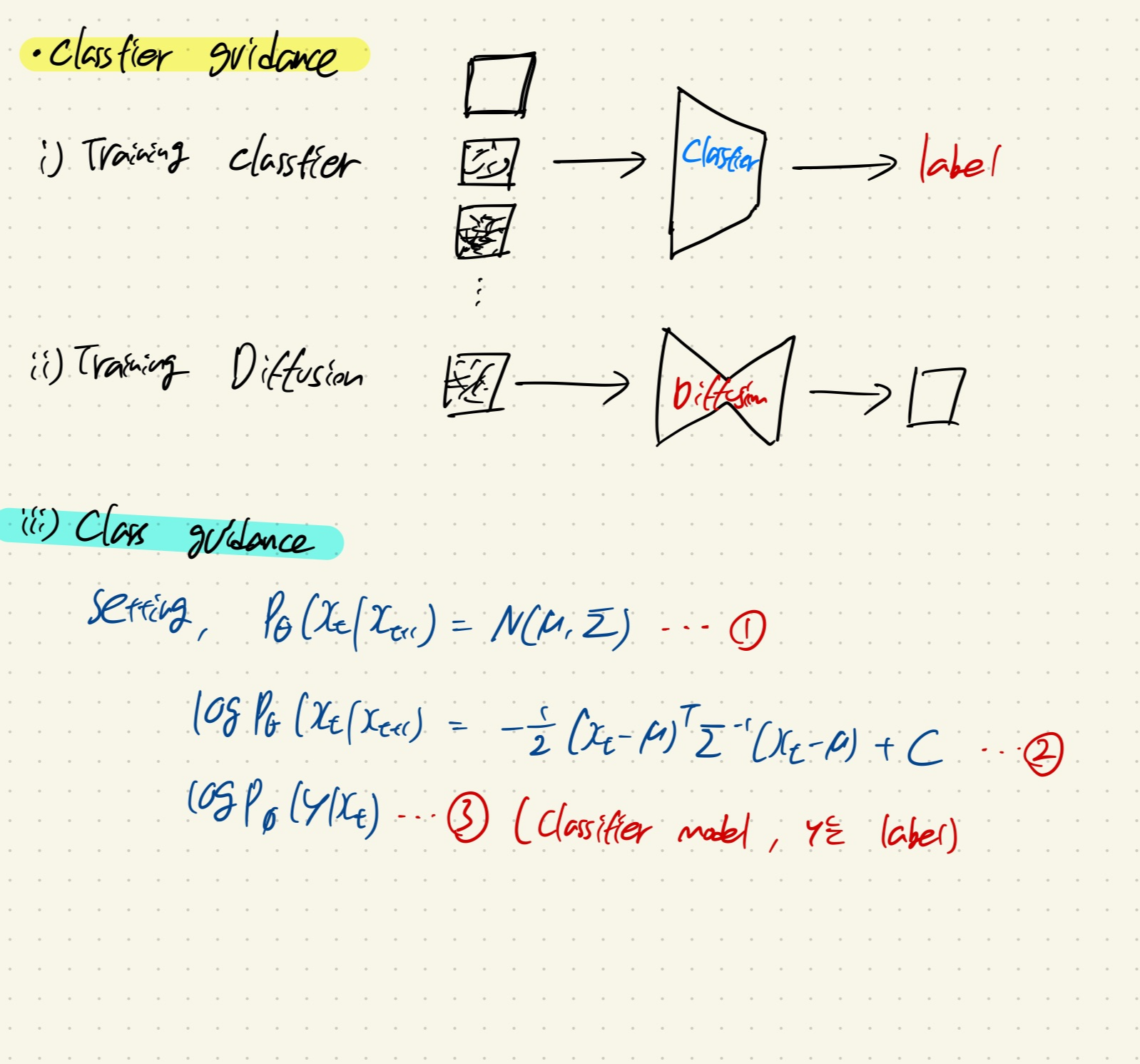

Classifier Guidance에서 기억할 것은,
label y로 conditional하게 이미지를 sampling하는 과정이다.
해당 과정은 Xt와 y를 이용하여 얻은 classifier의 gradient value g를 기존 DDPM 모델 sampling 과정의 평균 u에 더해주는 것이다!
논문에서는 mean shifting이라고 표현한다! 그러므로 class y에 대한 이미지로 guidance 해주게 되는 것이다!
(매우 신기하지 않나요!?)
+) 실제로 sampling할 때는 algorithm1 처럼, classifier guidance의 strength를 결정하는 s를 classifier의 gradient에 곱해줘서, 강도를 조절합니다!
Classifier-Free Guidance Preview

해당 논문은 위의 classifier guidance처럼 classifier를 만들지 않고, 훈련하는 방법이다.
즉 unconditional Diffusion model만 가지고 특정한 라벨 c로 guide될 수 있도록 훈련하는 방법을 소개한다.
위의 이미지에서 특별하게 Puncond라는 부분이 보일 것이다.
Puncond를 활용하여, 특정한 라벨 c를 뽑아내고, forward process에서 만들어진 Zt와 시간 t, 그리고 c를 함께 활용하여 모델을 훈련시킨다.


여기서 특이한 점은 3가지가 있다.
1. unconditional model과 conditional model 2개를 동시에 훈련시키는 방향으로 간다.
2. 여기서 unconditional model을 훈련시킬 때, 간단하게 null token을 추가한다.
3. Puncond는 hyperparameter로 설정한다! (논문에서는 0.5로 설정한다)
-> 즉, conditional model을 훈련하는 것 대신에 hyperparameter로 설정하는 것!
-> Non-conditional diffusion model을 학습할 때 이용되는 null token의 값이 0.5라는 의미인 것 같다.

또한, 논문의 저자들은 w=0일 때를 non-guide model이라고 정의하였다.
생각해보면, w=0이 됨으로써 null-token을 넣었을 때의 noise 값이 전혀 반영되지 않기 때문이다. (위의 equation 6참고)
+) label c는 주로 text인데, 이것에 대해서는 주로 clip이나 T5와 같은 text_embedding을 사용한다.
+) CFG 방법론은 정말 다양히 쓰이고 있고, diffusion을 활용한 generativeAI는 요즘 다 CFG 구조이다.
Latent Diffusion Model (LDM)
LDM 논문리뷰: https://kyujinpy.tistory.com/133
[Diffusion Transformer 논문 리뷰2] - High-Resolution Image Synthesis with Latent Diffusion Models
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 2편은 DiT를 이해하기 위하여 LDM를 논문리뷰를 진행합니다! *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://arxiv.org
kyujinpy.tistory.com
LDM은 diffusion을 활용한 generative AI의 시대를 열었다고 해도 과언이 아닐정도로 반드시 짚고 넘어가야 하는 모델이다!
*모든 준비가 끝났다면! LDM 논문소개로 가시죠!
- 2024.02.06 Kyujinpy 작성.



