Technical Report: Video generation models as world simulators (openai.com)
Video generation models as world simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that oper
openai.com
SORA: https://openai.com/sora
Sora: Creating video from text
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie m
openai.com
Turning visual data into patches
우리는 인터넷 규모의 데이터에 대한 훈련을 통해 제너럴리스트 기능을 습득하는 대규모 언어 모델에서 영감을 얻었습니다.13,14 LLM 패러다임의 성공은 부분적으로 텍스트 코드, 수학 및 다양한 자연어의 다양한 양식을 우아하게 통합하는 토큰을 사용함으로써 가능했습니다. 이 작업에서는 시각적 데이터의 제너레이티브 모델이 이러한 이점을 어떻게 계승할 수 있는지 살펴봅니다. LLM에는 텍스트 토큰이 있는 반면, 소라에는 시각적 패치가 있습니다. 패치는 이전에 시각 데이터 모델에 효과적인 표현으로 밝혀진 바 있습니다.15,16,17,18 우리는 패치가 다양한 유형의 동영상과 이미지에서 생성 모델을 훈련하는 데 확장성이 높고 효과적인 표현이라는 것을 발견했습니다.

높은 수준에서는 먼저 동영상을 저차원 잠재 공간으로 압축한 다음19 시공간 패치로 표현을 분해하여 동영상을 패치로 변환합니다.
(*ViT와 동일한 visual patches를 언급하는 내용 같다)
Video compression network
시각 데이터의 차원을 줄이는 네트워크를 훈련합니다.20 이 네트워크는 원본 비디오를 입력으로 받아 시간적, 공간적으로 압축된 잠재적 표현을 출력합니다. 소라는 이 압축된 잠재 공간 내에서 비디오를 학습한 후 생성합니다. 또한 생성된 잠상을 픽셀 공간에 다시 매핑하는 해당 디코더 모델을 학습시킵니다.
(*모델 구조를 공개해주면 확실히 이해할 것 같은데.. 여기는 그냥 VAE 구조를 학습한다는 말 인 것 같다..)
Spacetime latent patches
압축된 입력 비디오가 주어지면, 트랜스포머 토큰 역할을 하는 시공간 패치 시퀀스를 추출합니다. 이미지는 단일 프레임의 비디오에 불과하기 때문에 이 방식은 이미지에서도 작동합니다. 패치 기반 표현을 통해 Sora는 다양한 해상도, 길이, 화면 비율의 비디오와 이미지를 학습할 수 있습니다. 추론 시에는 무작위로 초기화된 패치를 적절한 크기의 그리드에 배열하여 생성된 비디오의 크기를 제어할 수 있습니다.
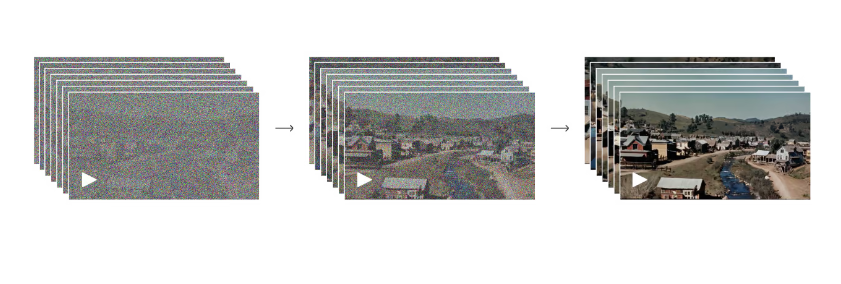
Scaling transformers for video generation
Sora는 확산 모델21,22,23,24,25로, 노이즈가 있는 패치(및 텍스트 프롬프트와 같은 컨디셔닝 정보)가 입력되면 원래의 "clean" 패치를 예측하도록 훈련됩니다. 중요한 점은 Sora가 diffusion transformer라는 점입니다.26 트랜스포머는 언어 모델링,13,14 컴퓨터 비전,15,16,17,18 및 이미지 생성 등 다양한 영역에서 놀라운 확장성을 입증했습니다.27,28,29
References
15) Vision Transformer
16) Vivit: A video vision transformer.
20) VAE: Auto-Encoding Variational Bayes
26) Scalable diffusion models with transformers. (DiT)



