*MoE를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
MoE paper: https://arxiv.org/abs/2101.03961
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of par
arxiv.org
Contents
2. Background Knowledge: Transformer
Simple Introduction
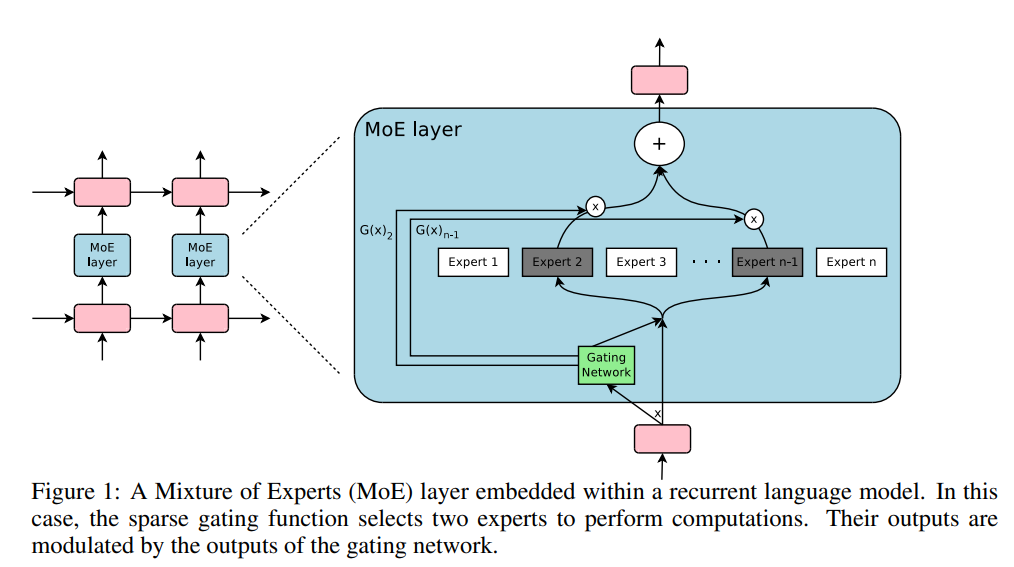
요즘 MoE 방법론이 굉장히 핫하다.
GPT-4에 MoE 방법론이 적용되고, 이후에 Mixtral이 등장하면서 MoE에 대한 사람들의 관심은 엄청 높아지고 있다.
MoE는 Mixture of Experts의 약자로, 말 그래도 Experts를 혼합한 것이다.
과연 이게 무슨 뜻일까?
이번 논문 리뷰는, transformer+MoE에 관한 얘기를 주로 할 예정이다.
Background Knowledge: Transformer
Transformer 논문리뷰: https://kyujinpy.tistory.com/2
[Transformer 논문 리뷰] - Attention is All You Need (2017)
*Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Transformer paper: https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex r
kyujinpy.tistory.com
*Transformer를 좀 더 깊게 이해하는데 도움이 됩니다!
Method
Overview MoE
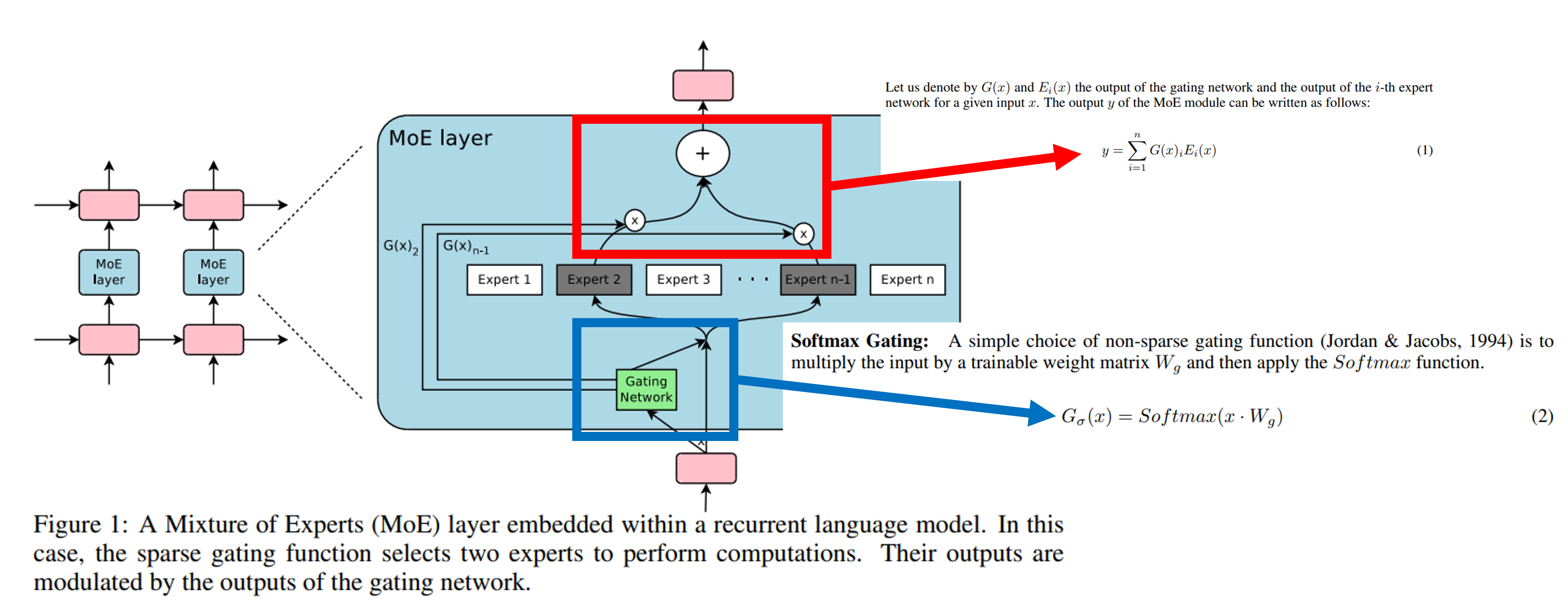
기존 MoE는 위와 같다.
여기서는 Softmax Gating(파란색)과 MoE의 최종 output vector(빨간색)이 위와 같은 수식으로 활용된다.
여기서 Softmax를 적용한 이유는, experts를 선택할 때 sparse하게 치우치는 걸 막기 위함이다.

여기서 또 궁금한 점이, 그렇다면 어떻게 2개 이상의 experts를 선택하는가?에 대한 질문이다.
이는 Top-K gating을 통해서, 내가 선택하고자 하는 experts의 개수 K를 선택한 후, 이를 제외한 나머지는 모두 음의 무한대로 치환하는 방법이다. (KeepTopK layer)
추가적으로 Normalization과 Softplus를 적용한다.

Switch Transformer (Transformer with MoE)
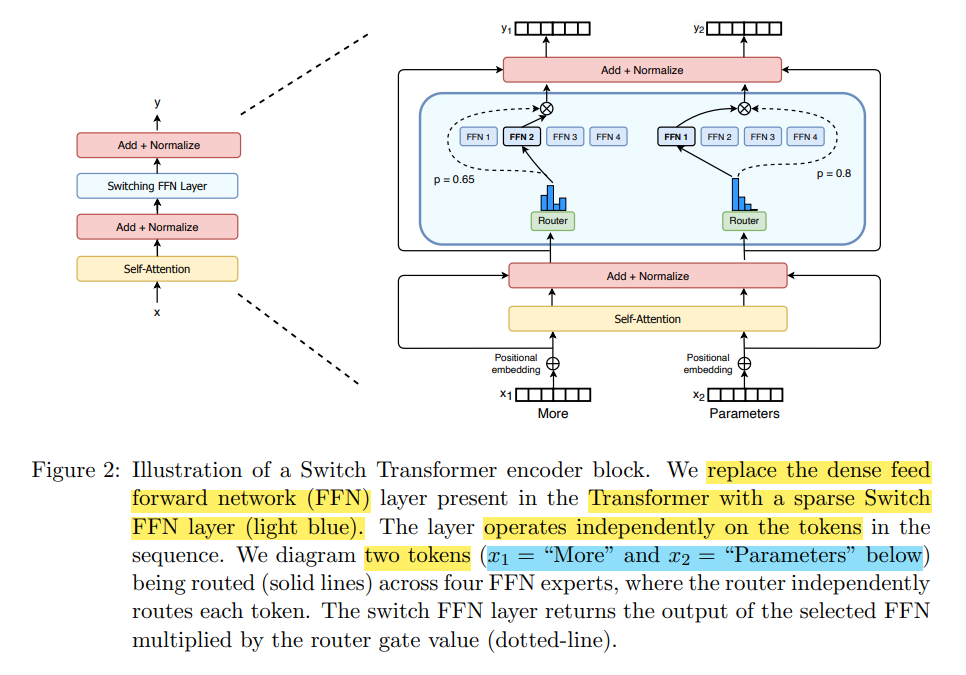

기존의 Transformer에서 있던 FFN layer를 Switch FFN layer로 교체한것이다!
위에 보이는 수식은 우리가 앞서 봤던 MoE 수식과 똑같다!
또한 우리는 여기에서, 각각의 token 별로 활성화되는 experts가 다르기 때문에, sparsely-activated MoE 모델이라고 부를 수 있다!
위와 같은 sparsely-activated한 모델의 변형은, experts의 부분집합이 토큰 별로 선택되어 훈련되기 때문에, 여러 도메인에서 뛰어난 확장성을 보여줍니다!
그렇다면, experts를 선택하는 router는 어떻게 학습하였을까!?

첫번째로 float32 precision을 router학습할 때 활용하였다.
그 이유는, 학습의 안정성이 이유이다. MoE는 sparse한 구조이기 때문에 기존의 dense 모델보다 불안정하다.
해당 논문에서는 bfloat16으로 학습할 경우 학습의 불안정성을 주고, float32로 모든 layer를 훈련하기에는 cost가 너무 높아지기 때문에 router만 float32로 훈련하는 것을 제안하고 있다.
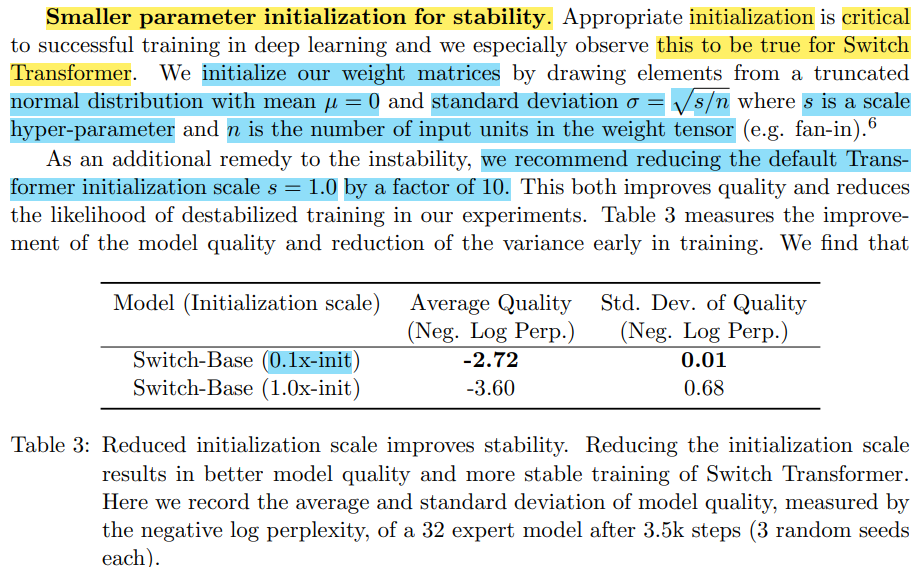
두번째로는 intialization의 규모를 작게하는 것이다.
딥러닝 학습에 있어서, 초깃값 설정은 중요힌 부분인데, 특히 Switch Transformer에서는 이러한 점이 강조된다고 한다.
논문의 저자들은 normal distribution에서 언급한 평균과/표준편차의 값을 활용하여 초기 weight의 규모를 낮추는 것이 효과적이라고 말한다.
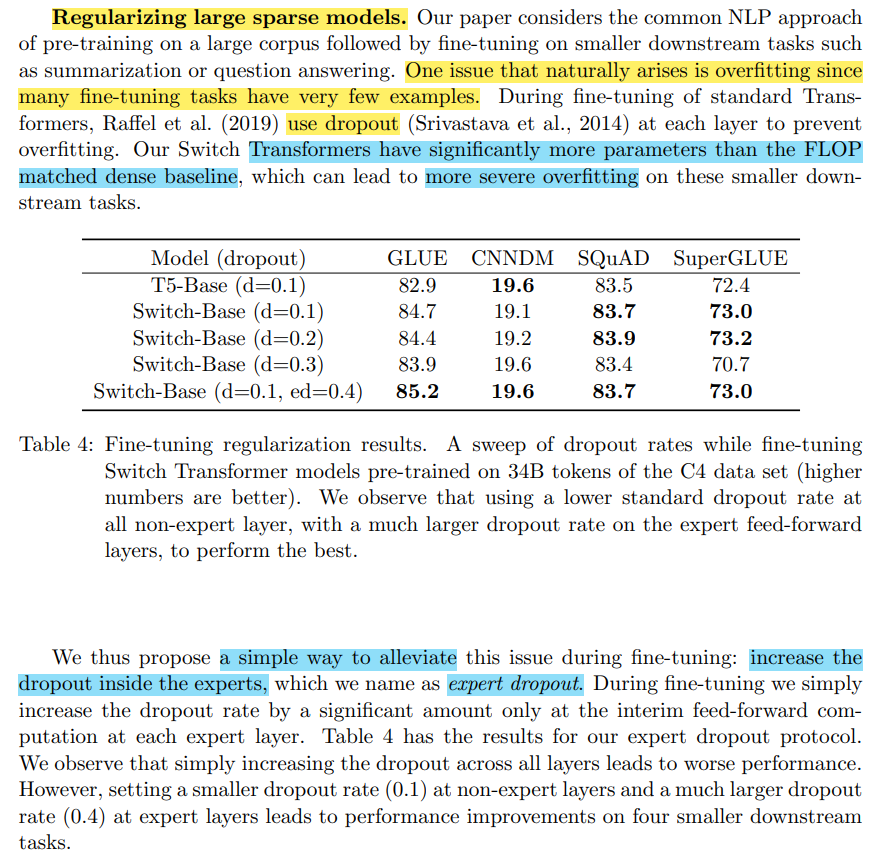
세번째는 expert dropout이다.
이는 overfitting 문제와도 연관이 있다.
Switch transformer는 기존 dense transformer보다 파라미터 수가 많기 때문에, fine-tuning와 같이 down-stream task에 대해서 훈련할 때 overfitting될 가능성이 커진다는 것이다.
따라서, expert를 학습하는 sparse layer에 dropout을 더 많이 줘서 이와 같은 문제점을 해결하였다.

네번째는 auxiliary loss를 추가했다.
이는 각 experts에 대해서, 균형있는 token이 학습되지 못하는 것을 방지하기 위해서 추가한 손실함수이다.
해당 논문의 저자들은, 위의 loss function을 통해 각 experts에 최대한 균일한 token이 학습되는 것을 보장했다고 한다.

마지막은 capacity factor를 증가하는 것이다.
이는 dropped token을 방지하기 위한 기술이다.
각 experts에는 정해진 capacity가 있다.
이는 (tokens_per_batch)/(num_experts) * capacity_factor 로 계산되는 batch size를 각각의 experts에 할당된다.
이때, 만약 capacity_factor가 작다면, 왼쪽의 그림의 빨간색 dotted line처럼, 각 expert에 균일하게 token이 나눠지지 못하고 overflow되는 현상이 일어날 수도 있다.
이러한 overflow 현상을 방지하기 위해, capacity_factor를 증가하여서 droped token이 최대한 생기지 않도록 하는 것이다.
이는 overflow 방지에 효과적이지만, computational cost가 증가한다는 단점도 당연히 따라온다.
위의 방법론들은 sprase한 MoE 활성화 방법으로 높은 확장성을 보여주었지만,
expert를 학습시키기 위한 routing 전략이 좋지 않으면 experts가 과적합되거나 제대로 훈련되지 않는다는 문제점이 있다.
이러한 문제점을 해결한 것이 바로 Expert Choice라는 새로운 방법이다.
Expert Choice Routing: https://arxiv.org/abs/2202.09368
Mixture-of-Experts with Expert Choice Routing
Sparsely-activated Mixture-of-experts (MoE) models allow the number of parameters to greatly increase while keeping the amount of computation for a given token or a given sample unchanged. However, a poor expert routing strategy (e.g. one resulting in load
arxiv.org
*한번 시간이 된다면 읽어보는 것을 추천한다!
- 2024.02.12 Kyujinpy 작성.
(밀린 논문리뷰를 차근차근..)



