*Tune-A-Video를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
Tune-A-Video paper: [2212.11565] Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (arxiv.org)
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
To replicate the success of text-to-image (T2I) generation, recent works employ large-scale video datasets to train a text-to-video (T2V) generator. Despite their promising results, such paradigm is computationally expensive. In this work, we propose a new
arxiv.org
Tune-A-Video github: showlab/Tune-A-Video: [ICCV 2023] Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (github.com)
GitHub - showlab/Tune-A-Video: [ICCV 2023] Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
[ICCV 2023] Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation - GitHub - showlab/Tune-A-Video: [ICCV 2023] Tune-A-Video: One-Shot Tuning of Image Diffusion Models...
github.com
Contents
Simple Introduction

간단한 One-shot만으로, 기존의 video를 원하는 text대로 변환할 수 있는 Tune-A-Video 모델이다!
기존의 text-to-image 기반의 diffusion model을 활용하여서 모델을 fine-tuning시킨다.
마치 DreamBooth와 같은 개념이라고 생각하면 편한데, 모델에서는 어떻게 one-shot tuning을 하는지 같이 살펴보자!
Background Knowledge: DDIM
DDIM 논문 리뷰: https://kyujinpy.tistory.com/97
[DDIM 논문 리뷰] - DENOISING DIFFUSION IMPLICIT MODELS
*DDIM를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! DDIM paper: [2010.02502] Denoising Diffusion Implicit Models (arxiv.org) Denoising Diffusion Implicit Models Denoising diffusion probabilistic models (DDPMs) have ac
kyujinpy.tistory.com
*해당 논문은 DDIM을 활용합니다! DDIM을 안다면 더욱 깊은 이해가 가능할 것 같습니다!
Method

Tune-A-Video의 간략한 Overview이다.
1. Video와 그에 대응하는 caption을 같이 넣어서 fine-tuning을 한다.
2. 새로운 text를 넣어서 새로운 video를 generation한다.
3. Generation할 때 DDIM 방법을 활용한다.
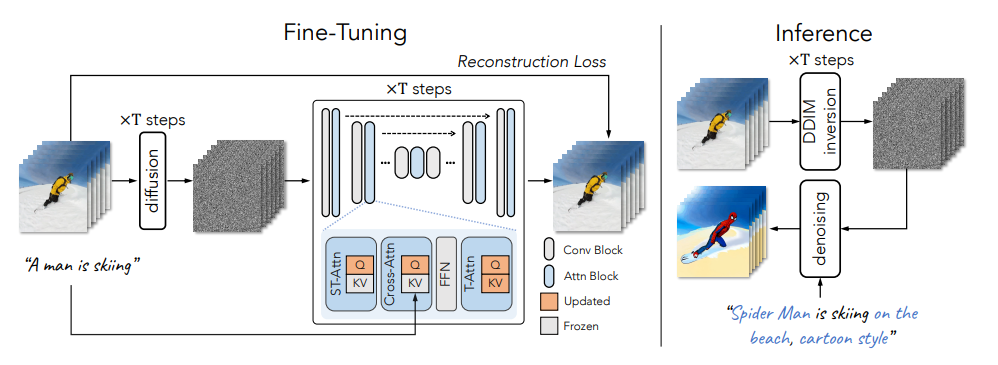
Model pipeline을 보면 다음과 같다.
1. 기존의 video를 frame단위로 쪼갠 후, T steps 만큼의 forward process를 걸친다.
2. LDM 구조를 활용해서 각 layer마다 skip-connection과 convolution, attention block활용한다.
3. 여기서 중간중간 attention을 layer를 fine-tuning한다.
- 여기서 LDM을 활용했기 때문에 당연히 UNet 구조이다.
- 추가적으로 spatio-temporal attention(ST-Attn)과 cross attention(Cross-Attn)에서는 query만 학습하고, temporal self attention (T-Attn)의 경우에는 전부 학습을 한다.
3. 위의 과정을 DDPM을 방법을 이용하여 reverse process를 진행한다.
4. Inference 과정에서 DDIM을 활용하여 결과를 generation한다.
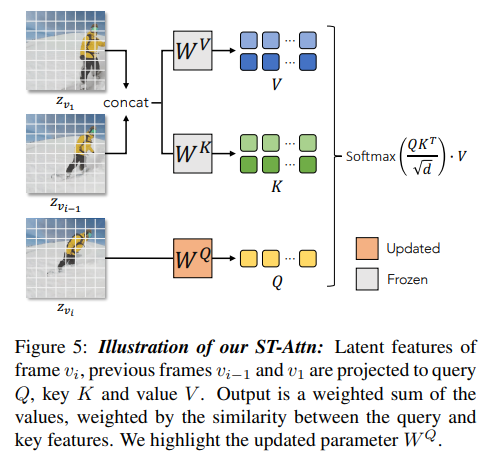
+) Spatio-temporal attention가 어떻게 작동되는지에 대한 설명이 있다.
Result

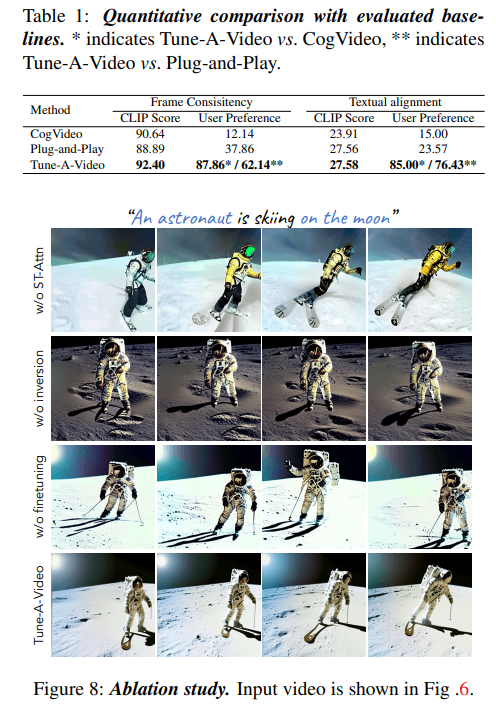
- Ablation study을 진행했을 때, 논문에서 제시했던 구조가 가장 적합하다고 생각이 든다.
- 2023.08.15 Kyujinpy 작성.



