*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다!
*총 3편으로 구성되었고, 2편은 DiT를 이해하기 위하여 LDM를 논문리뷰를 진행합니다!
*궁금하신 점은 댓글로 남겨주세요!
DiT paper: https://arxiv.org/abs/2212.09748
Scalable Diffusion Models with Transformers
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our D
arxiv.org
DiT github: https://www.wpeebles.com/DiT
*ooo를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
Contents
2. Background Knowledge: DiT Preview, VAE
- Latent Diffusion Model (LDM)
Simple Introduction

LDM은 stable-diffusion의 시작과 같은 모델이다(?)
LDM은 기존의 diffusion과 다르게 VAE의 모습을 어느정도 담아낸 diffusion model이다.
VAE처럼 encoder-decoder를 diffusion과 혼합함으로써, 더 다양하고 general한 이미지 생성을 가능하도록 했다.
또한 UNet구조를 활용하는 것도 인상적이고, 안에 attention 연산을 기반으로 conditional diffusion model도 훈련 가능하도록 모델을 디자인하였다.
한번 같이 살펴보자!
Background Knowledge: DiT Preview
DiT Preview: https://kyujinpy.tistory.com/131
[Diffusion Transformer 논문 리뷰1] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 2편으로 구성되었고, 1편은 DiT를 이해하기 위한 지식들을 Preview하는 시간입니다! *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://arxiv.or
kyujinpy.tistory.com
VAE 논문리뷰: https://kyujinpy.tistory.com/88
[VAE 논문 리뷰] - Auto-Encoding Variational Bayes
*VAE 수학적 지식을 리뷰하기 글입니다! 궁금하신 점은 댓글로 남겨주세요! *(통계학, 확률론 지식이 있다고 가정합니다.) VAE paper: https://arxiv.org/pdf/1312.6114.pdf Contents 1. Simple Introduction 2. Mathematical M
kyujinpy.tistory.com
*DDPM, CG, CFG, VAE에 관한 개념을 다루고 있습니다! 해당 개념들을 숙지하시면 이해하시는데 더 좋을 것 같습니다!
Method
Vector Quantization

개인적으로는 위의 이미지가 가장 VQ를 잘 설명하고 있는 것 같다. (직관적이다!)
디테일한 부분은 Taming Transformers for High-Resolution Image Synthesis 논문을 읽어보시는 것을 추천드립니다!
VQ는 vector quantization의 약자로 VQ-VAE 또는 VQ-GAN 이런식으로 활용되었다.
간단히 설명하면,
1. 기존 VAE의 경우 encoder로 부터 나온 latent space에서 임의의 Z의 sampling하여 decoder를 학습시켰다.
2. 그러나 VQ를 활용하여 latent space Z를 codebook를 활용하여 mapping 시키는 것이다.
3. 따라서, 개수가 제한된 codebook을 활용하여 discrete sampling을 하게 된다.

Encoder에서 나온 spatial code Z와 codebook에 있는 entry들간의 벡터간의 거리를 계산한다.
Argmin 연산을 통해서 가장 작은 값에 해당하는 codevector의 순서(number)를 각 (행,열)에 mapping시켜 이산적인 값을 가지는 Zq를 생성한다.

여기서 의문점이 드는 분도 있을수도 있다!
Codebook에서 나온 값이면 encoder까지 한번에 backpropgation이 안될 것 같은데 어떻게 gradient를 계산하나요!?
이건 VAE에서 제안된 re-parameterization 방법과 유사하다.
VQ에서는 stop-gradient operation을 이용한다.
쉽게 얘기하면, decoder에 있는 gradient를 encoder에 복사해서 적용한다.
(왜냐하면, VAE자체가 encoder와 decoder의 분포를 유사하게 하는 것이기 때문이다.)

+) Stop-gradient에 대해서 위의 블로그가 설명이 좋은 것 같다!

-> 더 직관적인 이미지를 찾았다! VQ-VAE 완벽이해 완료!
Latent Diffusion Model (LDM)
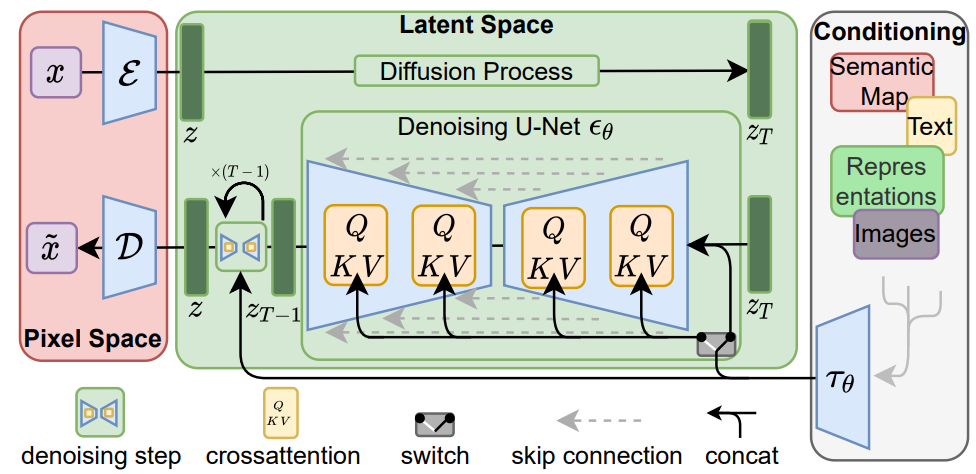
LDM에서는 VAE 처럼 encoder, decoder를 활용한다.
Encoder는 당연히 down-sampling의 역할을 하고, Decoder는 up-sampling을 역할을 한다.
여기서 더 중요한 사실을 짚고 넘어가보자.

논문에서는 high-variacen latent spaces을 피하기 위해서, 2가지 종류의 regularization을 적용했다고 한다.
첫번째는 KL-reg이다. VAE처럼 KL-divergence를 loss term으로 활용하였다.
두번째는 VQ-reg이다. 해당 개념은 vector quantization으로, VQ-GAN과 VQ-VAE 등등에 많이 활용되는 개념이다.
VQ 개념은 decoder에 넣어서 layer를 구성했다고 언급하고 있다.

LDM의 경우, Xt라는 표현보다, Zt라는 표현을 사용한다.
물론, 표기상의 차이이긴 하지만 아래와 같이 의미를 이해하면 좋겠다!
- 기존의 Diffusion 모델은 image X로 부터 얻은 noise Xt를 가지고 학습했다면, LDM은 image X를 encoder를 통해서 Z라는 latent space를 얻고, Z에 noise를 더한 Zt로 부터 학습을 진행한다!
Conditioning Training

LDM의 경우 위의 논문 구조에서 맨 오른쪽에서 보이는 것처럼, domain specific encoder T를 통해서 얻은 embedding을 cross-attention 연산을 통해서 UNet에 정보를 전달한다.

논문을 보면 각각의 project matrix W에 대한 shape이 나와있고, conditional training에 대한 loss 수식도 나와있다.
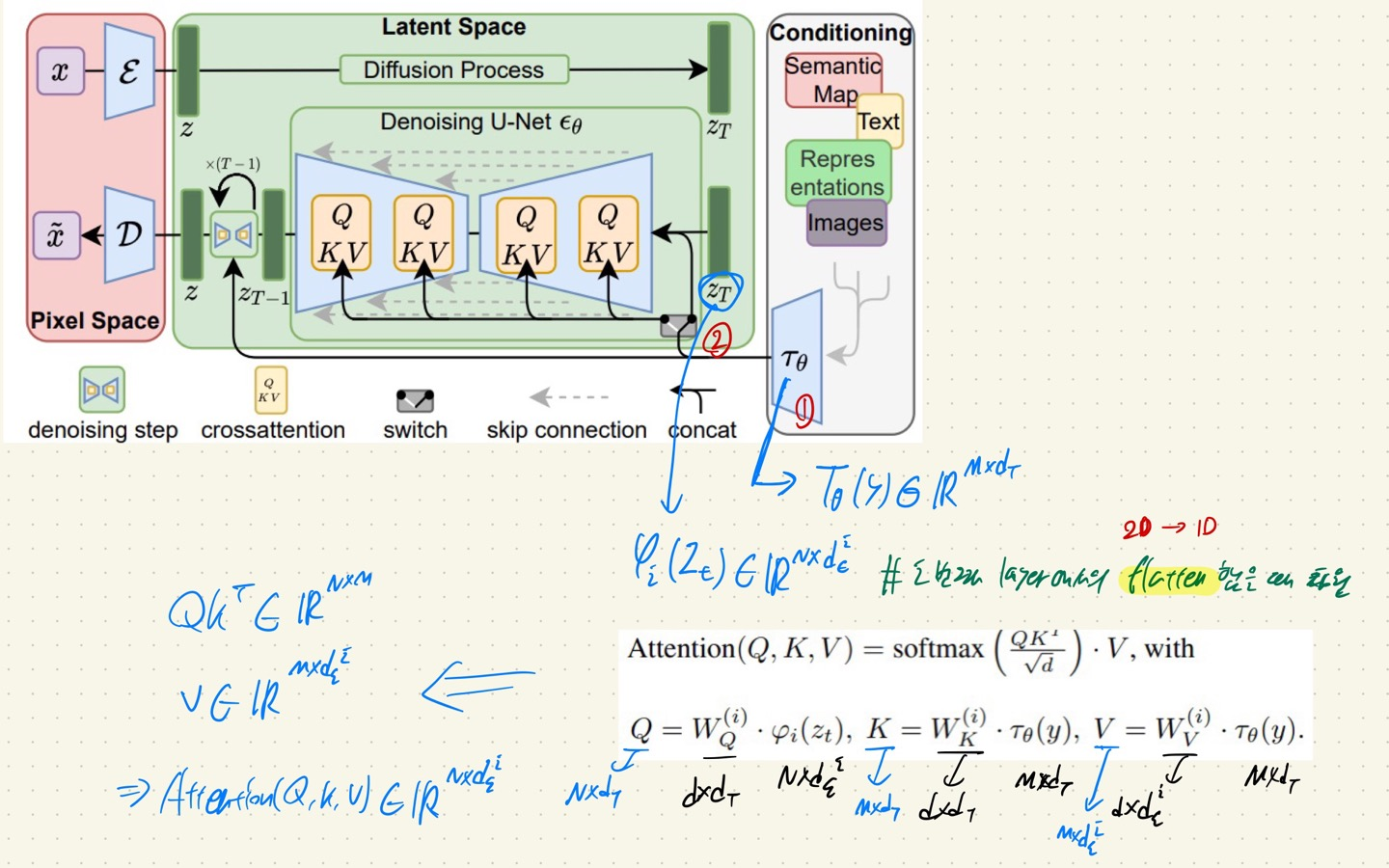
+) 근데 논문에 나와있는 shape대로 맞출려고 하니 뭔가 이상하다. (오류인듯..) 일단 몇가지 알게된 사실을 아래 적어보겠다.
1. d의 shape은 project matrix에 곱해지는 값 (UNet의 중간 layer 또는 T로 부터 나온 embedding 값)의 차원과 같은 값인 것 같다.
2. N은 batch size를 의미하는 것 같다.
3. Q, K, V를 계산할 때, project matrix가 뒤로 가도록 연산되어야 맞는 것 같다. (A * W 이런식으로 해야 dot-product 연산이 가능하다.)
-> 위의 사실과 관련하여서 정확하게 아시는 분은 댓글로..남겨주세요 ㅎㅎ..
DiT 논문리뷰
DiT 논문 리뷰: https://kyujinpy.tistory.com/132
[Diffusion Transformer 논문 리뷰3] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 3편은 DiT를 논문리뷰 입니다! *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://arxiv.org/abs/2212.09748 Scalable Diffusion Mode
kyujinpy.tistory.com
최근에 OpenAI에서 발표한 가장 핫한 SORA 모델!
SORA 모델의 기반이 DiT라는데..빨리 공부해야하지 않겠나요!?
- 2024.02.27 Kyujinpy 작성.



