*Skip-DiT를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
Skip-DiT paper: https://arxiv.org/abs/2411.17616
Accelerating Vision Diffusion Transformers with Skip Branches
Diffusion Transformers (DiT), an emerging image and video generation model architecture, has demonstrated great potential because of its high generation quality and scalability properties. Despite the impressive performance, its practical deployment is con
arxiv.org
Skip-DiT github: https://github.com/opensparsellms/skip-dit
GitHub - OpenSparseLLMs/Skip-DiT: Accelerating Vision Diffusion Transformers with Skip Branches. arxiv: https://arxiv.org/abs/2
Accelerating Vision Diffusion Transformers with Skip Branches. arxiv: https://arxiv.org/abs/2411.17616 - OpenSparseLLMs/Skip-DiT
github.com
Contents
Simple Introduction

오늘날 Generative AI의 발전속도와 성능은 기하급수적으로 늘어나고 있는 것 같습니다!
이제는 이미지를 넘어서, stable한 video나 3D 생성 분야에 대한 논문들과 open-source가 많이 나오고 있는데요..!
생성 분야에서 성능은 매우 중요한 요소이지만, '효율성'도 매우 중요한 문제입니다.
보통 성능은 모델의 파라미터 개수와 비례한다고 생각할 수 있는데, '효율성'은 파라미터와 반비례하는 특성이 있습니다.
제한된 GPU 자원안에서 효율성(inference time, GPU memory 등등)과 모델의 성능에 대한 중심점을 잘 찾는게 중요합니다.
Skip-DiT는 기존 DiT 모델의 block 사이에 Skip Branch를 추가하고, 이를 inference할 때 활용하여 기존 DiT 구조보다 더 빠르게 생성하는 방법을 소개합니다!
최근에 이러한 layer간의 병합이나 skip-branch를 통해서 모델을 develop하는 연구들이 많은데, 한번 같이 살펴보시죠!
Background Knowledge: DiT
Diffusion Transformer: https://kyujinpy.tistory.com/132
[Diffusion Transformer 논문 리뷰3] - Scalable Diffusion Models with Transformers
*DiT를 한번에 이해할 수 있는(?) A~Z 논문리뷰입니다! *총 3편으로 구성되었고, 마지막 3편은 제 온 힘을 다하여서.. 논문리뷰를 했습니다..ㅎㅎ *궁금하신 점은 댓글로 남겨주세요! DiT paper: https://ar
kyujinpy.tistory.com
*DiT 지식이 필수는 아닙니다! Block간의 연결을 어떻게 하였는지 집중하시는 걸 더 추천드립니다!
(*기본적인 DDPM 정도는 이해하시면 좋습니다)
Method
Methodology Insights
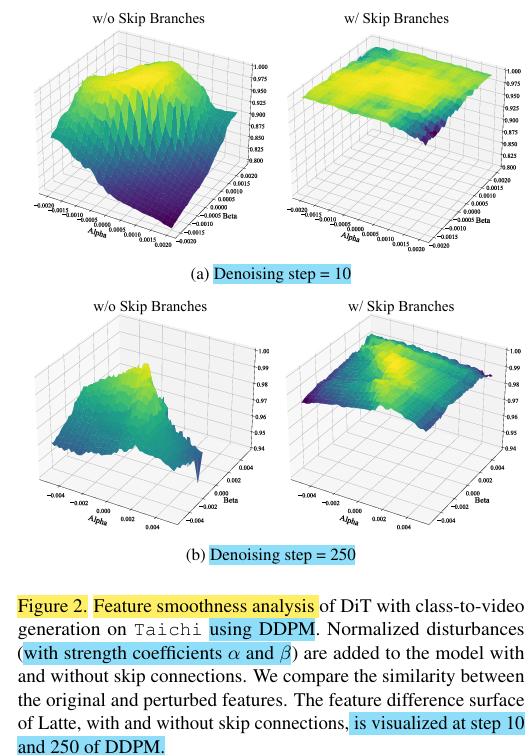
논문의 저자들이 base DiT 모델에서 denoising step=10, 250에서 transformer feature를 시각화를 한 결과, 차이가 꽤 심한 것을 알 수 있습니다.
그리고, stregth coefficients에 따라서도 꽤나 요동치는 모습을 보여주고 있습니다.
(해당 coefficients가 DDPM에 쓰이는 것인지; 정확하게는 모르겠음)
Skip-DiT는 이러한 visualization을 'feature smoothness'라고 명명하였으며, 만약 timesteps간의 feature smoothness의 모양이 비슷하다면 더 빠르게 inference caching을 할 수 있지 않을까 생각하게 됩니다..!

논문의 저자들은, 이러한 DiT의 feautre smoothness으로부터 effective한 inference mechanisms을 만들 수 있는지 고민했고,
실험을 통해 skip-branches가 최소한의 continous pre-training으로 feature smoothness를 향상시킬 수 있다는 것을 보였습니다!
Skip-DiT & Skip-Cache
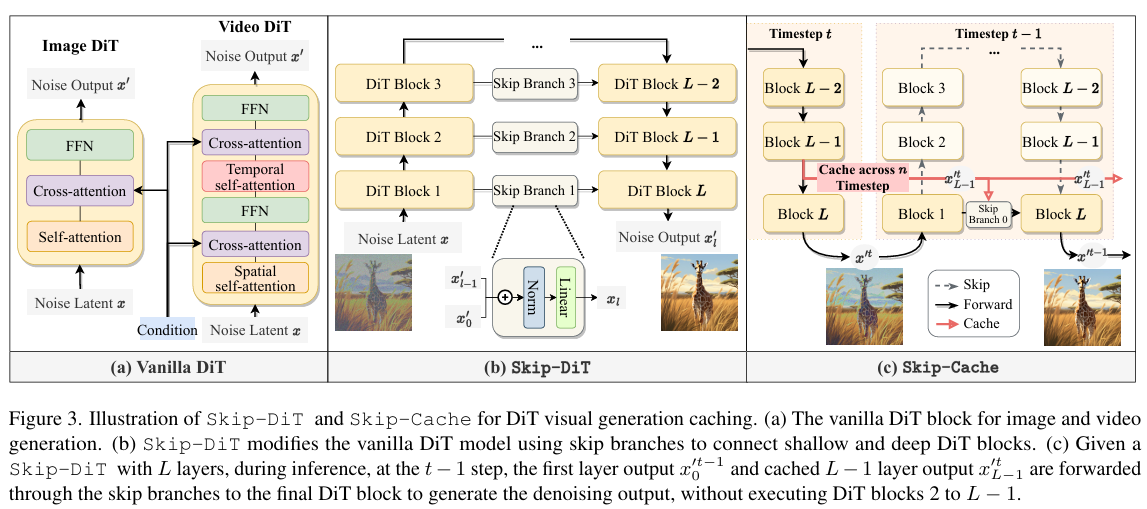
훈련 과정은 매우 간단합니다! (b번 이미지)
기존 DiT의 구조에서, block을 대칭하게 skip branch로 연결시켜주면 됩니다!
여기서 skip branch는 Norm + Linear의 형태를 가지게 됩니다

여기까지만 보면, 기존 DiT에 skip-branch를 더했으니 더 파라미터가 많아진 것이 아닌지 생각이 들텐데요..!
핵심 아이디어는 바로 Skip-cache 입니다!
Skip-cache의 작동 순서는 아래와 같습니다.
1. Timestep t번째에서 1~L block을 모두 걸쳐서 생성된 x`t. (equation 7)
2. T번째에서, L-1 block에서 나온 feature인 x`t_(L-1)를 caching함. (equation 8)
3. T-1 timesteps에서, block 1에서 나온 feature와 caching한 feature를 동시에 활용해서 block L번째로 바로 전달. (위의 skip-cache 이미지 체크)
위와 같은 skip-branches와 caching된 features를 활용해서, 기존에 있는 모든 block을 통과하지 않고 inference를 빠르게 하는 방법을 제안하고 있습니다!
더불어서 skip-branches를 동일한 time-step 안에서 feature를 공유하는데 사용하는 것이 아니라, 이전 time-steps의 feature를 넣어주는 아이디어도 되게 신기한 것 같습니다. (-> 이를 통해, feature smoothness를 해결)
Result

- Class-2-Video 성능 (single A 100 GPU)
- n=i는 caching을 적용하는 layer 개수 (table 설명 참고)

- Training efficieny 방면에서도, 기존 DiT-XL 보다 뛰어남.

- 약 1.5배 빠른 속도로, text-to-image도 가능.
- 2024.12.01 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!
(*가독성을 위해서, 광고를 상-하단에만 설정했는데 광고가 많이 노출되면 알려주세요!!)
'AI > Paper - Theory' 카테고리의 다른 글
| [TransPixar 논문 리뷰] - Advancing Text-to-Video Generation with Transparency (0) | 2025.01.16 |
|---|---|
| [SigLip 논문 리뷰] - Sigmoid Loss for Language Image Pre-Training (4) | 2024.12.08 |
| [MoH 논문 리뷰] - MULTI-HEAD ATTENTION AS MIXTURE-OF-HEAD ATTENTION (1) | 2024.10.18 |
| [Dense Connector 논문 리뷰] - Dense Connector for MLLMs (2) | 2024.10.18 |
| [LLaVA-Video 논문 리뷰] - VIDEO INSTRUCTION TUNING WITH SYNTHETIC DATA (5) | 2024.10.12 |



