*MoH를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
MoH paper: [2410.11842] MoH: Multi-Head Attention as Mixture-of-Head Attention (arxiv.org)
MoH: Multi-Head Attention as Mixture-of-Head Attention
In this work, we upgrade the multi-head attention mechanism, the core of the Transformer model, to improve efficiency while maintaining or surpassing the previous accuracy level. We show that multi-head attention can be expressed in the summation form. Dra
arxiv.org
MoH github: GitHub - SkyworkAI/MoH: MoH: Multi-Head Attention as Mixture-of-Head Attention
GitHub - SkyworkAI/MoH: MoH: Multi-Head Attention as Mixture-of-Head Attention
MoH: Multi-Head Attention as Mixture-of-Head Attention - SkyworkAI/MoH
github.com
Contents
Simple Introduction

최근 LLM하면, MoE (Mixture-of-Experts)구조는 거의 필수처럼 따라오고 있습니다!
실제로 MoE 구조를 통해서 성능이 향상된다는 연구가 많이 있고, 최근에는 MoE 구조보다 더 효율적인 mixture 방법을 제안하고 있습니다
Mixutre-of-Head Attention (MoH)는 이러한 MoE 구조를 기반으로, multi-head attention 메커니즘으로 구성된 MoE 방식을 제안합니다
기존 MoE는 attention layer을 통과하고 나서 MoE Layer를 통해 experts를 결정했는데, MoH는 attention 메커지즘 안에서 어떻게 MoE 방법을 구현했는지 살펴봅시다!
Background Knowledge: MoE
MoE 논문 리뷰: https://kyujinpy.tistory.com/127
[MoE 논문 리뷰] - Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
*MoE를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! MoE paper: https://arxiv.org/abs/2101.03961 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity In deep learning, models typi
kyujinpy.tistory.com
*MoE의 기본 개념을 알고 있다고 생각하고, 논문 리뷰를 진행합니다! (+Transformer는 기본(?))
Method
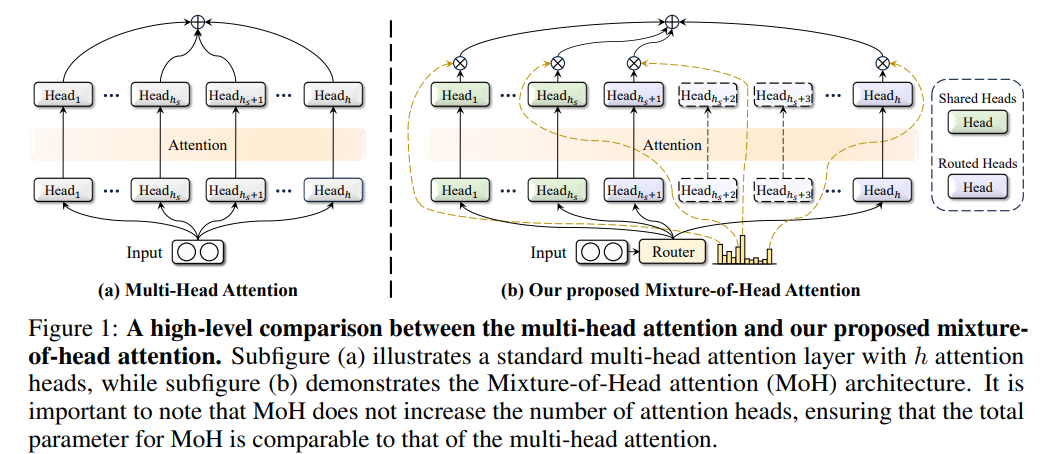
Heads as Experts

MoH의 overview를 먼저 살펴보겠습니다
- g는 router로 얻은 각 score가 됩니다! (밑에 two-stage routing에서 정의)
- H는 주어진 heads를 의미합니다
- Wo는 weighted sum을 위한 가중치 입니다
즉, 기존처럼 multi-head attention을 수행하는 건 동일하지만 router를 통해서 얻은 score를 곱해주는 것이 MoH 입니다!
Shared Heads

Shared Heads는 항상 통과되는 attention layer를 의미합니다!
이와 같은 이유는, 데이터가 가지고 있는 common knowledge를 고려하기 위함입니다!
(예를 들면, 이미지의 구성, 생성 패턴, text의 문법 등등)
다음은 Shared Heads와 더불어서 Routed Heads를 어떻게 고려하는지 살펴봅시다
Two-Stage Routing

Two-Stage Routing 부분에서는, router score를 결정하는 부분입니다!
1. hs개의 heads는 shared router
2. 나머지는 모두 routed heads로 구분
Routed heads에서는 기존 MoE 처럼 Top-K개를 골라서 점수를 매기고, 나머지는 0점으로 처리합니다
(*T개의 tokens 중 각각 t번째 input token에 대해서 각각 계산하게 됩니다)
여기서 한가지 특이한점은, shared router와 routed heads를 어느정도 contribution으로 지정할지 생각해야합니다
이를 위해서, equation (6)을 통해서 learnable parameters alpha_1,2를 학습합니다

MoH 학습은 기존 모델 task 별 loss functions에 MoE loss function을 더해주는 형태입니다!
(*각 heads(h)마다 input token의 개수(T)를 토대로, router score의 평균을 기반으로 loss function을 구상합니다)
Result


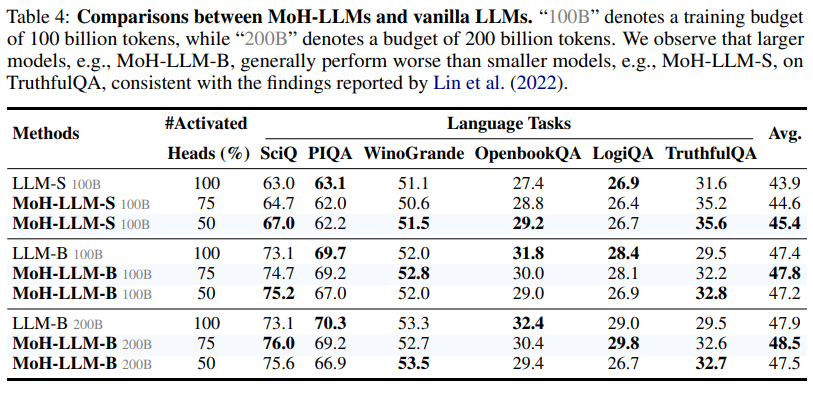
- ViT / DiT / LLM 구조에 모두 적용했더니, 성능이 향상됨 (SOTA 달성함)
- 2024.10.18 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!
(*가독성을 위해서, 광고를 상-하단에만 설정했는데 광고가 많이 노출되면 알려주세요!!)



