*SigLip를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
SigLip paper: https://arxiv.org/abs/2303.15343
Sigmoid Loss for Language Image Pre-Training
We propose a simple pairwise Sigmoid loss for Language-Image Pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise sim
arxiv.org
SigLip github: https://github.com/huggingface/transformers/blob/main/src/transformers/models/siglip/modeling_siglip.py
transformers/src/transformers/models/siglip/modeling_siglip.py at main · huggingface/transformers
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
github.com
Contents
Simple Introduction

Multi-modal에서 text와 다양한 데이터셋(vision, audio 등등)을 alignment을 시키는 방법은 무엇일까?
이전까지 가장 많이 이용되는 모델이 바로 CLIP 입니다!
CLIP는 text와 image 간의 유사도를 바탕으로 embedding 정보를 학습하는 모델입니다!
오늘날 GPT-4o나 StableDiffusion과 같이 text-image를 동시에 이해하는 모델들은, CLIP에서 활용한 방법론을 기반으로 text와 image 간의 embedding을 LLM(or LMM) backbone에 넣어서 학습시킵니다!
최근에는 CLIP보다 좋은 성능을 가지는 SigLip 모델을 기반으로 image, video-embedding을 활용하는 LMMs이 많이 등장하고 있습니다!
SigLip은 CLIP와는 어떻게 다른지, 어떤 구조를 가지고 있는지 한번 살펴보시죠!
Background Knowledge: CLIP
CLIP 논문 리뷰: https://kyujinpy.tistory.com/47
[CLIP 논문 리뷰] - Learning Transferable Visual Models From Natural Language Supervision
*CLIP 논문 리뷰를 위한 글입니다. 질문이 있다면 댓글로 남겨주시길 바랍니다! CLIP paper: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org) Learning Transferable Visual Models From Natu
kyujinpy.tistory.com
*SigLip과 양대산맥이라고 할 수 있는, CLIP을 이해하시는 걸 추천드립니다!
Method
먼저, mini-batch B가 있다고 가정합니다!
B에는 pair한 (image, text)으로 구성되어 있습니다. (강아지 이미지, dog)
그리고, image model과 text model을 각각 f와 g라고 정의하도록 하겠습니다.
Sigmoid loss for language image pre-training
우선 sigmoid 기반 loss function을 살펴보기 전에, softmax 기반으로 구성된 loss function을 살펴보도록 하겠습니다!
x와 y는 각각 normalized된 image와 text embedding을 의미합니다.
해당 loss functions은 2가지 terms으로 구성되어 있습니다!
1. Image에 대해서 text embedding에 대한 softmax
2. Text에 대해서 image embedding에 대한 softmax
여기서 softmax의 asymmetry한 성질로 인해서, image와 text에 대해 독립적인 normalization (softmax)이 이루어져야 한다.
(하나의 positive pair에 대한 유사도를, 모든 pair에 대한 유사도로 나누어서 normalization == 연산량이 많아짐.)

SigLip의 저자들은, softmax기반 loss function은 독립적인 normalization을 2번 수행하게 되니,
sigmoid 기반 함수를 활용해서 binary-classification 문제로 simple하게 나타낼 수 있다고 언급하고 있습니다!
수식을 살펴보면
1-1. 만약 positive pair라면, z의 값을 1로 설정하고
1-2. 만약 negative pair라면, z의 값을 -1로 설정
2-1. Learnable parameters t`는 유지. (위에 softmax 기반 함수 참고)
2-2. Learnable parameters b를 새롭게 추가.
-> Negative pair가 많아지면 초기 optimization step에서 bias가 생기는 문제점이 있어서, 이로 생기는 bias를 해결하기 위함.

Z 값이 1 또는 -1로 설정된 이유를 좀 더 찾아봅시다.
0. 해당 수식은 x와 y의 유사도 계산에 sigmoid + negative log function을 적용한 형태입니다. (sigmoid는 0과 1사이의 값)
0-1. t는 대충 10, b는 -10라고 가정합시다.
1. Z = 1일 때, positive pair이므로 유사도가 높다고 가정하자. (1에 가까움)
- 지수함수의 성질로 인해 분모가 작음.
- Log 안에 있는 term이 1에 가까워지므로, log 함수는 0에 가까워짐.
- 즉, loss function 감소
2. Z = -1일 때, negative pair이므로 유사도가 낮다고 가정하자. (0에 가까움)
- 유사도가 0이라고 생각하면 e^(-b) 형태가 됨. (z를 곱한 형태)
- 지수함수가 커지므로, log 함수가 0에서 멀어짐.
- 즉, loss function 증가.
3. Negative pair일 때, Z = 0이면??
- Z = 0이면 말이 안됨..
- e^(0)은 1이므로, 항상 log(0.5) 값이 나옴(?)
따라서 sigmoid 함수의 특징을 반영하기 위해서, z의 값을 1과 -1로 설정했다는 것을 알 수 있다!

- 매우 쉽게 pytorch code로 만들 수 있다!
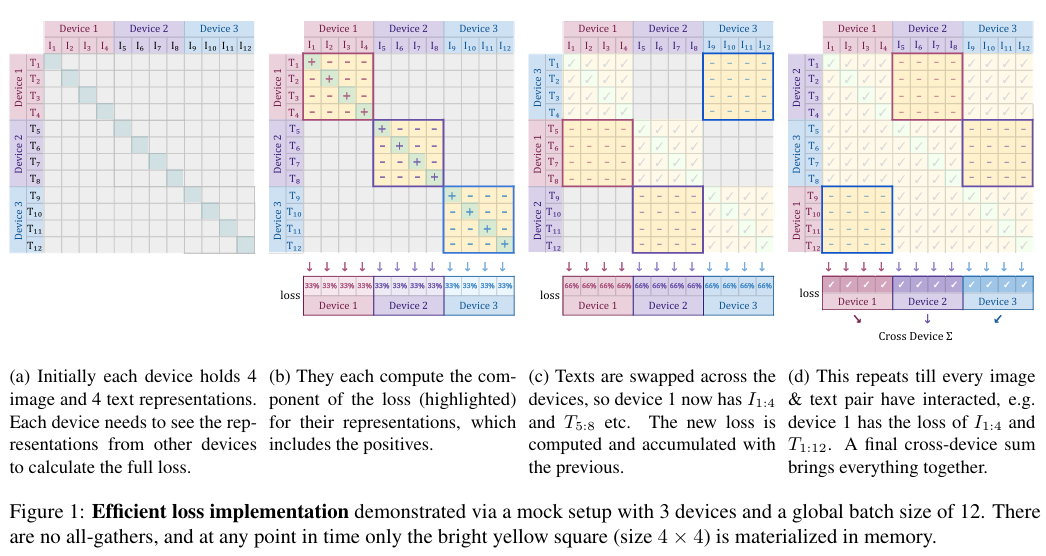
- N개의 GPU device를 통해서 SigLip을 효율적으로 훈련시킬 수 있는 방법을 논문에서 소개하고 있다. (블로그에서는 제외)
- 예시에서는 N=3 (병렬처리)
Result
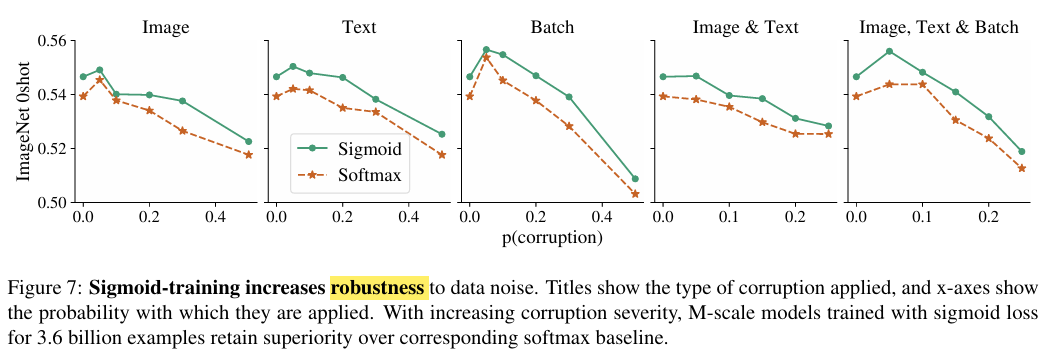
- Softmax보다 sigmoid가 좀 더 robustness하다는 것을 보여주는 graph
- 2024.12.08 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!
(*가독성을 위해서, 광고를 상-하단에만 설정했는데 광고가 많이 노출되면 알려주세요!!)



