*Dense Connector를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
Dense Connector paper: [2405.13800v1] Dense Connector for MLLMs (arxiv.org)
Dense Connector for MLLMs
Do we fully leverage the potential of visual encoder in Multimodal Large Language Models (MLLMs)? The recent outstanding performance of MLLMs in multimodal understanding has garnered broad attention from both academia and industry. In the current MLLM rat
arxiv.org
Dense Connector github: DenseConnector/README.md at main · HJYao00/DenseConnector · GitHub
DenseConnector/README.md at main · HJYao00/DenseConnector
【NeurIPS 2024】Dense Connector for MLLMs. Contribute to HJYao00/DenseConnector development by creating an account on GitHub.
github.com
Contents
Simple Introduction
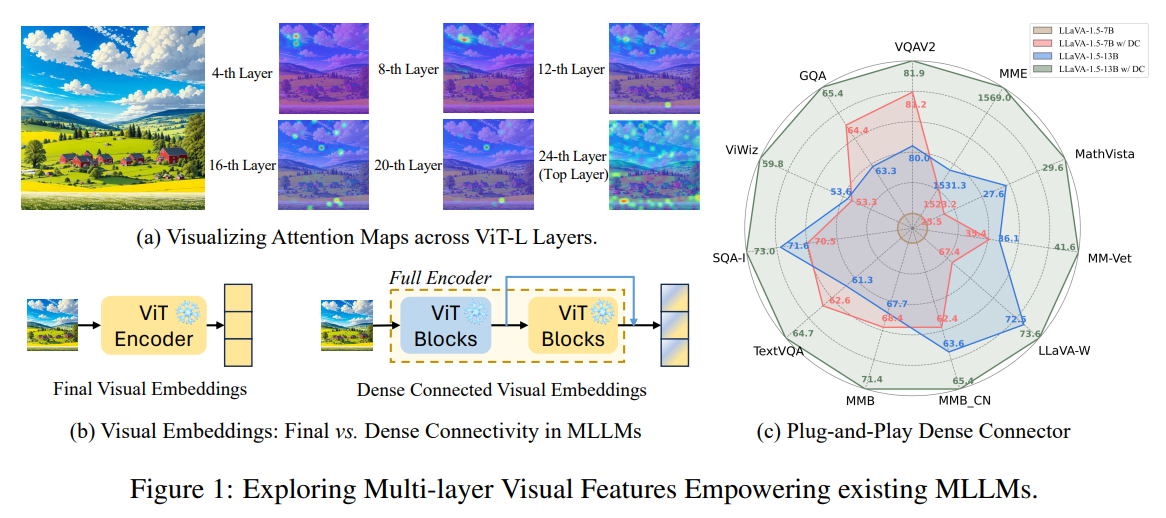
요즘 LMM을 본격적으로 파고들고 싶다는 마음이 생겨서 논문들을 되게 많이 읽고 있습니다!
그러던 와중, dense connector라는 구조를 통해서 기존 LLaVA 성능을 높인 논문을 보고 큰 흥미가 생겼습니다!
기존 LLaVA의 경우, visual embedding을 수행할 때 이미지를 CLIP 또는 SigLIP embedding을 통해서 LLM에 같이 학습하는 구조였는데
Dense Connector는 어떤 embedding 방법을 활용하고 있는지, 또 이 방법이 어떻게 성능기여를 하는 것인지 같이 알아보면 좋을 것 같습니다!
*이렇게 간단한 방법을 통해서, 기존 모델의 성능 향상에 기여하는 것은 너무 재밌고 흥미로운 것 같습니다.
Background Knowledge: ViT
ViT 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
* ViT 기반으로, visual embedding을 수정하기 때문에 ViT를 이해하시면 편합니다!
Method
Overview

기본적으로, visual encoding할 때 뼈대가 되는 base model은 CLIP (or SigLIP)입니다!
즉, CLIP을 구성하는 여러 ViT layers를 분할해서, 풍부한 visual information을 dense connector를 통해서 다시 한번 visual features를 학습하는 형태가 됩니다!
Sparse Token Integration (STI)
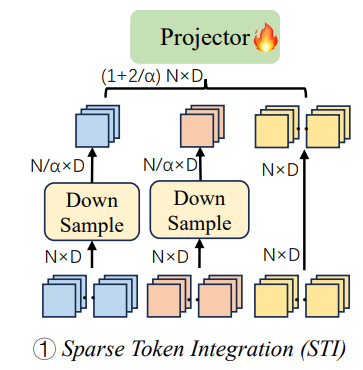
Sparse Token Integration은 각각의 ViT layers에 나온 features를 intergrating하는데 초점을 맞춘 구조입니다!
이는, multiple layers를 고려하기 때문에 보다 더 풍부한 visual informations을 LLM에 같이 반영해 줄 수 있습니다
물론, computational cost를 방지하기 위해서 앞의 Shallow and Middle layers는 down-sampling을 진행합니다!
(average pooling 적용)

STI의 마지막 projector는 MLP로, ViT layers가 24개로 구성되어 있다면
8th, 16th, 24th번째 featuer vectors를 concat하고 MLP에 넣는 방식이 됩니다!
즉, token의 방향대로 integration했기 때문에 Sparse Token Integration이 됩니다!
Sparse Channel Integration (SCI)
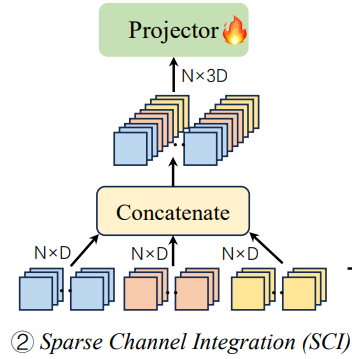
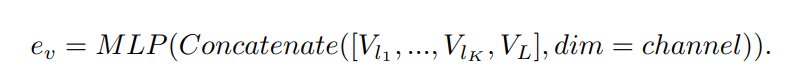
Sparse Channel Intergration은 STI와는 반대로, channel방향으로 integration을 수행합니다!
(간단하니 넘어가겠습니다!)
Dense Channel Integration (DCI)
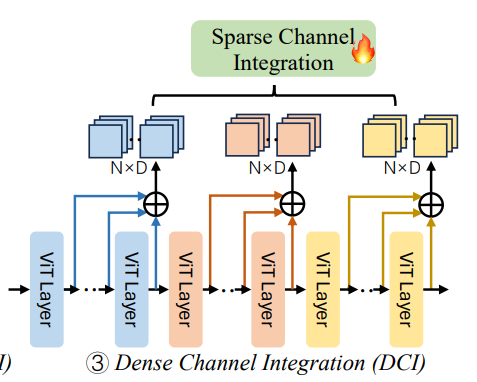
Dense Channel Integration은 앞의 SCI, STI와는 약간 다릅니다!
SCI와 STI의 경우 사실 중간 일부분의 feature vectors를 활용하는 것이기 때문에, 다른 layers들의 풍부한 infomration을 고려하지 못하게 됩니다. (모두 다 고려하면, computational cost가 어마어마 할 수도(?))
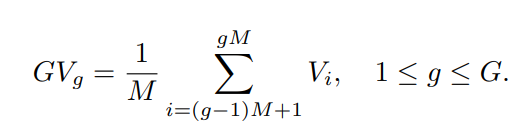
따라서, DCI는 ViT의 풍부한 visual information을 모두 활용하면서 cost문제를 해결하기 위해서 group을 지정해서 연산을 수행합니다!
간단히 말하면, Group이 3이라면, (1~8), (9~16), (17~24) layers로 분할하고 각 group마다 visual representation을 위의 수식을 통해서 생성하게 됩니다!!
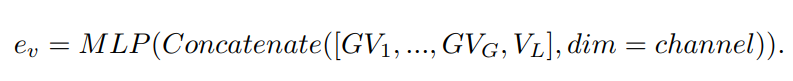
마지막으로, SCI 구조를 적용하게 됩니다!
(채널 방향으로 통합한 후, MLP 적용)

- LLM 종류와, CLIP 또는 SigLIP 모델을 어떻게 활용했는지 알려주고 있습니다
- (헷갈릴 수 있는 포인트는) ViT 구조에서 첫번째 한 개는 stem layer로 지정을 합니다.
--> 즉, CLIP이 25개의 ViT layers를 가지고 있다면 앞의 1개를 제외하고 나머지 24개로 STI, SCI, DCI를 생각하는 것입니다!
Result
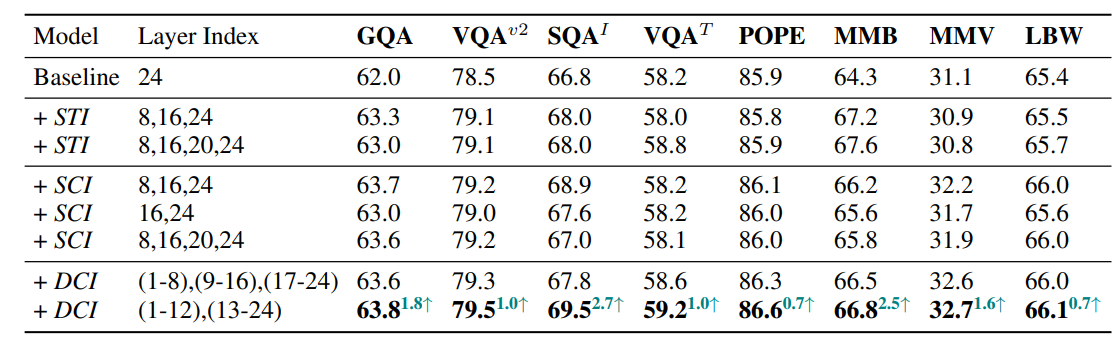
- 가장 좋은 구조는, DCI 기반의 2 group 형태가 가장 성능 향상에 좋다고 합니다!!

- 2024.10.18 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!
(*가독성을 위해서, 광고를 상-하단에만 설정했는데 광고가 많이 노출되면 알려주세요!!)



