*LLaVA-OneVision를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
LLaVA-OneVision paper: https://arxiv.org/abs/2408.03326
LLaVA-OneVision: Easy Visual Task Transfer
We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. Our experimental results demonstrate that LLaVA-OneVision is th
arxiv.org
LLaVA-OneVision github: https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
LLaVA-OneVision: Easy Visual Task Transfer
We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. Our experimental results demonstrate show that LLaVA-OneVision
llava-vl.github.io
Contents
2. Background Knowledge: LLaVA-NeXT
- Vision Encoder
- Higher AnyRes with Bilinear Interpolation
- Training Strategies
5. Furthermore
Simple Introduction

LLaVA-NeXT는 더 체계적인 데이터셋과 약간의 모델 변화로(?), vision-languauge models의 성능 향상을 효율적으로 이끌어냈습니다!
여기서 더 나아가서, multi-image or video를 동시에 이해할 수 있는 LLaVA-OneVision 모델을 소개합니다!
해당 모델은 어떤 변화가 이루어졌고, 데이터셋은 어떻게 구성했는지 살펴봅시다.
Background Knowledge: LLaVA-NeXT
LLaVA-NeXT 논문 리뷰: https://kyujinpy.tistory.com/157
[LLaVA-NeXT 논문 리뷰] Improved Baselines with Visual Instruction Tuning
*LLaVA-NeXT를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! LLaVA-Next Github: https://github.com/LLaVA-VL/LLaVA-NeXT GitHub - LLaVA-VL/LLaVA-NeXTContribute to LLaVA-VL/LLaVA-NeXT development by creating an account on
kyujinpy.tistory.com
*LLaVA-NeXT를 기반으로, 업그레이드(?)된 LLaVA-OneVision 모델입니다!
Method
Vision Encoder
첫번째로, vision encoder가 SigLIP 모델로 변화되었습니다!
(LLM도 Qwen-2로 바뀜)
기존 LLaVA, LLaVA-NeXT 모델들은 CLIP을 기반으로 vision encoder를 구성한 반면, LLaVA-OV(onevision)은 SigLIP을 활용합니다!
실제로, SigLIP이 LMM이 higher performance를 달성할 수 있도록 도움을 주었다고 합니다!
- SigLIP이 궁금하시다면, 검색해서 읽어보시는 걸 추천드립니다!
추천 references: https://taewan2002.medium.com/siglip-sigmoid-loss-for-language-image-pre-training-aa68fedaa080
SigLIP: Sigmoid Loss for Language Image Pre-Training
SigLIP는 비대칭적이지 않으며 전역 정규화 인자도 필요하지 않습니다. SigLIP는 시그모이드 연산을 사용하고 각 이미지-텍스트 쌍(양수 또는 음수)은 독립적으로 평가됩니다. 따라서 모든 GPU가 모
taewan2002.medium.com
Higher AnyRes with Bilinear Interpolation
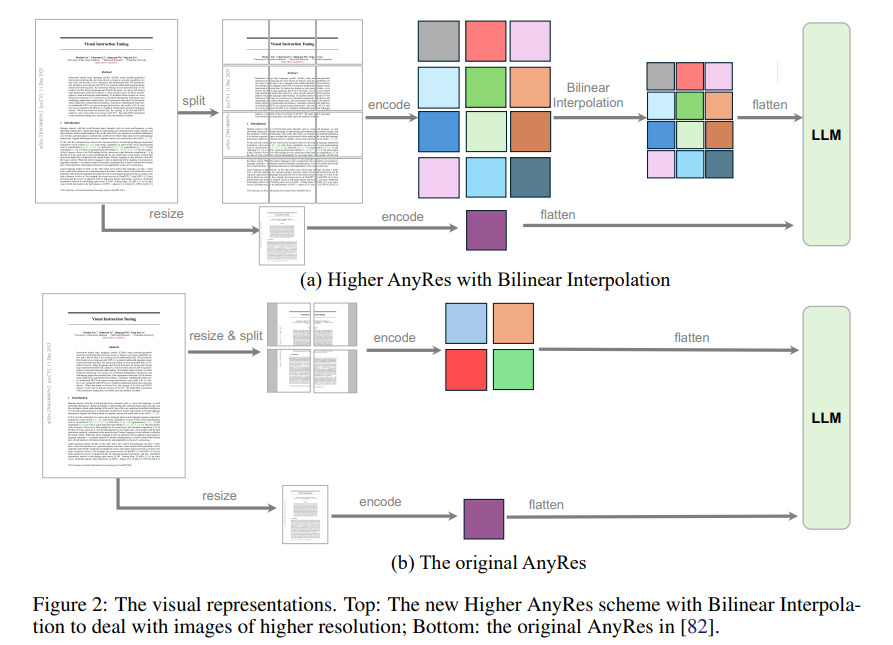
두번째로, AnyRes 방법론이 바뀌었습니다!
AnyRes 방법론은, LLaVA-1.5에서 제안된 방법입니다 (Figure b참고)

LLaVA-OV에서는 기존 AnyRes보다 발전된(?) AnyRes를 제안합니다
1. Original image를 그대로 split하고 encoding함.
2. 만약 visual token의 개수가 threshold보다 더 크다면, bilinear interpolation을 적용
3. 기존과 똑같이, 전체 이미지에 대한 feature를 생성하기 위해 resize하고 encoding하는 pipeline 유지
3. 모든 visual tokens을 flatten하고, concat해서 LLM에 넣기
Training Strategies
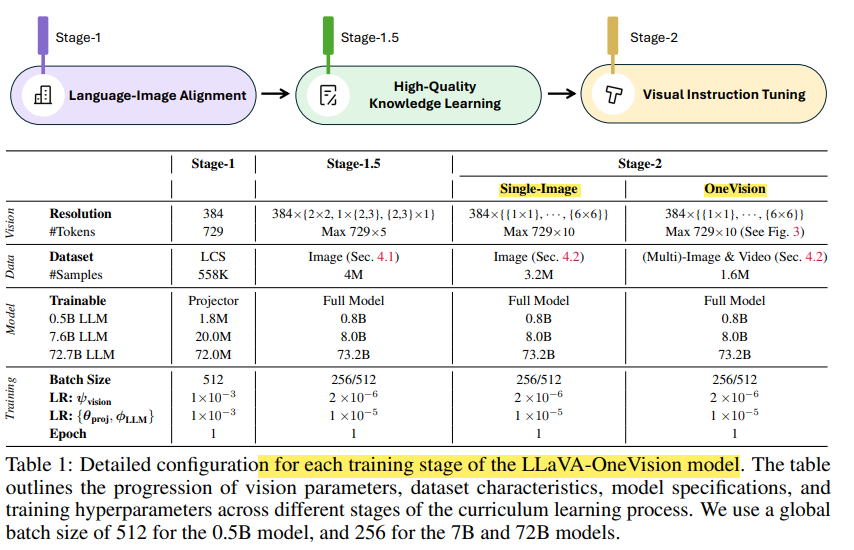
마지막으로, LLaVA-OV 모델은 training 전략을 3 stages(?)로 구성합니다!
1. Language-Image Alignment
2. High-Quality Knowledge Learning
3. Visual Instruction Tuning (2 phases로 구성)
- 1단계: Single-Image Training
- 2단계: OneVision Training

특이하게, stage 3(?)에서는 2 phases로 구성되는데 single-image 그리고 OneVision training 입니다
각각의 phases 이름은, 위에 보이는 데이터셋의 구성을 의미합니다!
(OneVision은 single-image를 포함하여 multi-image, video dataset도 포함)
또한, stage-1에서는 vision projection만 훈련하고 나머지 stage에서는 full model을 훈련하게 됩니다!

- 아마 위에 부분이, high-quality knowledge dataset을 언급하고 있는 것 같습니다 (1.5 stage)
- 1 stage에서는, LLaVA-NeXT의 pre-training stage에서 활용했던 dataset을 이용하고, 나머지는 위에 언급된 순서대로 stage 1.5와 2를 훈련하는 것 같습니다.
Result

Furthermore
LLaVA-Video 논문리뷰: https://kyujinpy.tistory.com/158
[LLaVA-Video 논문 리뷰] VIDEO INSTRUCTION TUNING WITH SYNTHETIC DATA
*LLaVA-Video를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! LLaVA-Video paper: https://arxiv.org/abs/2410.02713 Video Instruction Tuning With Synthetic DataThe development of video large multimodal models (LMMs) has
kyujinpy.tistory.com
*LLaVA 시리즈 마지막으로, Video를 효과적으로 이해할 수 있도록 데이터셋을 만들어 훈련한 LLaVA-Video 모델을 살펴봅시다!
- 2024.10.12 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!
(*가독성을 위해서, 광고를 상-하단에만 설정했는데 광고가 많이 노출되면 알려주세요!!)



