*LLaVA를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
LLaVA github: https://llava-vl.github.io/
LLaVA
Based on the COCO dataset, we interact with language-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please
llava-vl.github.io
Contents
2. Background Knowledge: LLM, CLIP
5. Furthermore: LLaVA-1.5
Simple Introduction

최근에 LLM에 대한 관심이 급격히 증가하면서, LMM에 대한 관심과 성능도 기하급수적으로 높아지고 있습니다.
LMM은 Large Multi-Modal의 약자로, text뿐만 아니라 image, video, audio 등등도 동시에 이해하는 모델을 의미합니다!
LMM은 인간에게 보다 높은 상호작용을 제공하고, 자유도가 높은 답변을 제공할 수 있습니다!
이러한 LMM 분야에서, 오픈소스로 유명한 모델이 바로 LLaVA입니다
LLaVA를 리뷰하면서, 어떻게 모델을 훈련하고 데이터셋을 구성했는지 살펴봅시다!
(*한국어 LMM도 슬슬 도전..?)
Background Knowledge: LLM, CLIP
*LLaVA 논문 자체가 어렵지 않기 때문에, 쉽게 이해하실 수 있습니다!
GPT-1 논문리뷰: https://kyujinpy.tistory.com/74
[GPT-1 논문 리뷰] - Improving Language Understanding by Generative Pre-Training
*GPT-1를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! (학기중이라 블로그를 자주 못 쓰는데.. 나중에 시간되면 ChatGPT도 정리해서 올릴께요. 일단 간단한 GPT부터..ㅎㅎ) GPT-1 paper: h
kyujinpy.tistory.com
LLM에 대한 기본 구조 이해가 필요합니다!
만약 개념이 헷갈리신다면, LLM의 시초라고(?) 불릴 수 있는 GPT-1 논문을 추천드립니다!
(*LLM 관련 내용들은 너무나 많기 때문에, 직접 찾아보시는 것도 추천드립니다!)
CLIP 논문리뷰: https://kyujinpy.tistory.com/47
[CLIP 논문 리뷰] - Learning Transferable Visual Models From Natural Language Supervision
*CLIP 논문 리뷰를 위한 글입니다. 질문이 있다면 댓글로 남겨주시길 바랍니다! CLIP paper: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org) Learning Transferable Visual Models From Natu
kyujinpy.tistory.com
또한, text와 vision을 함께 활용하는 모든 모델에서 이용하고 있는 CLIP 모델에 대한 이해도 필요합니다!
Method
Model Architecture
LLaVA는 기본적으로, base LLM을 둡니다! (예를 들면, Llama-instruct, Gemma-2, 등등...)
그리고 이미지 정보를 text와 함께 이해하기 위해서, vision encoder & projection layer를 추가하게 됩니다!
좀 더 자세히 정리하면 아래와 같습니다!
1. Vision Encoder: pre-trained CLIP 모델을 encoder로 활용. (논문에서는 ViT-L/14 모델 활용)
->> Z_v라는 visual feature 생성
2. 그 다음, trainable layer W를 추가해서 embedding tokens H_v를 생성합니다!
Model Training
LLaVA는 multi-turn 대화 데이터를 활용합니다!
이때, instruct X_q와 answer X_a를 순차적으로 배열하여 모델에 넣어줍니다.
(첫번째 instruction일 때, vision sequence 같이 넣음)

좀 더 구체적으로 살펴보겠습니다! 위의 Table 2.에 있는 prompt을 기반으로 모델에 text-sequence를 넣어주게 됩니다!
X_system-message는 모델의 readbility를 위해서 넣어줍니다!
그리고, <STOP>이라는 token과 모델의 answer에 대한 token을 동시에 고려해서 모델을 훈련시키게 됩니다!

마지막으로, LLaVA는 pre-training stage와 fine-tuning stage를 활용합니다!
Pre-training stage에서는, visual projection layer (W layer) 부분만 학습을 진행합니다!
-> 여기서 595K의 image-text pairs를 활용해서 훈련합니다. (1 epoch)
Fine-tuning stage에서는, visual projection layer (W layer)와 LLM 부분을 훈련합니다!
-> 여기서는, 보통 LLaVA-Instruct-158K라는 데이터셋으로 3 epochs 훈련하게 됩니다!
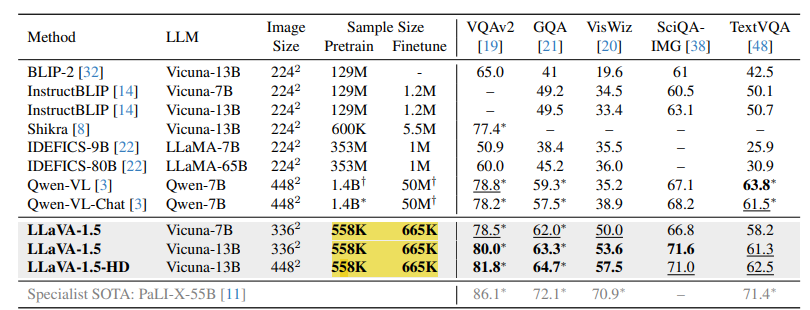
아주 간단한 방법론과 상대적으로 적은 데이터셋으로, 기존 LMM 모델보다 높은 성능을 쉽게 달성했다는 것에서 큰 의의가 있는 것 같습니다!!
(*참고로 데이터셋은 GPT-4/ChatGPT의 도움을 통해 좀 더 디테일한 caption을 생성했다고 합니다.)
Result
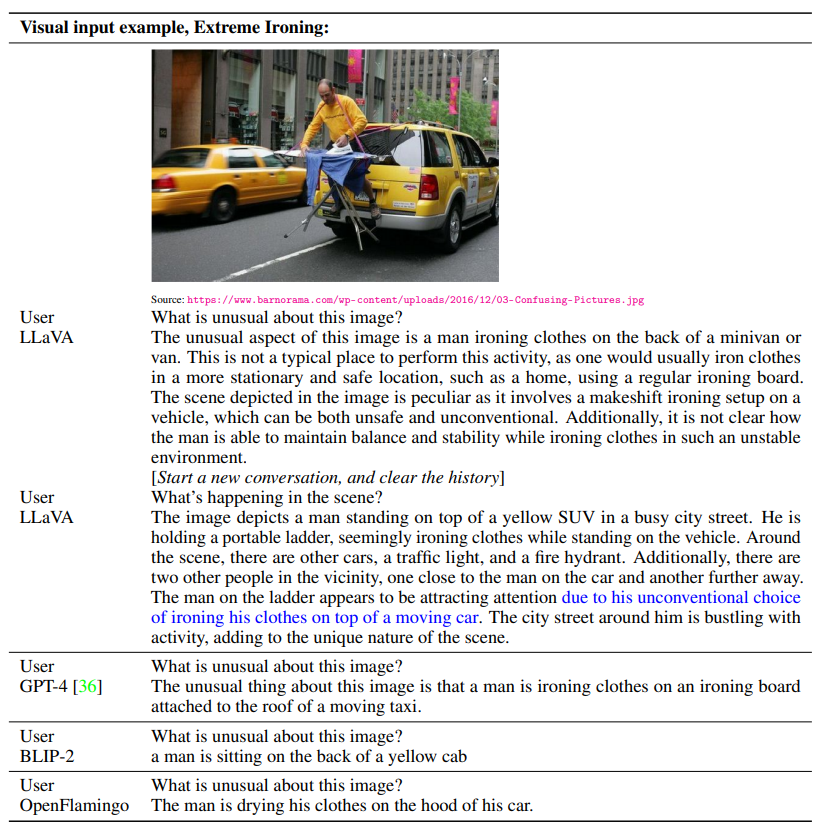

Furthermore
LLaVA-1.5 논문리뷰: https://kyujinpy.tistory.com/157
[LLaVA-NeXT 논문 리뷰] Improved Baselines with Visual Instruction Tuning
*LLaVA-NeXT를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! LLaVA-Next Github: https://github.com/LLaVA-VL/LLaVA-NeXT GitHub - LLaVA-VL/LLaVA-NeXTContribute to LLaVA-VL/LLaVA-NeXT development by creating an account on
kyujinpy.tistory.com
LLaVA에서 한층 improve된 1.5 version과 LLaVA-NeXT (1.6 version)은 어떠한 차별점이 있는지 알아봅시다!
- 2024.10.10 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!



