*Mamba 논문 리뷰 시리즈5 입니다! 궁금하신 점은 댓글로 남겨주세요!
시리즈 1: Hippo
시리즈 2: LSSL
시리즈 3: S4
시리즈 4: Mamba
시리즈 5: Vision Mamba
Vision Mamba paper: [2401.09417] Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model (arxiv.org)
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Recently the state space models (SSMs) with efficient hardware-aware designs, i.e., the Mamba deep learning model, have shown great potential for long sequence modeling. Meanwhile building efficient and generic vision backbones purely upon SSMs is an appea
arxiv.org
GitHub - kyegomez/VisionMamba: Implementation of Vision Mamba from the paper: "Vision Mamba: Efficient Visual Representation Lea
Implementation of Vision Mamba from the paper: "Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model" It's 2.8x faster than DeiT and saves 86.8%...
github.com
Contents
2. Background Knowledge: Mamba
5. Code
Simple Introduction

드디어, Mamba 논문 리뷰 시리즈의 마지막!!
Vision Mamba를 리뷰 해보겠습니다!
Vision Mamba (ViM)는 ViT와 굉장히 유사한 개념이라고 생각하시면 됩니다!
Transformer에서 ViT로 넘어간 흐름 같이, backbone이 mamba로 바뀌었다고 생각하시면 전반적인 이해를 완료되었다고 볼 수 있습니다!
ViM은 기존 여러 모델들에 비해 성능이 좋으면서 gpu memory 및 FPS 측면에서 효율성도 챙긴 아주 훌륭한(?) 모델입니다
아마 앞으로의 딥러닝 트렌드는 mamba를 위주로 돌아가지 않을까 싶네요!
한번 같이 논문 리뷰 읽어보시죠!
Background Knowledge: Mamba
Mamba 논문 리뷰: https://kyujinpy.tistory.com/149
[Mamba 논문 리뷰 4] - Mamba: Linear-Time Sequence Modeling with Selective State Spaces
*Mamba 논문 리뷰 시리즈4 입니다! 궁금하신 점은 댓글로 남겨주세요!시리즈 1: Hippo시리즈 2: LSSL시리즈 3: S4시리즈 4: Mamba시리즈 5: Vision MambaMamba paper: https://arxiv.org/abs/2312.00752 Mamba: Linear-Time Sequence
kyujinpy.tistory.com
- Mamba를 이해하셔야 Vision Mamba (ViM)를 이해하실 수 있습니다!
- Transformer -> ViT 느낌?
Method
Preliminaries: SSM-based models
가볍게 SSM-based models에 대해서 리마인드 겸(?), 짚어보고 가겠습니다!

기존 SSM의 경우, 연속적인 데이터가 입력으로 들어왔을 때 A, B, C라는 projection parameters로 output y를 표현하는 것이 핵심 아이디어 입니다! (여기서 A는 state matrix로 아주 중요한 역할을 했다는 것도 잊지 말아주세요(?))

근데, 저희가 다루는 데이터들은 연속적인 경우보다는 이산적인 경우가 훨씬 많습니다.
따라서, 기존의 A, B parameters의 특성을 유지하면서 이산적인 시간에 따라서 잘 표현될 수 있도록 transform하는 것이 필요합니다!
여기서 우리는 timescale parameter ∆를 정의하고, 이를 활용하여 equation (2)와 같이 이산적인 projection parmaeters를 만들었습니다!
여기까지 가볍게 SSM에 대해서 살펴보았고, mamba가 vision 분야에 어떻게 접목되었는지 살펴보시죠!
Vision Mamba

Vision Mamba의 전체적인 architecture 입니다!
ViT와 똑같이, input image를 patchify로 수행해서 patches를 생성합니다!
그리고, 1D flatten과 linear projection을 적용하고, class token *을 추가합니다.
ViM encoder에 들어가기 전에 positional encoding을 각각의 순서에 맞게 더해줍니다!


그리고, class token에 해당하는 부분에 대해서만 normalization과 MLP를 적용해서 최종적인 prediciton을 수행하게 됩니다!
*(개인 생각) 논문에 ViM의 구조를 보면, class token *이 중간에 껴있는데, 실제 수식을 보면 맨 앞에 붙어있는 것을 볼 수 있습니다! 어떤 의도인지는 모르겠지만(?), class token의 위치가 크게 상관없다는 의미일 수도 있습니다(?)
ViM Block

기존 mamba 구조의 경우 1D-sequence를 이해하기 위한 목적으로 만들어졌습니다!
논문의 저자들은, mamba의 구조를 그대로 이용하면 sptial-aware understanding에 대한 작업이 충분하지 않을 수 있다고 얘기하면서 ViM block을 소개합니다!

ViM algorithm에 대한 이미지를 보면 위와 같습니다!
(1) Input token sequence T_{l-1}에 대해서 normalization 수행
(2) Normalized된 T_{l-1}을 2개의 lienar layer를 통과해서 x와 z로 분할
(3-1) (x에 대해서) 2개의 path로 분할이 됨: forward와 backward directions
(3-2) 각각의 path에 대해서 1D-Conv 연산와 SiLU activtion function을 수행.
(3-3) 그리고, 각각에 대해서 lienar projection을 적용해서 각각의 path에 대한 Bo, Co, ∆o를 생성. (line 8~11)
(3-4) 위에서 생성한 Timescale parameter ∆o를 통해서 각각 path에 대한 Ao^{bar}와 Bo^{bar}도 생성 (line 12~14)
(4) 각각의 direction에 대해서 yo를 만들고, z와 곱해서 y_forward와 y_backward를 생성 (line 18~19)
(5) 최종적으로, forward와 backward 결과를 더하고 linear projection 적용한 후 이전의 T_{l-1}를 더해서 T_{l} 생성!
Result
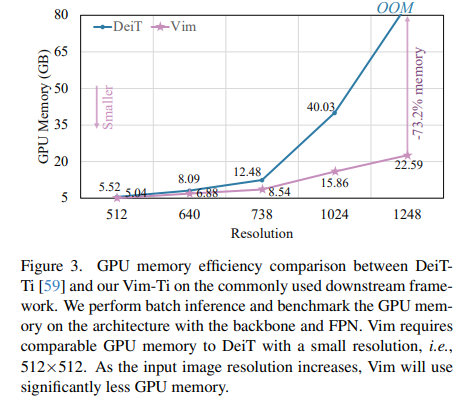
- GPU memory efficiency 측면에서도 매우 효과가 좋다

- ImageNet-1K 및 다양한 데이터셋에 대해서 SOTA를 달성!
Code Review
# 10/18 수정
## https://github.com/hustvl/Vim/blob/1be434d49d81f24c7d1aef3f4729d6e64a1c3c62/vim/models_mamba.py#L229
class VisionMamba(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
stride=16,
depth=24,
embed_dim=192,
d_state=16,
channels=3,
num_classes=1000,
ssm_cfg=None,
drop_rate=0.,
drop_path_rate=0.1,
norm_epsilon: float = 1e-5,
rms_norm: bool = True,
initializer_cfg=None,
fused_add_norm=True,
residual_in_fp32=True,
device=None,
dtype=None,
ft_seq_len=None,
pt_hw_seq_len=14,
if_bidirectional=False,
final_pool_type='none',
if_abs_pos_embed=True,
if_rope=False,
if_rope_residual=False,
flip_img_sequences_ratio=-1.,
if_bimamba=False,
bimamba_type="v2",
if_cls_token=True,
if_divide_out=True,
init_layer_scale=None,
use_double_cls_token=False,
use_middle_cls_token=True, ## middle_class 넣는 부분
**kwargs):
....(생략)....
def forward(self, x, return_features=False, inference_params=None, if_random_cls_token_position=False, if_random_token_rank=False):
x = self.forward_features(x, inference_params, if_random_cls_token_position=if_random_cls_token_position, if_random_token_rank=if_random_token_rank)
if return_features:
return x
x = self.head(x)
if self.final_pool_type == 'max':
x = x.max(dim=1)[0]
return x
def forward_features(self, x, inference_params=None, if_random_cls_token_position=False, if_random_token_rank=False):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
x = self.patch_embed(x)
B, M, _ = x.shape
if self.if_cls_token:
if self.use_double_cls_token:
cls_token_head = self.cls_token_head.expand(B, -1, -1)
cls_token_tail = self.cls_token_tail.expand(B, -1, -1)
token_position = [0, M + 1]
x = torch.cat((cls_token_head, x, cls_token_tail), dim=1)
M = x.shape[1]
else:
## Token 중간에 넣음
if self.use_middle_cls_token:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = M // 2
# add cls token in the middle
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
elif if_random_cls_token_position:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = random.randint(0, M)
x = torch.cat((x[:, :token_position, :], cls_token, x[:, token_position:, :]), dim=1)
print("token_position: ", token_position)
else:
cls_token = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
token_position = 0
x = torch.cat((cls_token, x), dim=1)
M = x.shape[1]
...(생략)...
# mamba impl
residual = None
hidden_states = x
if not self.if_bidirectional:
for layer in self.layers:
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
# rope about
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
if if_flip_img_sequences and self.if_rope:
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
hidden_states, residual = layer(
hidden_states, residual, inference_params=inference_params
)
else:
# get two layers in a single for-loop
for i in range(len(self.layers) // 2):
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residual:
residual = self.rope(residual)
hidden_states_f, residual_f = self.layers[i * 2](
hidden_states, residual, inference_params=inference_params
)
hidden_states_b, residual_b = self.layers[i * 2 + 1](
hidden_states.flip([1]), None if residual == None else residual.flip([1]), inference_params=inference_params
)
hidden_states = hidden_states_f + hidden_states_b.flip([1])
residual = residual_f + residual_b.flip([1])- Vision Mamba 코드 입니다!
- 중간에 use_middle_cls_token 부분을 통해서 class token이 중간에 들어가는 것을 확인할 수 있습니다!
- 또한 forward / backward SSM을 수행하기 위해서 2개의 layers를 확인하는데, 여기서 주의깊게 보셔야할 점은 방향이 다르게 들어간다는 점입니다!!
--> 하나는 그대로, backward에서는 flip을 해서 input함.
- 2024.09.11 Kyujinpy 작성.
최근에 논문 작성이 마무리 되느라 바빠서 논문 리뷰 글을 꾸준히 올리지 못했습니다..ㅎㅎ
*광고 수익은 연말에 기부를 할 생각입니다!



