*MeshAnything를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
MeshAnything paper: https://arxiv.org/abs/2406.10163
MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
Recently, 3D assets created via reconstruction and generation have matched the quality of manually crafted assets, highlighting their potential for replacement. However, this potential is largely unrealized because these assets always need to be converted
arxiv.org
MeshAnything github: https://buaacyw.github.io/mesh-anything/
MeshAnything
Recently, 3D assets created via reconstruction and generation have matched the quality of manually crafted assets, highlighting their potential for replacement. However, this potential is largely unrealized because these assets always need to be converted
buaacyw.github.io
Contents
2. Background Knowledge: VQ-VAE
- Shape-Conditioned AM (Artist-Created Mesh) Generation
- Shape Encoding for Conditional Generation
- VQ-VAE with Noise-Resistant Decoder
- Shape-Conditioned Autoregressive Transformer
Simple Introduction

Mesh generation은 산업 분야에 없어서는 안될, 어찌보면 가장 중요한 요소라고 할 수 있습니다.
우리 주변에 3D 결과물을 이용한 사례들은 상상 이상으로 많이 있는데, 3D 요소들을 산업 분야에 적용하기 위해서는 meshes로의 변환이 필수적입니다!
기존 mesh generation 방법이나 3D 생성 모델들은, mesh 생성을 위해 marching cubes 또는 Remesh (모델) 알고리즘을 많이 활용했습니다.
다만, 기존의 방법들의 경우 기하적 특성을 반영하지 않거나 dense faces를 요구하기 때문에, 비효율적이나 low quality의 mesh가 만들어지게 됩니다.
이러한 단점들을 모두 보완한 것이, 바로 MeshAnything 모델입니다!
최근에는, MeshAnything v2도 나왔는데요..!
MeshAnything 논문리뷰를 더이상 미룰 수가 없을 것 같아서(?), 상세한 논문 리뷰로 준비했습니다!
Background Knowledge: VQ-VAE
개인적으로(?) 추천하는 논문 리뷰 References
[논문 리뷰] VQ-VAE: Neural Discrete Representation Learning
SSL(Self-Supervised Learning) 이해하기 네번째!
velog.io
- https://greeksharifa.github.io/discrete%20representation/2021/11/07/VQVAE/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
*MeshAnything 논문의 경우, VQ-VAE에 나오는 codebook 개념을 명확히 알고 계셔야 이해가 편하십니다!
Method
Shape-Conditioned AM (Artist-Created Mesh) Generation
간단하게 MeshAnything의 목적에 대해서 살펴봅시다!
3가지 symbols (M is meshes, C is condition, and S is shape information)를 활용해서 정의를 할 예정입니다!
Condition은 images, text 등등이 예시이고, Shape information은 point-cloud 입니다!
Equation (1)의 경우, 기존 mesh generation model의 수식을 보여주고 있습니다!
여기서 우리는 chain-rule에 의해서 equation (2)로 변환할 수 있다는 사실도 알고 있습니다,
또한 직관적으로, mesh를 생성할 때 C보다는 S가 더욱 강력한 조건이기 때문에 equation (3)처럼 근사시킬 수 있습니다.
위의 equations (1) ~ (3)를 전부 통합해서 equation (4)를 이끌어낼 수 있습니다.
MeshAnything 모델은 p(M|S)에 해당하는 부분으로, shape information을 통해서 mesh를 생성하는 것이 목적입니다!
-> 옆에 p(S|C) 부분은, pre-trained model이 담당하는 부분인 것 같습니다.
-> Condition을 통해서 point cloud (shape information)을 만드는 부분.
Shape Encoding for Conditional Generation

논문의 저자들은, p(M|S)에 대한 분포를 학습할 때 shape information으로 point cloud를 활용하게 됩니다.
이때, 학습에 필요한 point cloud를 ground truth M (mesh)를 통해서 추출하게 되는데요..!
아래의 3가지 steps을 통해서 추출을 진행합니다.
1. SDF (signed distance function) 계산
2. marching cubes를 적용하여 mesh 생성 (*normal plane으로 변환하는 것도 있는 것 같음)
3. 생성된 mesh로부터 point cloud sampling (4096 points)
이렇게 생성된 point cloud와 meshes 간의 관계를 VQ-VAE와 autoregressive transformers를 통해서 학습하게 됩니다..!
VQ-VAE with Noise-Resistant Decoder

VQ-VAE는 transformer로 이루어진 encoder-decoder 구조를 활용합니다!
또한, VQ-VAE input으로 mesh를 discretized하고, mesh를 구성하는 triangle faces를 sequence로 넣어줍니다.
Encoder를 통해서 나온 feature vector를 8,192 size의 codebook에 mapping 시키고, decoder를 통해서 reconstructed mesh를 생성하게 됩니다!
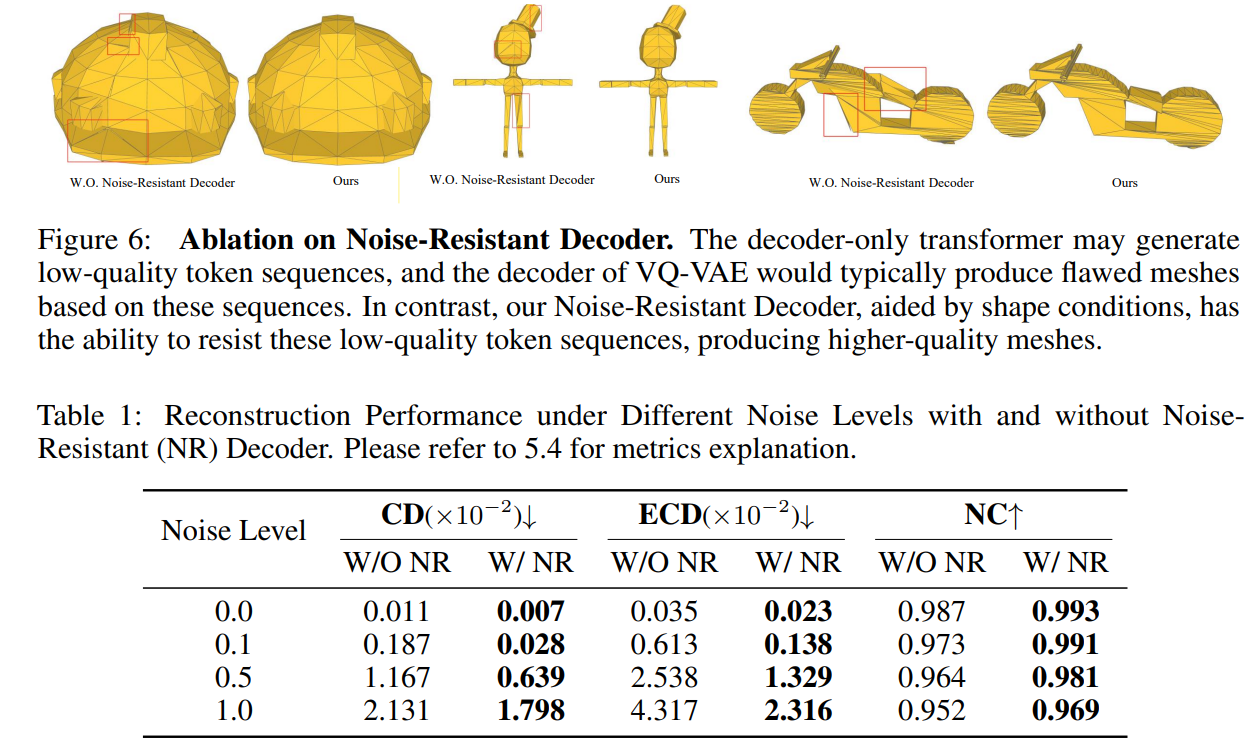
논문의 저자들은, 이렇게 만들어진 VQ-VAE를 inference를 해보니 generation result에 imperfection이 존재하는 것을 발견했습니다 (*여러 원인이 있겠지만, training 데이터로 general한 training을 하기에는 정보 학습에 한계가 있었을 수도...?)
Figure 6와 같은 현상을 방지하고 성능을 높이기 위해 2가지 방안을 제안했습니다!
1. Codebook에 noise 추가 (random Gumble noise)
2. Fine-tuning 진행
-> Decoder 부분에 shape information을 더해주는 형태로 활용
이를 통해서, imperfection한 결과물에 대한 token sequence에 대해서 제대로 모델이 이해할 수 있다고 합니다..!
VQ-VAE 모델을 학습할 때는 2가지 loss functions을 활용하고 있습니다ㅑ
1. Vertex coordinate logits 값에 대한 cross-entropy loss
2. Codebook과 encoder에 대한 commitment loss
+) fine-tuning할 때는 decoder에 cross-entropy loss를 적용해서 훈련합니다!
마지막으로, VQ-VAE로 학습한 mesh information을 어떻게 point cloud로 옮겨서 학습하는지 알아봅시다!!
Shape-Conditioned Autoregressive Transformer


마지막으로, autoregressive transformer 부분입니다!
Autoregressive transformer는 LLM에 자주 활용되는 transformer 구조로, masked multi-head attention을 토대로 next token prediction을 한다고 생각하시면 됩니다!
앞서 훈련한 VQ-VAE의 encoder-decoder가 tokenizer & de-tokenizer라고 생각한다면, autoregressvie transformer는 point cloud와 mesh 사이의 관계를 매핑해서 decoder로 보내주는 역할을 하게 됩니다!
Autoregressive transformer 모델 훈련 순서는 아래와 같습니다!
1. Pre-trained point encoder를 통해서 3D point cloud에 대한 feature vector p(S) 생성.
2. Trainable linear projection layer을 통해서, p(S)의 dimension을 codebook size와 동일하게 맞추기
3. mesh를 input으로 VQ-VAE encoder에 넣어서 latent vector (codebook) T를 추출하여, p(S)와 concatenate 수행
4. Autoregressive transformer에 concat vector를 넣어서 output vector 생성
5. VQ-VAE decoder에 넣어서 mesh 예측
(*linear projection layer와 transformer만 학습하며, vertex coordinate에 대한 cross-entropy loss를 활용합니다!)

Inference 과정은 매우 단순해 집니다!
1. p(S)를 autoregressive transformer에 넣음.
2. Transformer에서 나온 output vector를 VQ-VAE decoder를 통해서 mesh generation을 수행함.
한가지 추가사항은, LLM처럼 <bos> token과 <eos> token을 활용해서 point-cloud token과 mesh token을 구별한다는 점입니다!
Dataset
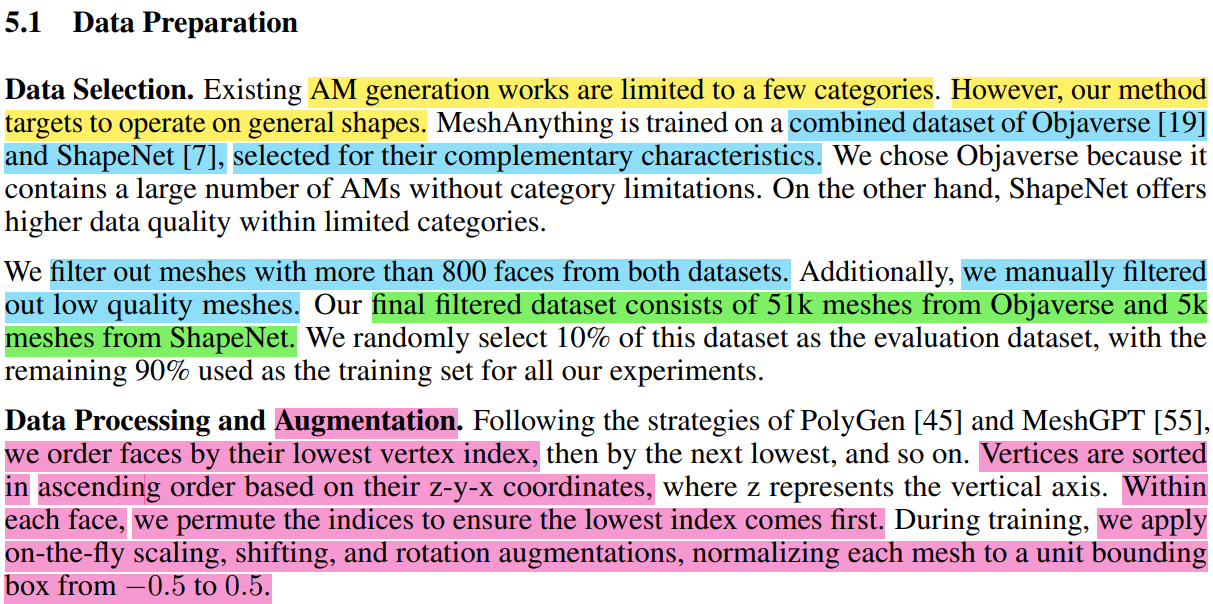
Dataset을 선택할 때, Objaverse와 ShapeNet 2개를 통합해서 훈련을 진행했습니다!
물론, 2가지 기준을 통해서 filtering을 수행해서 데이터 개수를 56K로 조절했습니다
1. 800 faces 이상의 mesh 데이터 제거
2. 직접 mesh의 품질 검수
또한, 훈련하기에 앞서 data processing과 augmentation을 추가로 진행하는데요!
Data processing은 3가지가 있습니다.
1. 낮은 vertex index 순서대로 facces 정렬
2. 각 faces 안에서 낮은 index가 앞으로 오도록 정렬
3. Vertex coordinate 순서는 z-y-x 순으로 정렬
Augmentation은 scaling, shifting, rotation 방법을 적용하였고, [-0.5, 0.5] 사이의 unit bounding box로 normalization도 진행합니다!
Result

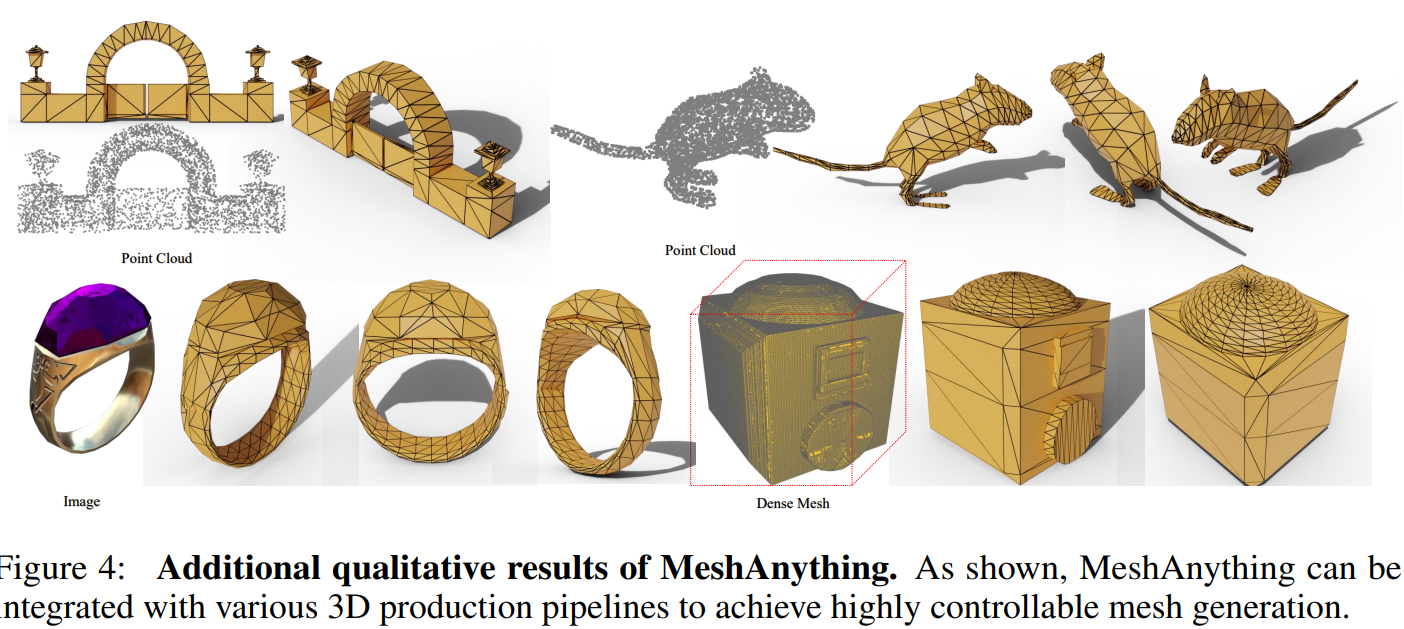
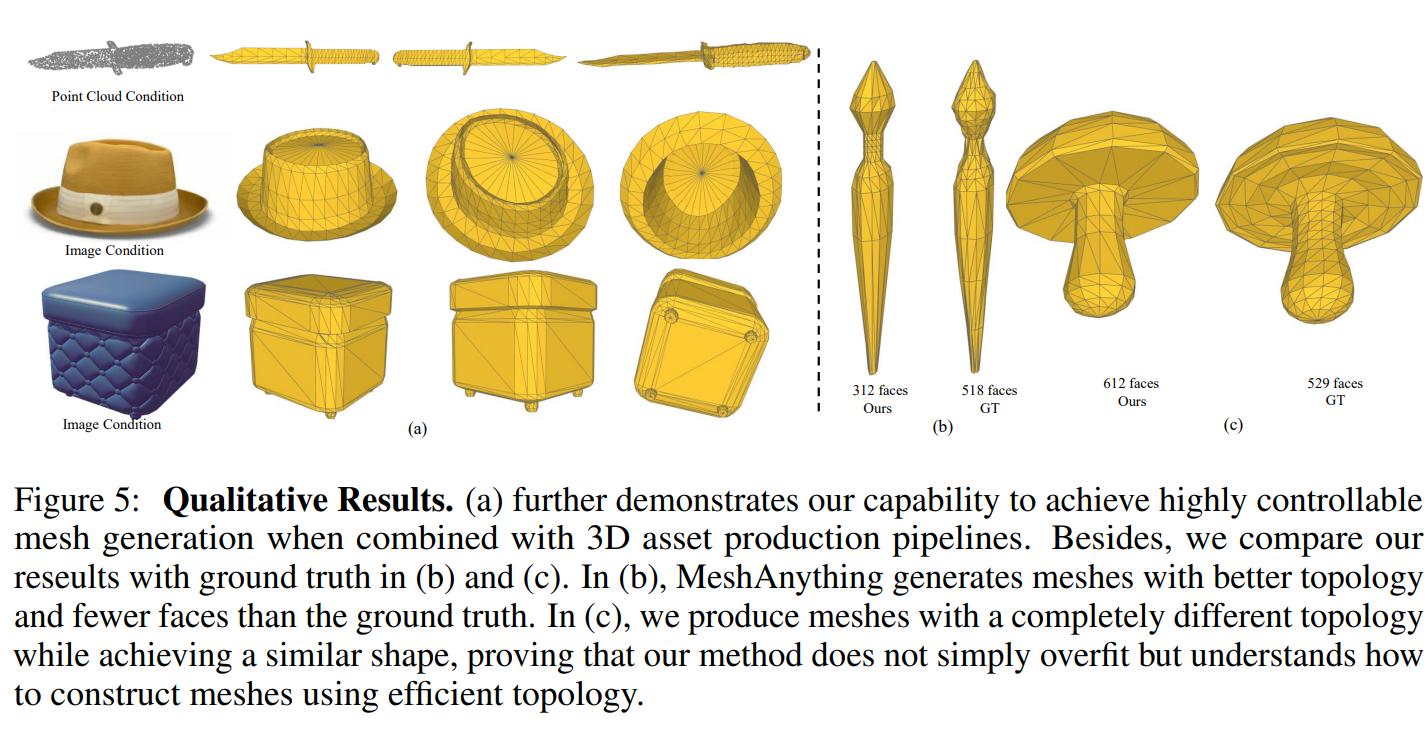
- 2024.09.19 Kyujinpy 작성.
*광고 수익은 연말에 기부를 할 생각입니다!



