*이 글의 목표: Hash-encoding 완전 이해하기!!! (부셔버려!!)
*Instant-NGP를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
Instant-NGP paper: nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
Instant-NGP github: GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
Instant neural graphics primitives: lightning fast NeRF and more - GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
github.com
HashNeRF github: GitHub - yashbhalgat/HashNeRF-pytorch: Pure PyTorch Implementation of NVIDIA paper on Instant Training of Neural Graphics primitives: https://nvlabs.github.io/instant-ngp/
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
nvlabs.github.io
Contents
Simple Introduction

Instant-NGP는 NeRF에서 가장 획기적이라고 할 수도 있는 모델 중 하나이다.
Inference time을 단 5s로 바꿔버릴 정도로 엄청나게 빠른 스피드와 높은 성능을 보인다.
과연 어떻게 그럴 수 있었을까?
가장 중요한 열쇠는 바로 Hash-encoding이다.
오늘 리뷰에서는 이 Hash-encoding에 대해서 제대로 부셔버릴(?) 예정이다.
코드와 함께 리뷰하니 잘 따라오기를 바란다..!
Background Knowledge: NeRF
NeRF: https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
오늘 리뷰 글에서는 NeRF에서 소개된 ray의 개념, sampling, voxel grid 등등과 같은 내용은 모두 생략하고 hash-encoding을 자세히 리뷰하고, 모델 구조를 간략하게 볼 예정이다.
*NeRF를 알고 있다는 가정 하에서 논문리뷰가 진행됩니다.
Method
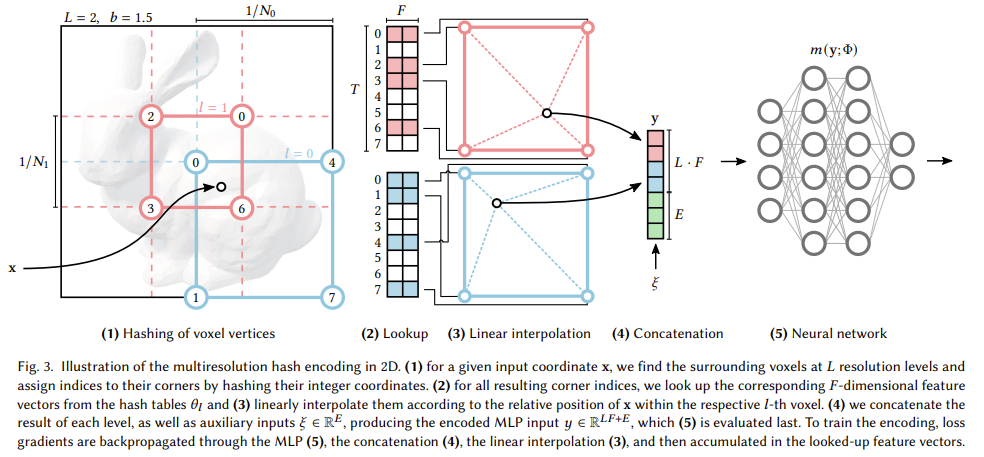
Instant-NGP는 hash-encoding을 통해서 각 coordinate에 대해서 embedding을 만들고 이를 model의 MLP에 넣어서 훈련하는 과정으로 이루어진다.
기존의 NeRF에서 제안한 positional encoding과는 다른 방법으로, 해당 hash-encoding은 trainable parameters를 이용한다는 점과 hash table를 이용한다는 점에 있다.
앞으로 나올 알고리즘 소개 과정에서 levels(L), hash tabel size(T), feature dimensions(F)를 위주로 놓치지 않고 설명을 읽으면 hash-encoding을 이해할 수 있을 것이라고 생각한다!
Hash-encoding

먼저 중요한 symbols을 정의하고 가보겠다!
1. L은 levels을 의미한다. L은 hash table의 크기(resolution)과 연관이 있다.
2. F는 최종적으로 나오는 position embedding의 dimension이다.
3. T는 각 level의 entry가 가지는 최대 hash table size (추후 설명)
4. l은 0~L-1의 값을 가진다.
1. Hashing of voxel vertices
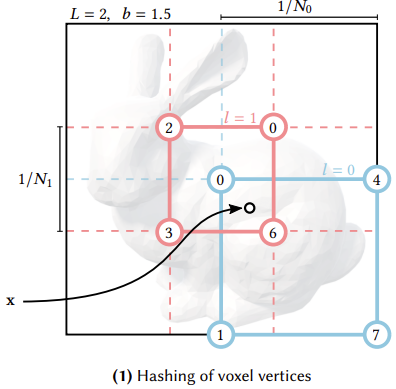
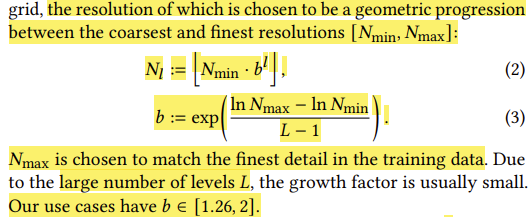
해당 단계에서 주요하게 볼 키워드는 Levels와 resolution이다.
1. Nmin과 Nmax를 정의한다.
- 논문에서 Nmin은 16, Nmax는 512~524288(219) 값을 이용한다.
- Nmax는 training data에 따라서 조금씩 변형해서 사용하면 된다.
2. Nmin과 Nmax를 이용하여 equation 3에 넣어서 b를 정의한다.
- 논문에서 b는 주로 [1.26, 2] 사이 값을 가진다고 나온다.
3. 그 이후 levels에 따른 l 수준에 따라서 Nl을 equation 2로 정의한다.
여기서 정의되는 Nmin과 Nmax는 hash table의 resolution을 결정 짓는 역할을 한다.
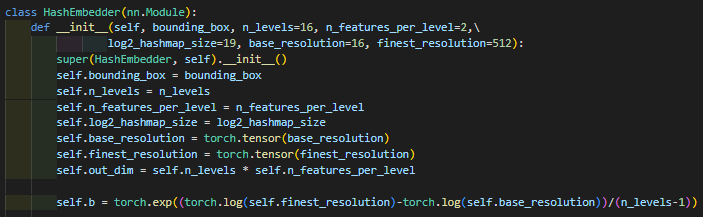
코드를 보면 위의 수식처럼 표현될 수 있다.
finest_resolution이 Nmax이고 base_resolution이 Nmin이다.

그러면 이제 논문에 나온 이미지를 이해해보자!
1. L=2, b=1.5로 가정한 이미지이다. (논문에서의 실제 levels은 16이다.)
2. L=2이기 때문에 N0, N1이 존재하게 되는데, N0의 값은 equation 2에 의해서 Nmin*1 이고 N1의 값은 Nmin*1.5이다.
3. 여기서 할당되는 x는 3차원 벡터라고 생각하면 된다. (뒤에서 자세하게 설명; NeRF에서 이용되는 ray의 coordinate 정보이다.)
4. 이미지에서는 2D 모양의 bounding box처럼 보이지만 실제로는 3차원 공간의 bounding box라는 점을 기억하고 있어야 한다!
2. Lookup & Linear interpolation

해당 부분이 여러 테크닉과 function들이 들어있어서 이해하기에 가장 어렵게 느껴질 수 있다.
천천히 설명을 이어나가보겠다!
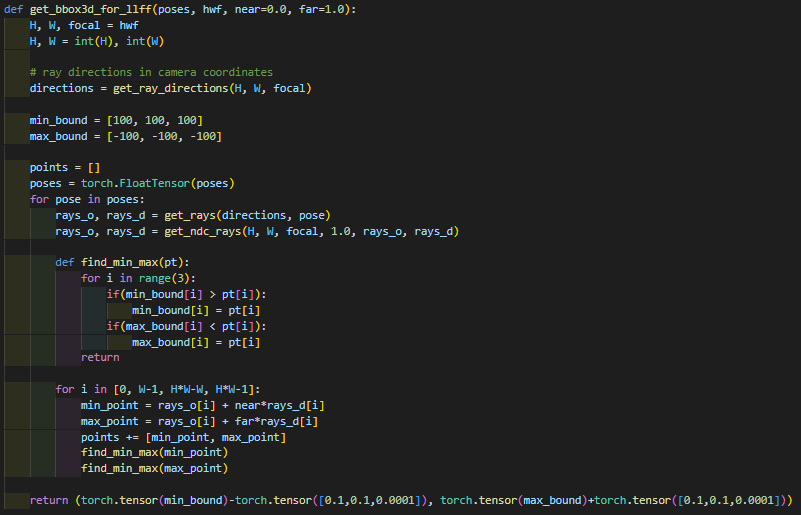
먼저 전체적인 global bounding box를 계산해야한다.
위에 코드에 전체적인 poses와 direction 정보를 활용하여서 객체의 전체적인 bounding_box_max와 bounding_box_min을 계산한다.
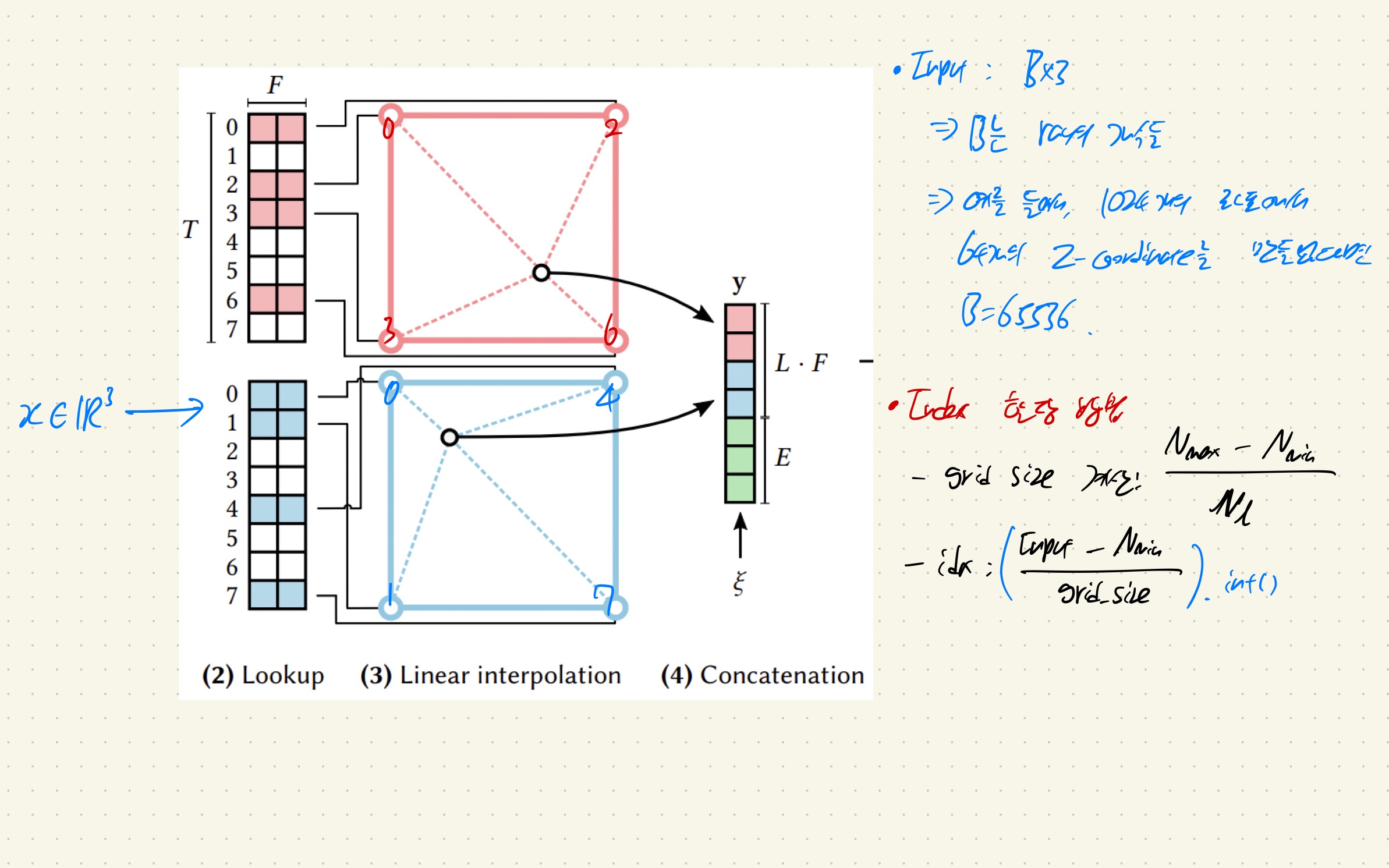
Bounding box를 계산하였으면, Index 할당 방법에 대해서 살펴보자.
논문에서는 해당 부분이 자세히 소개되어 있지는 않은 것 같고, 코드로 봐야 이해가 된다!
1. 일단 input x는 Nx3인 R3 space 상의 vector이다.
- 여기서 N은 ray상 위치하는 좌표의 개수를 의미한다.
- Original NeRF의 예시로, 1024개의 좌표에서 64개를 sampling하면 [1024, 64, 3]이라는 space가 만들어지는데 이것을 모델에 넣기 위해서 flatten 해주는 과정을 걸쳐서 [65536,3]이 된다. 즉 여기서 N이 65536과 같은 의미를 지닌다고 생각하면 편하다.
2. 앞의 Hashing of voxel vertices 과정을 보면 각 entry에 index가 할당되어 있다. 이것은 grid_size를 활용하여 index값을 만든다.
- Grid_size: (Bounding_boxmax - Bounding_boxmin)/Nl
- Index: {(X - Bounding_boxmin)/Grid_size}.int()
- 위의 수식을 통해서 Nx3인 점에는 정수 형태의 indexing이 할당되게 된다.
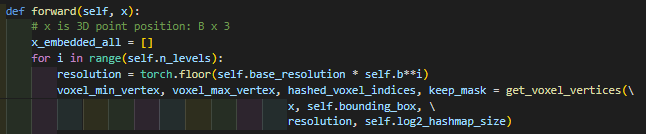

Indexing을 할당하는 코드이다. 여기서 shape 연산을 잘 봐야한다!
여기서 보면 Bounding_box의 min과 max값, 그리고 Nl(resolution)를 활용하여서 grid_size라는 변수를 만든 후, bottom_left_idx라는 값을 활용해서 인덱스를 붙인다.
그 이후 unsqueeze(1)을 통해서 bottom_left_idx의 shape은 (N, 1, 3)이 되고, 여기서 BOX_OFFSETS값을 더해준다.
최종적으로 voxel_indices의 shape은 (N, 8, 3)이 된다.
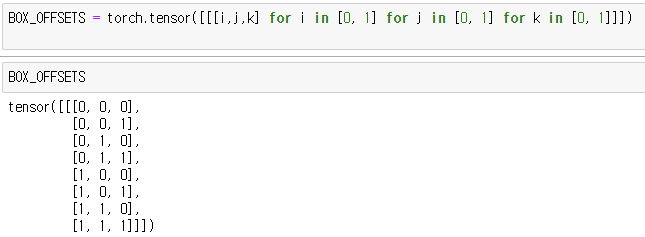
- BOX_OFFSETS의 shape은 (1,8,3)이다.
- Box의 위치를 조정해주는 값이라고 생각하면 될 것 같다.

알고리즘을 이해하기 위한 2번째 단계로 Hash-function이다.

Hash function은 논문에서 위와 같이 소개하고 있다.
여기서 hash function은 XOR-operation으로 정수론의 꽃과 같은 prime number을 이용하여 계산한다. 아마 여기서 Hash의 특징인 고유한 값을 할당한다는 점에서 hash-function이라고 이름이 붙이게 된 것 같다. (Large prime number를 이용해서 그런 것 같음.)
XOR-operation이 무엇인지 먼저 짚고 넘어가겠다.
여기서 말하는 XOR은 bitwise operation을 의미한다고 볼 수 있다.
즉, 두 개의 정수가 있다면 이것을 bit로 표현한 후, 0과 1로 표현된 값을 토대로 XOR를 하는 것이다.
위의 사진의 예시로 a=60, b=13이라면 XOR-operation 연산 결과는 49가 나온다.
그렇다면 Hash-function에서 이루어진 단계는 아래와 같이 표현할 수 있다.
0. 여기서 d는 x의 차원을 말한다. (input x는 Nx3이므로 3차원!)
1. Indexing이 붙여진 x에 대해서 large prime number를 곱하고 이를 XOR operation으로 표현하여 나타낸다.

- 여기서 Large prime number의 종류로 위와 같이 논문의 저자들이 이용하였다.
2. XOR-operation으로 연산된 값에 T(hash table size)로 mod 연산을 한다.
- mod 연산은 쉽게 말해서 소수를 반환한다고 생각하면 된다. (정수론 개념)
3. 최종적으로 여기서 나오는 값은 최대 T size 만큼의 vector를 가질 수 있다.

- 최종적으로 나오는 값이 T size라는 것을 이해했다면 위에 적혀진 논문의 저자의 말을 이해할 수 있을 것이다.
- 임의로 T=2^19라고 가정해보겠다. (x의 input이 Nx3이라고 가정;)
- 일단 levels 수준 l에 해당하는 x의 값은 Z3 공간에서의 8개의 꼭짓점을 가지는 voxel의 span이라고 표현할 수 있다.
- 3차원 공간에서 Hash function에서 연산된 값은 (N, 8)의 형태를 띈다. 만약 N*8이 T보다 큰 값을 가지게 된다면, hash-function에서 1:1 mapping이 이루어지지 않는다.
- 따라서, N*8는 무조건 T보다 작아야 되고, 예를 들면 (Nl+1)^3의 값이 T보다 같거나 작아야 한다는 것이 조건이 될 수 있다.

hash-function을 코드로 나타낸 것이다.
Large-prime number들이 있고 XOR-operation을 한 후, 마지막 return할 때 mod T를 수행한다.
mod T를 위와 같이 표현한 이유는 (개인적인 생각) 일반적으로 mod를 계산하기에는 large prime number에 대해서 너무 시간이 오래 걸리기 때문에 정수론 트릭을 이용해서 위와 같이 나타내었다고 생각하면 편하다.
+) For example) T-1=2(^19)-1이면 bitwise로 1111111111111111111이 된다.
+) 1<<log2_hashmap_size = 2^19

마지막 단계로 vector를 concatenate하는 것이다.
1. Hash-function을 걸쳐서, 최종적으로 (N, 8) vector가 형성되었다. (T는 hash table size)
2. 여기서 trainable parameters를 이용하여서 각 entry마다 F dimensions을 가지도록 embedding을 학습한다. (논문에서 F=2)
- 따라서 (B, 8, F) vector가 된다.
- 여기서 embedding의 parameters는 (T, F)이다.
- 즉, 3차원 공간상의 voxel cube의 각 entry들에 대해서 2차원 벡터가 mapping 된 것이다.
- 위의 이미지에서도 빨간색과 파란색이 앞에 보이는 entry를 의미하고, 흰색은 뒤에 있는 entry를 의미한다. (3D 관점)
3. 그리고 x에 대해서 trilinear interpolation 방법을 이용하여서, 최종적인 2차원 벡터를 만든다.
4. 또한 levels이 L개 있으므로, F*L개의 vector가 최종적으로 hash-encoding을 통해서 만들어진다.
5. 여기서 E는 view direction에 해당하는 encoding 값으로, 논문에서는 auxiliary vector로 표현하고, 이 값도 concatenate해서 최종적으로 y는 RLF+E vector를 가지게 된다.

코드로 보면 위와 같은 형태이다.
(N, 8, 2) 형태인 voxel_embedds을 토대로 x에 대해서 trilinear_interpolation을 진행하고 concatenate하는 형태로 이루어진다.
추가적으로 trainable parameter인 θ는 uniform distribution을 따르도록 intialization 된다.
+) 여기서 (N, 8)인데 (T, F)인 embedding vector를 만나면 어떻게 (N, 8, F)가 되는지 궁금한 사람들이 있을 것 같다.
+) nn.embedding()이 만약 (T, F)이라면, '최대 T개의 벡터를 F차원으로 늘려준다'라고 생각하면 된다.
+) 기존의 딥러닝 weights와는 약간 다르게 이해하면 편할 것이다.
+) Trilinear interpolation equation: https://en.wikipedia.org/wiki/Trilinear_interpolation
Instant-NGP


Hash encoding으로 만들어진 값으로 64 hidden dimension을 가지는 2개의 MLP+ReLU에 넣어서 학습 시킨다.
그리고 output layer로 최종적인 RGB와 density를 추출한다.
Adam optimizer를 이용하였고, embedding을 training할 때 eplison=10^(-15)를 추가하였는데, 이는 convergence가 가속되는 효과가 있었다.
그리고 MLP에는 L2 정규화를 이용하였다. (weight_decay 이용)
Result
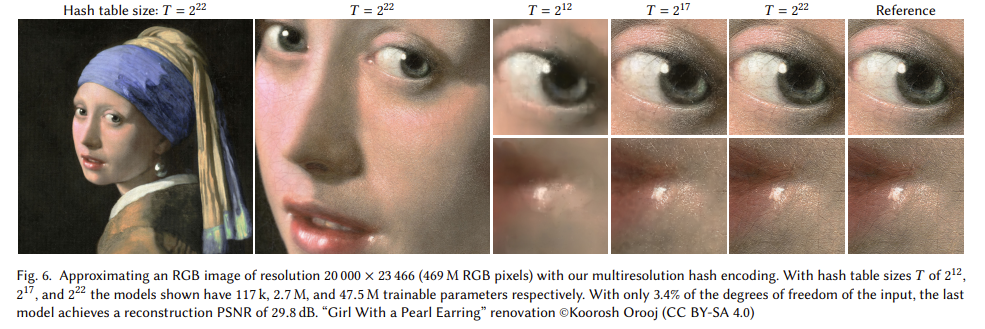
- T가 222일 때 성능이 좋다는 것을 확인할 수 있다.

- 또한 F=2일 때 빠르게 높은 성능에 도달하는 것도 확인할 수 있다.
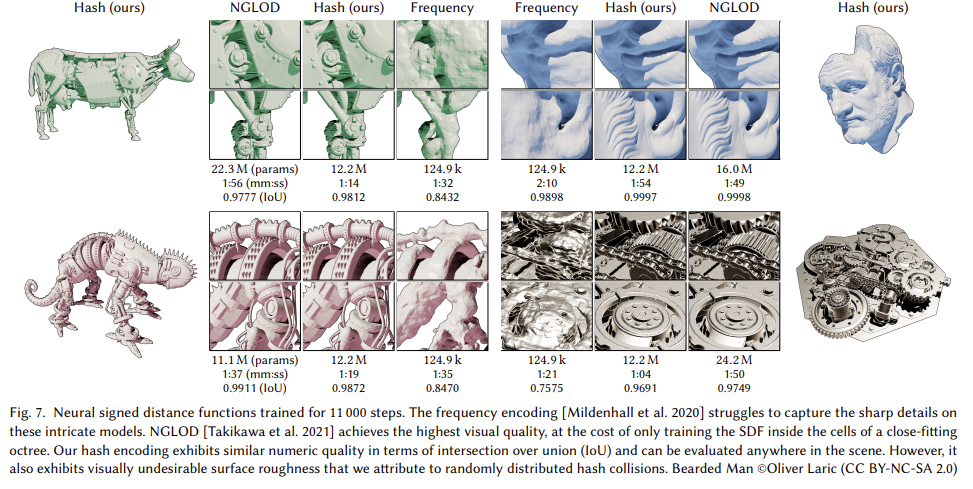

- PSNR 및 density에 대해서 매우 좋은 성능을 보이고 있다.
Furthermore
Instant-stylized-NeRF: https://kyujinpy.tistory.com/84
[Instant-stylization-NeRF 논문 리뷰] - Instant Neural Radiance Fields Stylization
*Instant Neural Radiance Fields Stylization를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! Instant Neural Radiance Fields Stylization paper: [2303.16884] Instant Neural Radiance Fields Stylization (arxiv.org) Instant N
kyujinpy.tistory.com
해당 논문에서 이용된 hash-encoding을 바탕으로 stylization을 빠르게 ray에 적용하는 모델이 궁금하다면 위의 논문을 참고하길 바란다!
- 2023.07.02 Kyujinpy 작성.
(논문을 많이 읽다보니 어느정도 논문들은 1시간 정도면 거의 다 이해할 수 있는 것 같다..ㅎㅎ)
(내가 이해한게 맞겠지..?😆)
*궁금한 점이나 오류가 있다면 언제든지 댓글로 남겨주세요!
'AI > Paper - Theory' 카테고리의 다른 글
| [DDIM 논문 리뷰] - DENOISING DIFFUSION IMPLICIT MODELS (14) | 2023.08.15 |
|---|---|
| [DDPM 논문 리뷰] - Denoising Diffusion Probabilistic Models (9) | 2023.08.04 |
| [Instant-stylization-NeRF 논문 리뷰] - Instant Neural Radiance Fields Stylization (0) | 2023.07.01 |
| [LoRA 논문 리뷰] - LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (3) | 2023.07.01 |
| [ChatGPT 리뷰] - GPT와 Reinforcement Learning Human Feedback (0) | 2023.05.18 |



