*DAE-Former를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
DAE-Former paper: [2212.13504] DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation (arxiv.org)
DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
Transformers have recently gained attention in the computer vision domain due to their ability to model long-range dependencies. However, the self-attention mechanism, which is the core part of the Transformer model, usually suffers from quadratic computat
arxiv.org
DAE-Former github: GitHub - mindflow-institue/DAEFormer: DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
GitHub - mindflow-institue/DAEFormer: DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation - GitHub - mindflow-institue/DAEFormer: DAE-Former: Dual Attention-guided Efficient Transformer for Medical Im...
github.com
Contents
2. Background Knowledge: Vision Transformer
- Skip Connection Cross Attention(SCCA)
Simple Introduction

Medical vision 분야에서 transformer와 U-net을 활용하여 segmentation을 진행하는 연구는 지속적으로 이루어지고 발전하고 있다.
DAE-Former는 Transformer 기반이지만, 좀 더 효율적인 방식으로 모델의 구조를 구성하여 상대적으로 적은 memory로 높은 성능을 이끌어내는 모델이다.
게다가 성능도 SOTA를 이끌어 낼 정도로 매우 좋은 성능을 보이는데, 모델의 구조가 어떠한지 같이 살펴보자!
Background Knowledge: Vision Transformer
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale W
kyujinpy.tistory.com
Transformer 기반으로 이미지를 다루는 구조를 활용하기 때문에 해당 개념을 모른다면, 이 모델의 구조를 거의 이해할 수 없을 것이다..!
U-Net의 구조도 필수이니, transformer와 U-Net을 공부하고 이 글을 읽는 것을 추천한다!
Method

DAE-Former의 Overview이다.
DAE-Former는 Encoder, Decoder로 구성되어 있다.
Encoder와 Decoder 둘 다 Dual Transformer block으로 구성되어 있고,
Encoder에서 Decoder로 Skip-connection이 진행될 때, SCCA라는 논문의 저자들이 제시한 skip connection 방법으로 연결시켜주고 있다.
과연 이것들이 전부 무엇인지 차근차근 알아보자!

+) Encoder는 3 stacked으로 구성된다.
+) Patch Merging: Patch를 합치는 과정으로, 2x2 patch로 merge를 하기 때문에, channel이 doubling되는 것이다! (아래의 그림을 보면 확실히 이해가 될 것이다.

Efficient Attention

위의 사진이 바로 우리가 알고 있는 Dot-product Attention의 구조이다. Query, key, value와 softmax를 적용한 형태는 우리에게 너무나 익숙하다.

Effieicient Attention 구조는 위의 수식으로 표현이 되고, 설명은 아래와 같이 할 수 있다.
1. pq, pk는 query와 key를 각각 normalization하는 functions이다.
2. 첫번째로, pq(Q)를 적용하여 query를 normalization한다. (여기서 normalization은 embedding vector의 크기(d)가 기준이다.)
3. 두번째로, pq(K)를 적용한 후, value V와 서로 곱해준다.
4. 그리고 pq(Q)와 3번의 결과를 서로 곱해줘서 최종적인 effieicient attention vector를 얻는다.

+) Efficient Attention의 구조는 dot-product attention(softmax normalization)과 동등한 output을 낸다고 논문에서 소개하고 있다. (output 값이 같다는 의미보다는, global context vector를 new representation vector로 표현한다는 의미.)

+) Effieicient Attention은 초반에 similarity를 구하는 과정이 생략되었다.
+) Effieicient Attention의 방법론은, dot-product보다 computational complexity를 낮춰줄뿐 아니라 high representational power를 제공한다.
Transpose Attention

Transpose Attention은 Key, Query간의 교차 공분산(Cross-covariance)를 기반으로 하는 attention이라고 생각하면 편할 수도 있다.
기존의 제시된 Transpose Attention은 large input을 processing하기 위한 목적으로만 이용되었는데, 논문의 저자들은 여기서 더 발전시켜서, 전체적인 vector를 효율적으로 captuer(포착, 획득하다, 찝어내다(?))할 수 있도록 만들었다.
Transpose Attention은 위의 수식처럼 표현되고, 아래와 같이 설명된다.
1. Key를 Transpose한 후, Query와 서로 곱한다. (Cross-Covariance; 서로 다른 랜덤변수이니까 교차 공분산이라고 표현.)
2. temperature parameter τ 를 KTQ에 나눠준다. τ으로 나눠줌으로써, l2-normalization이 적용되고 이는 training process에서 stability를 가져다 준다. (그러나 vector의 representational power는 감소한다.)
3. 마지막으로 value V와 서로 곱한다.

+) 논문에서 Transpose Attention과 complexity에 대한 효율성 설명하는 내용이다.
Efficient Dual Attention
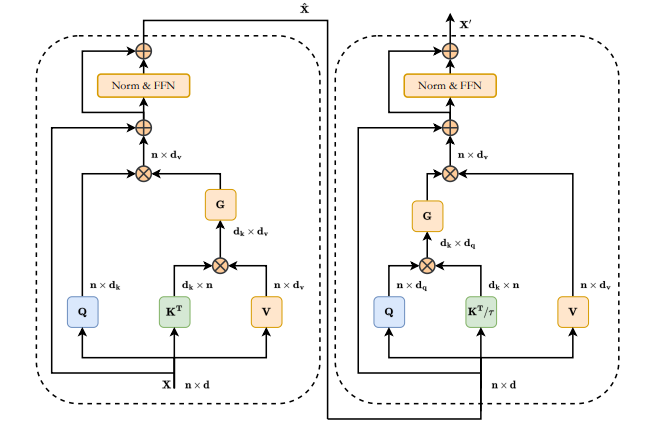
Efficient Dual Attention의 구조를 표현한 그림이다.
Efficient Dual Attention은 위에서 소개한 effieicent attention과 transpose attention을 전부 합친 것이다.
구조가 복잡해 보이지만 전혀 어렵지 않다!
1. Input X를 기준으로, Query, Key, Value를 이용하여 Effiecient Attention(E(X))를 계산한다.
2. Residual function을 이용하여 E(X) + X를 수행하여 Eblock를 만든다.
3. Eblock을 MLP(Norm+FFN)에 적용하여 MLPblock1을 만든다.
4. 그리고 다시 residual function으로 MLPblock1 + Eblock을 수행한다.
5. MLPblock1 + Eblock의 값을 가지고 Transpose Attention(T(X))을 계산한다.
6. Residual function을 통해 T(X) + MLPblock1을 수행하여 Tblock을 만든다.
7. Tblock을 MLP(Norm+FFN)에 적용하여 MLPblock2를 만든다.
8. 마지막으로 MLPblock2 + Tblock을 수행하여 DualAttention vector를 계산한다.

+) Effieicient Dual Attention을 표현한 수식이다.

+) MLP의 구조로, depth-wise convolution과 GELU, FC-layer를 활용하였다.
+) Depth-wise convolution은 각 채널마다 filter를 적용하여 convolution 연산을 하는 것을 의미한다.
Skip Connection Cross Attention(SCCA)

SCCA는 기존의 단순한 concatenating보다 효율적으로 encoder의 공간 정보를 가져오고, representatation power를 높여준다고 한다.
위의 사진이 SCCA의 구조인데, 생각보다 간단하다!
1. X1이 decoder layer 안에 dual attention에서 나온 output, X2가 encoder layer안에 dual attention에서 나온 output이라고 하자.
2. X1의 embedding scale를 X2와 맞춰주기 위해서 FC-layer를 적용하여 X'1를 만든다.
3. Key, Value는 X'1으로 부터 linear project을 통해 만들고, Query는 X2로 부터 linear projection하여 만든다.
4. pv, pk(normalization function)을 이용하여 efficient function와 동일한 mechanism으로 pv(V)pk(KT)Q를 계산하여 값을 얻는다.

+) Skip Connection Cross Attention의 수식이다.
Result

- 단일 RTX 3090 GPU와, batch size 24, SGD(lr=0.05), weight decay=0.0001, 400 epoch, cross-entropy+Dice losses를 이용하였다.

- Synapse(CT data)에 대해서 전체적인 performance 성능이 좋다.
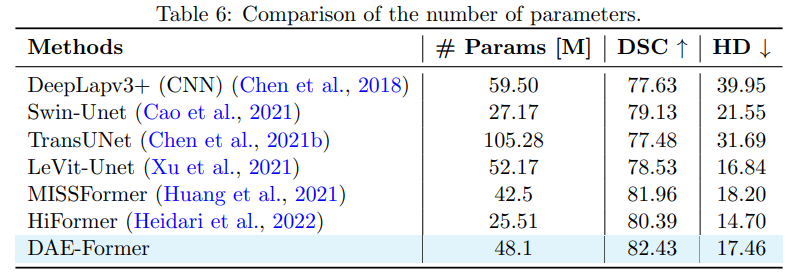
- 파라미터 개수가 상대적으로 적지만, dice와 hd의 성능이 높은 것을 확인할 수 있다!
- 2023.05.06 Kyujinpy 작성.



