*MCCNet를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
MCCNet paper: [2009.08003] Arbitrary Video Style Transfer via Multi-Channel Correlation (arxiv.org)
Arbitrary Video Style Transfer via Multi-Channel Correlation
Video style transfer is getting more attention in AI community for its numerous applications such as augmented reality and animation productions. Compared with traditional image style transfer, performing this task on video presents new challenges: how to
arxiv.org
MCCNet github: GitHub - diyiiyiii/MCCNet
GitHub - diyiiyiii/MCCNet
Contribute to diyiiyiii/MCCNet development by creating an account on GitHub.
github.com
Contents
2. Background Knowledge: AdaIN
Simple Introduction

최근 졸업 프로젝트 주제로, NeRF와 Stylization을 결합한 모델을 만들고자 노력중에 있는데 논문에 거의 항상 등장하는 MCCNet이다. (ReReVST 모델도 있다..!)
Image style transfer, video style transfer에서 자주 비교 대상으로 이용되어서, 이 모델에 대해서 알아야겠다고 생각이 들었다.
이 모델은 NeRF처럼 어려운 개념이 들어가진 않고, CNN과 FC layer 개념이 거의 다이기 때문에 쉽게 stylization 분야에 입문할 수 있을 것이라고 생각이 든다.
Background Knowledge: AdaIN
AdaIN 논문 리뷰: https://kyujinpy.tistory.com/65
[AdaIN 논문 리뷰] - Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
*AdaIN을 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요! AdaIN paper: [1703.06868] Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (arxiv.org) Arbitrary Style Transfer in Real-time with Adaptive
kyujinpy.tistory.com
AdaIN이 무엇인지 몰라도 되지만, 사실 Image style transfer에서 AdaIN은 정말 많이 언급되고 해당 논문에서 쓴 loss function은 계속해서 사용되기 때문에 알아두면 좋다!
Method
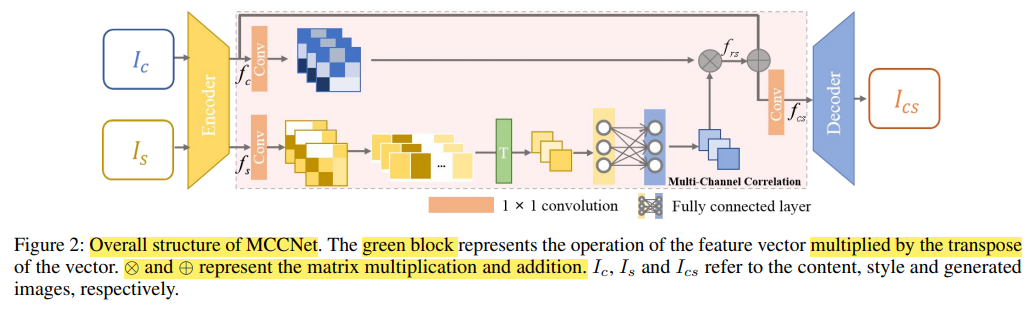
구조가 생각보다 어려울 수 있는데 논문을 읽으면 쉽다(?)
0. Ic는 content image이고, Is는 style image이고, Encoder와 Decoder는 VGG19의 구조이다. (Decoder는 Encoder의 mirror version)
1. Content image와 style image를 encoder에 넣고 channel feature map을 얻는다.
- 여기서 Convolution은 1x1이다. (fs라고 하겠다.)
2. fs를 flatten하여 CxHxW -> Cx1xN으로 dimension을 바꾼다.
- N = HxW

3. 그런 다음에, 각각의 channel matrix를 transpose multiplication 연산을 한다.
- fsfsT 이다.
4. 그리고 FC layer에 넣은 후 Multi-Channel Correlation map을 얻는다.
5. Content image에서 convolution 1x1을 적용한 형태와 fsfsT를 곱하여서 frs를 얻는다.
6. frs와 fc를 더한 후, Convolution 1x1 적용하여 fcs를 얻는다.
7. 마지막으로 Decoder에 적용하여 Ics를 얻는다.

+) 논문으로 보면 더 자세히 이해가 갈 것이다!
Loss function


+) Content Perceptual loss인데, AdaIN과 다르게 conv4_1 layer를 이용했다.
+) Style Perceptual loss도 conv1_1 ~ conv4_1 layer를 이용했다.

+) Icc와 Ic, Iss와 Is간의 identity를 계산하는 것이다. Icc와 Iss의 설명은 위의 사진에 있다.

+) Style 결과가 flicking된다는 것을 보완하기 위해, 결과물에 gaussian noise를 추가하여 계산하는 방식이다.
Result

- 정말 다양한 style transfer 논문들이 있다..
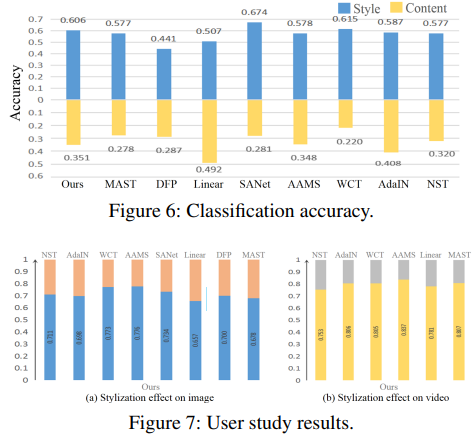
- User study는 stylization 분야에서는 거의 필수이다!

- Ablation study인데, illumination loss가 없을 때 보다 있을 때 더 style이 자연스러운 것을 볼 수 있다.
- 2023.02.26 Kyujinpy 작성.



