*DietNeRF를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
DietNeRF paper: [2104.00677] Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis (arxiv.org)
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis
We present DietNeRF, a 3D neural scene representation estimated from a few images. Neural Radiance Fields (NeRF) learn a continuous volumetric representation of a scene through multi-view consistency, and can be rendered from novel viewpoints by ray castin
arxiv.org
DietNeRF github: GitHub - codestella/putting-nerf-on-a-diet: Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementation
GitHub - codestella/putting-nerf-on-a-diet: Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementati
Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis Implementation - GitHub - codestella/putting-nerf-on-a-diet: Putting NeRF on a Diet: Semantically Consistent Few-Shot View Sy...
github.com
Contents
2. Background Knowledge: NeRF, CLIP
Simple Introduction

기존의 NeRF는 3D rendering 분야에서 획기적인 발명이였다.
2D 이미지에서 Camera parameters를 통해서 3D rgb값과 density값을 MLP만을 이용해서 뽑아낸다는 것은 아직도 너무 신기하다.
그러나 NeRF는 적은 이미지 수에 대해서 학습을 하였을 때, 성능이 급격히 낮아지는 경향이 있다.
위의 예시를 보면 NeRF에서 8 views의 이미지만을 이용하여 학습하였을 때, 거의 형태를 알아볼 수 없게 나오는 것을 확인할 수 있다.
이런 문제를 해결한 것이 바로 DietNeRF 이다.
Background Knowledge: NeRF, CLIP
NeRF 논문 리뷰: https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
CLIP 논문 리뷰: https://kyujinpy.tistory.com/47
[CLIP 논문 리뷰] - Learning Transferable Visual Models From Natural Language Supervision
*CLIP 논문 리뷰를 위한 글입니다. 질문이 있다면 댓글로 남겨주시길 바랍니다! CLIP paper: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision (arxiv.org) Learning Transferable Visual Models From Natu
kyujinpy.tistory.com
해당 모델은 NeRF에 대한 기본적인 이해가 필요하며, loss function을 이해하는데 CLIP이 필요합니다!
Method

DietNeRF의 overview를 보면 다음과 같다.
1. 임의의 이미지에 대해서 NeRF를 통해 값을 얻고, CLIP-VIT 구조를 이용해서 embedding을 얻어 낸다.
- CLIP-VIT는 Pre-trained 모델이다.
- NeRF는 pixelNeRF를 기반으로 한다.
2. 각 scene의 embedding에게는 서로 일관성(consistency)가 있어야 하므로, consistency loss를 이용한다. (밑에서 언급)
3. 더불어서 기존 NeRF에서 이용하는 MSE loss를 이용한다.
여기서 핵심은, 적은 image 수를 이용하기 때문에 Few-shot learning이라는 점이다!
Consistency Loss

일단 Consistency Loss에 이용되는 CLIP는 VIT구조이다.

또한 Consistency Loss를 위의 equation(5)처럼 표현이 되는데, 여기서 이미지를 CLIP을 통해서 embedding을 만든 후, normalized한 다음에 계산하는 것이다.


Consistency Loss를 MSE loss처럼 모든 iteration마다 적용한 것은 아니다.
1. 일정 스텝 k마다 Consistency Loss를 적용한다.
- 논문에서는 k에 대해서 robust하다고 하지만, 10~16 사이가 좋은 성과를 보였다고 한다.
2. 또한 데이터셋 안에서 image와 pose 정보를 먼저 얻고, pose의 연속적인 분포에서 임의적인 pose를 sampling 한다.
3. Sampling된 pose를 이용해서 sample image를 랜더링하고, 두 개의 이미지를 이용하여 Consistency loss를 계산한다.
- Samplling하는 방법이 aliasing artifacts problem를 피할 수 있도록 한다고 한다.
+) Aliasing artifacts problem은 위의 보는 이미지(영상)처럼 렌즈 밖의 영역이 영상 반대편에 생기는 현상을 얘기한다.
+) 정의: FOV 밖의 영역이 영상반대쪽으로 영상화되는 현상
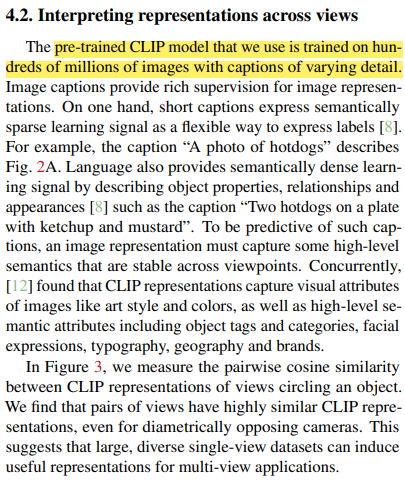

+) 논문의 저자들은 기존의 pre-trained model의 CLIP이 아니라, 직접 training하고 pre-trained model로 이용하였다.
+) 간략히 설명하면, image에 해당하는 caption의 내용을 관계성이 들어나도록 수정하여 학습하였다.
+) 히스토그램을 보면, 확실히 within scene 안에서 simiarlity가 높은 것을 확인 할 수 있다.
Result

- 다른 모델과 비교해보았을 때, 전체적으로 성능이 좋다.

- 확실히 DietNeRF에서 사용되는 consistency loss를 이용함으로써, 적은 view에서 좋은 성능을 보인다는 것을 알 수 있다.
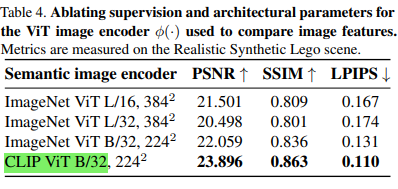
- CLIP-VIT구조가 성능이 좋다!

- 2023.02.26 Kyujinpy 작성.
(학기가 시작되니 블로그를 못 쓰는..ㅠㅠ)



