*MPS-Net를 위한 논문 리뷰 글입니다! 궁금하신 점은 댓글로 남겨주세요!
MPS-Net project page: MPS-Net
MPS-Net
References [6] Hongsuk Choi, Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. Beyond static features for temporally consistent 3D human pose and shape from a video. CVPR, 2021. [8] Carl Doersch and Andrew Zisserman. Sim2real transfer learning for 3D human
mps-net.github.io
GitHub - MPS-Net/MPS-Net_release: Official implementation of CVPR2022 paper "Capturing Humans in Motion: Temporal-Attentive 3D H
Official implementation of CVPR2022 paper "Capturing Humans in Motion: Temporal-Attentive 3D Human Pose and Shape Estimation from Monocular Video" - GitHub - MPS-Net/MPS-Net_release: Offi...
github.com
Contents
2. Background Knowledge: SMPL-X, TCMR
Simple Introduction

Human pose estimation은 참 흥미로운 분야이다.
2D image의 정보에서 2D information인 joints를 추출하고, joints를 가지고 3D mesh형태의 사람 형상을 형성하는 것은 매우 놀랍다고 생각한다.
그리고, 그 안에 숨겨져 있는 복잡한 메커니즘까지 완벽히 이해하면 좋지만, 해당 논문 리뷰에서는 그러한 디테일보다 현재 human estimation이 어디까지 왔고, 어떠한 모델 구조로 mesh를 예측하고 만들어내는지 풀어보도록 하겠다...!
Background Knowledge: SMPL-X, TCMR
GitHub - hongsukchoi/TCMR_RELEASE: Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human
Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021 - GitHub - hongsukchoi/TCMR_RELEASE: Official Pytorch...
github.com
SMPL-X page: SMPL-X (mpg.de)
SMPL-X
smpl-x.is.tue.mpg.de
TCMR은 MPS-Net의 목적과 매우 유사하다고 볼 수 있습니다.
Image가 중심이 아닌, video에서 human pose estimation을 하는데 초점이 맞춰져 있는 논문입니다.
그리고 SMPL-X은 human pose estimation 분야에서 안 쓰이는 곳이 없을 정도로 매우 유명하고, 거의 대부분 논문들은 smpl-x의 가중치나 layer를 많이 이용합니다.
위의 내용을 몰라도, 제가 하는 논문 리뷰를 이해하는데 어려움은 없지만 human pose estimation에 계속 관심이 있다면 SMPL-X는 공부하시는 것을 추천드립니다.
Method
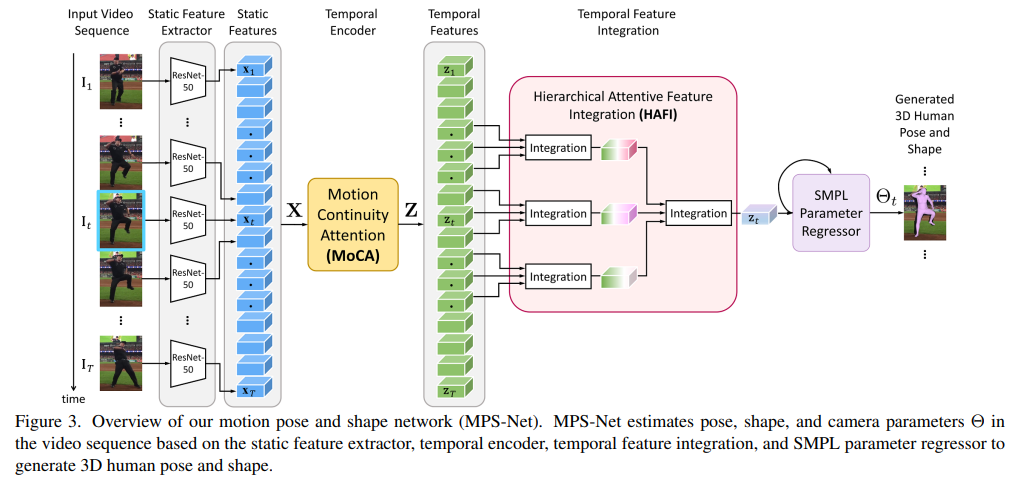
간단한 Overview로 모델의 구조를 살펴보자.
1. 모든 video를 frame단위로 ResNet-50에 넣어서 2048 dimension을 가진 embedding features를 추출한다.
2. MoCA module에 넣어서 2048-dimension의 새로운 temporal features를 추출한다.
3. HAFI에 넣어서 현재 frame에 대한 zt features를 얻는다.
4. SMPL-X의 parameter regressor를 이용해서 최종적인 image의 pose, shape 등등을 estimation 한다.
MoCA
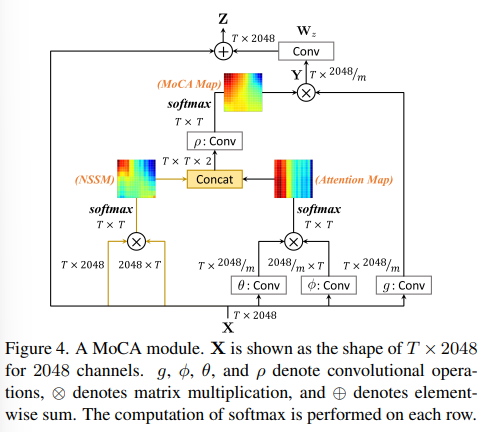
MoCA module의 구조는 위와 같이 표현할 수 있다.
MoCA module로 통해서 기대하고자 하는 바는 다음과 같다.
"NSSM의 특성과 attention map을 같이 고려함으로써 MoCA map은 input video의 human pose와 관련된 비국소적 관계를 적절한 범위에서 표현 가능하다."



+) MoCA module를 표현하는 수식이다.
+) Dimension이나 의미가 더 궁금하다면, 직접 논문을 보시는 것을 추천드립니다!
HAFI
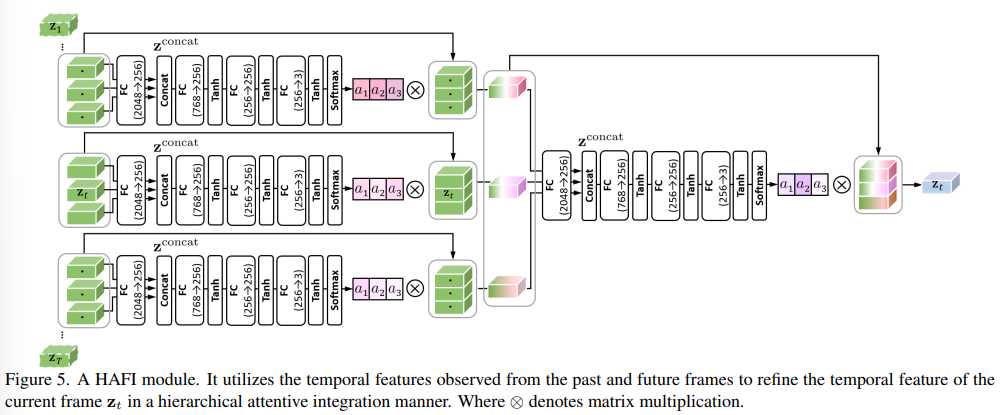
HAFI module은 위와 같이 표현이 가능하다.
전체 frame T중 current frame t에 대해서 위 아래로 T/4 adjacent frames을 고려해서 현재 frame에 대한 pose를 estimation하는 역할을 수행한다.

+) SMPL parameter regressor를 이용해서 zt를 예측한다.
+) Pre-trained weight를 이용해서 human pose에 대한 결과값을 도출한다.

Result
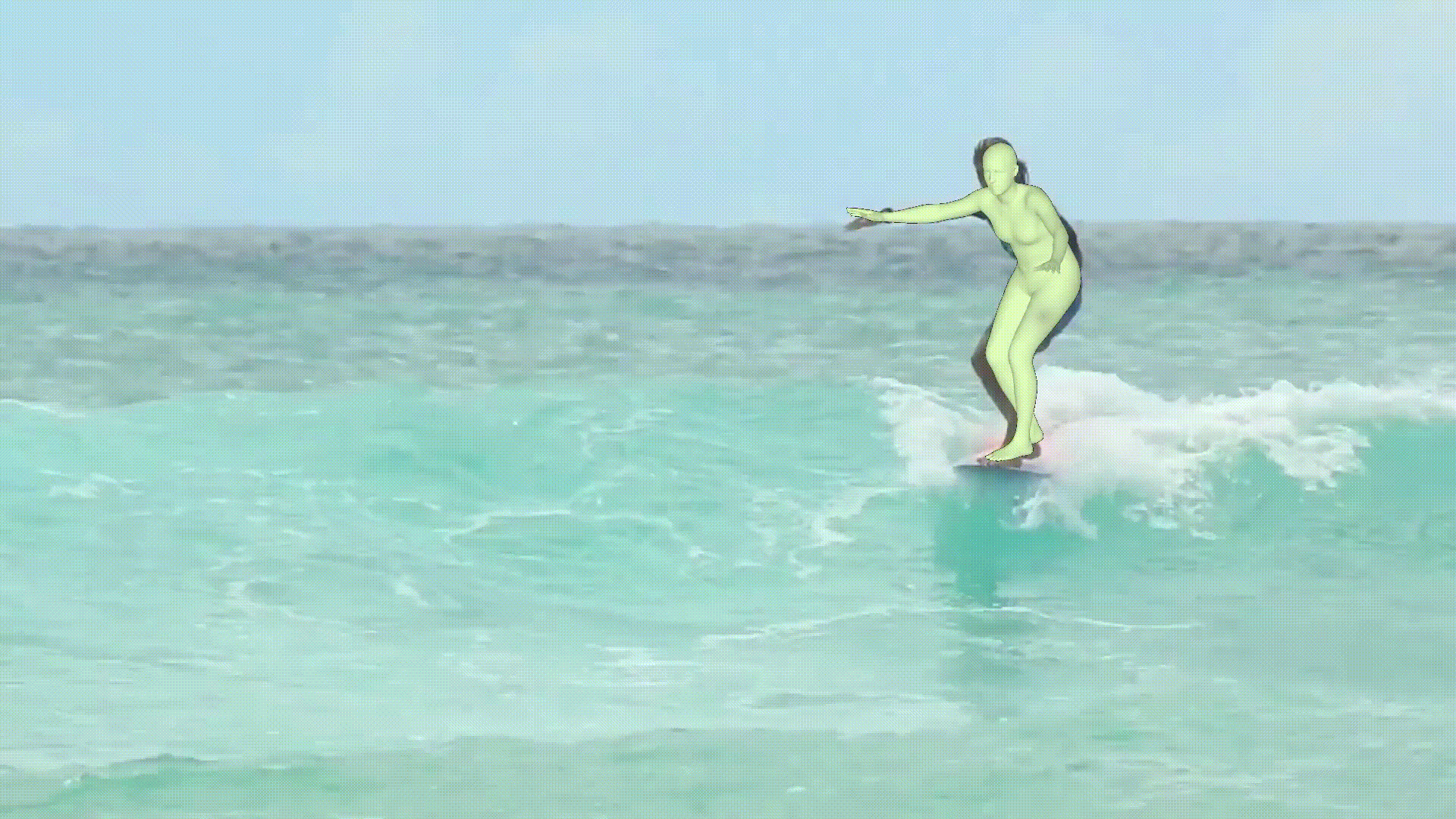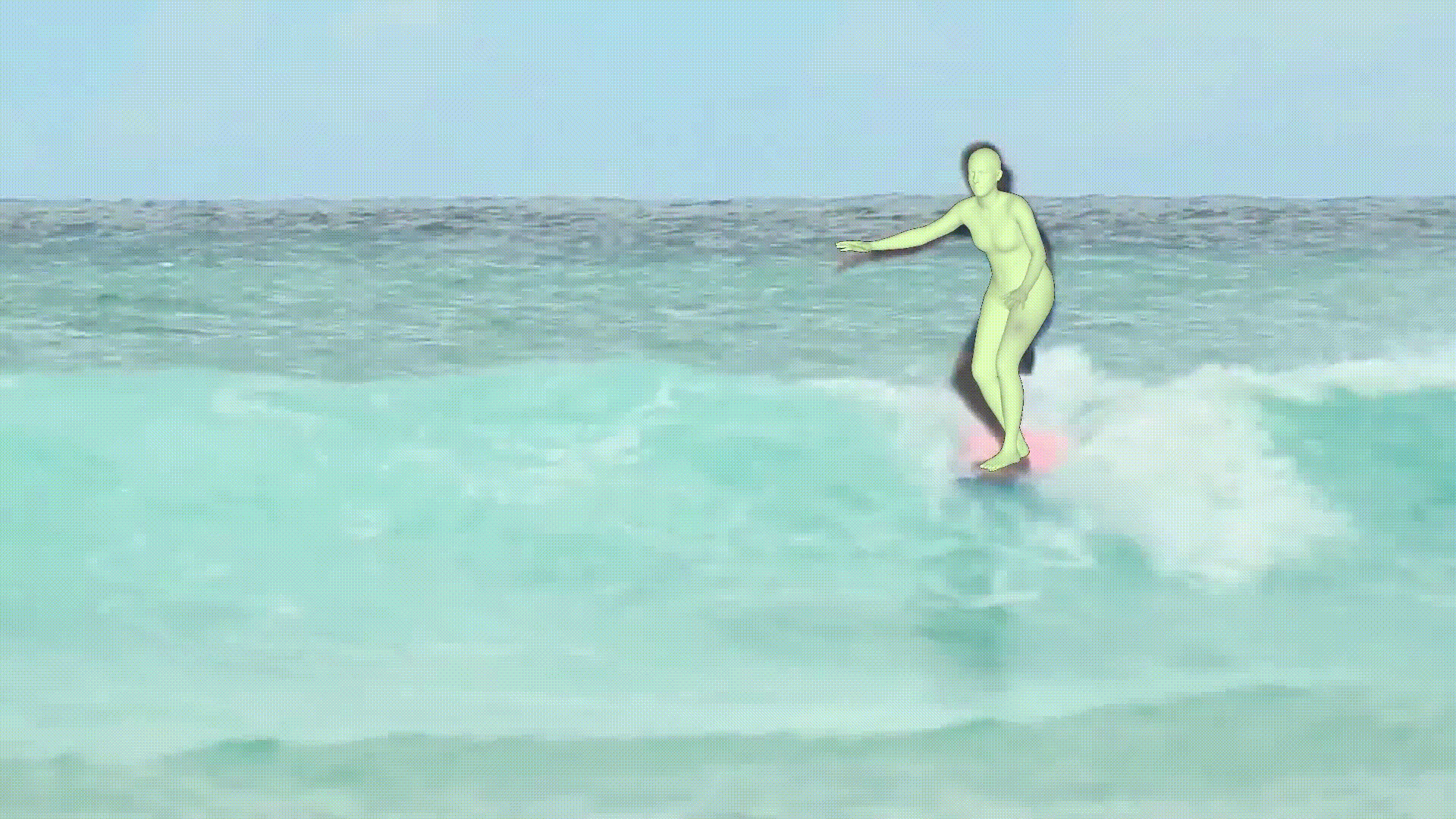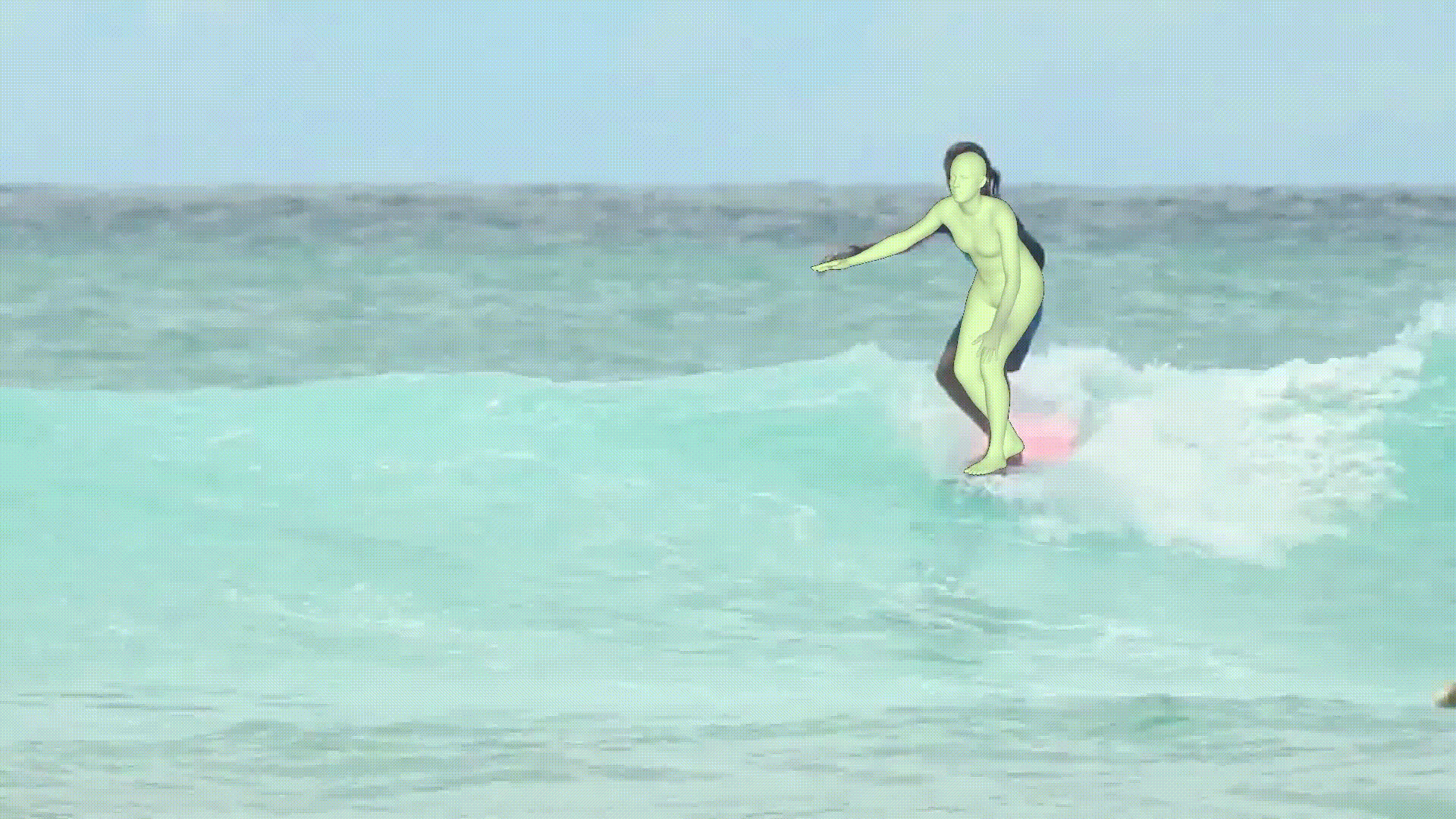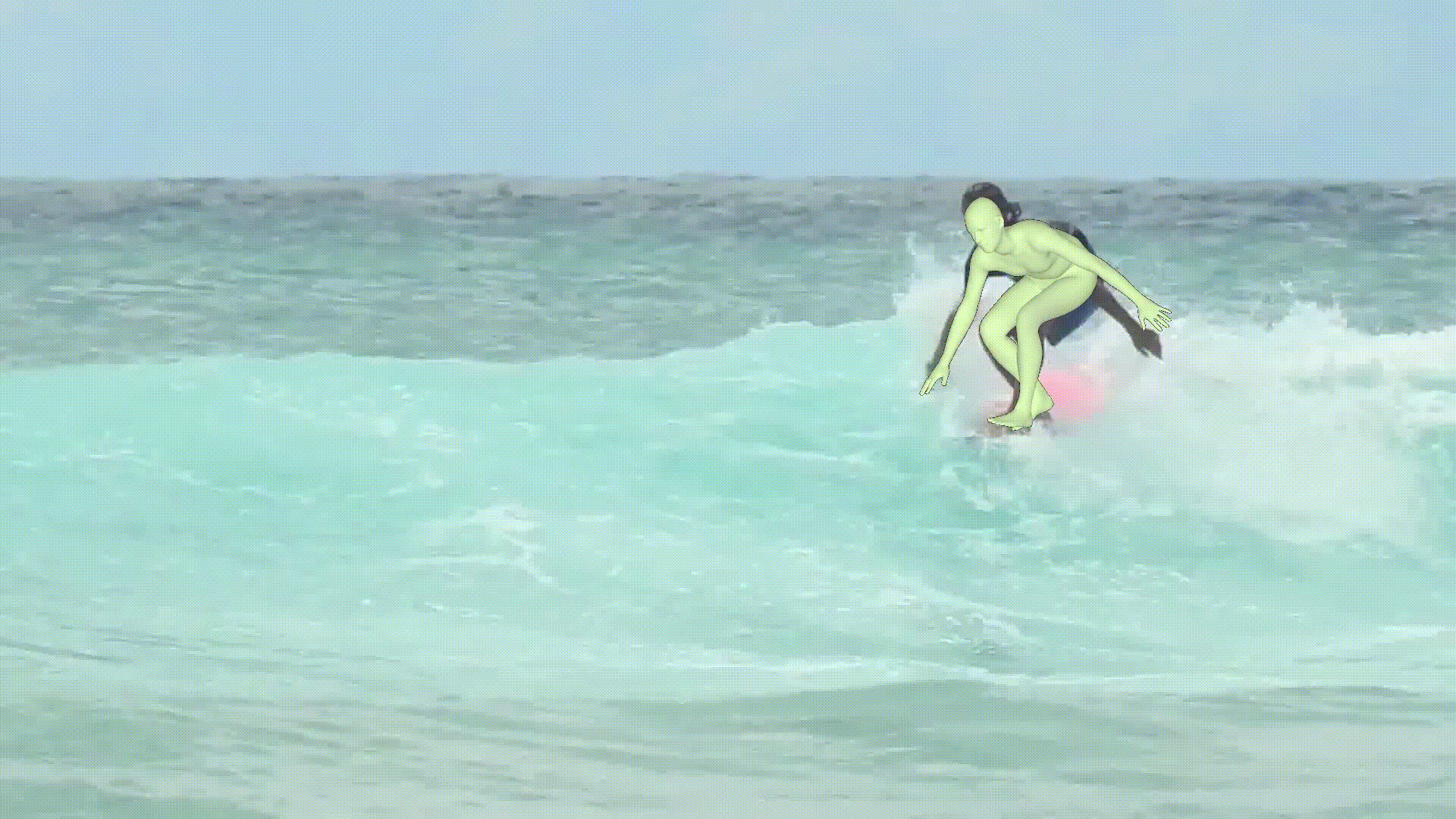
- MPS-Net에서 제공해주는 video로 만들어본 결과이다.
- Human estimation model이 위의 result만 보면 괜찮은 것 같지만, custom dataset에 적용하면 생각보다 오차율이 크다.
- 그래서 아직 실생활에 이용되기에는 약간 무리가 있지 않을까..?
- 2023.02.10 Kyujinpy 작성.



