*Self-Supervised learning을 이용한 Swin UNETR 논문 리뷰 글입니다. 궁금하신 점은 댓글로 남겨주세요!
SSL Swin UNETR paper: [2111.14791] Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis (arxiv.org)
Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis
Vision Transformers (ViT)s have shown great performance in self-supervised learning of global and local representations that can be transferred to downstream applications. Inspired by these results, we introduce a novel self-supervised learning framework w
arxiv.org
SSL Swin UNETR github: research-contributions/SwinUNETR at main · Project-MONAI/research-contributions · GitHub
GitHub - Project-MONAI/research-contributions: Implementations of recent research prototypes/demonstrations using MONAI.
Implementations of recent research prototypes/demonstrations using MONAI. - GitHub - Project-MONAI/research-contributions: Implementations of recent research prototypes/demonstrations using MONAI.
github.com
Contents
2. Background Knowledge: Swin UNETR, SSL(Contrastive learning, proxy task)
- Swin Transformer Encoder pre-training
Simple Introduction
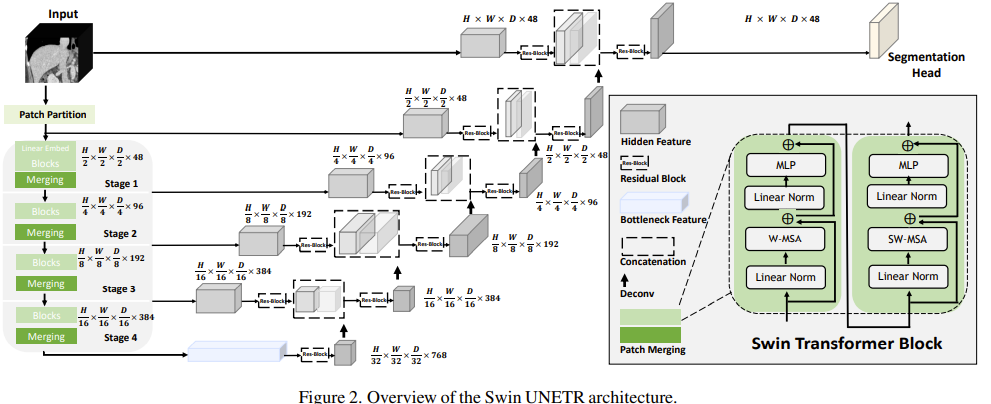
기존의 Swin-UNETR 모델은 단순하게 Encoder와 Decoder만을 이용해서 학습했다.
Swin-UNETR 모델을 더욱 극대화 하기 위해서,
1. 빈 공간의 volume 정보를 학습하고,
2. sub-volume들이 같은 volume에서 나온 것인지 학습하고,
3. volume들의 rotation 각도를 classfication 하도록 학습하여,
Swin-UNETR이 더욱 다양한 정보를 얻을 수 있는 상태에서 segmentation을 수행할 수 있도록 만들어주었다.
어떻게 이러한 과정을 구현했는지 한번 알아보자!
Background Knowledge: Swin UNETR, SSL(Contrastive learning, proxy task)
Swin UNETR 논문 리뷰: https://kyujinpy.tistory.com/52
[Swin UNETR 논문 리뷰] - Swin UNETR: Swin Transformers for SemanticSegmentation of Brain Tumors in MRI Images
*해당 글은 Swin UNETR 논문 리뷰를 위한 글입니다. 궁금하신 점은 댓글로 남겨주세요. Swin UNETR: [2201.01266] Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images (arxiv.org) Swin UNETR: Swin Trans
kyujinpy.tistory.com
SSL 논문 리뷰: https://kyujinpy.tistory.com/39
[SimCLR 논문 리뷰] - A Simple Framework for Contrastive Learning of Visual Representations
*SimCLR 논문 리뷰를 위한 글입니다! SSL 입문하시는 분들께 도움이 되길 원하며 궁금한 점은 댓글로 남겨주세요. *SSL(Self-Supervised-Learning) 중 contrastive learning을 위주로 다룹니다! *해당 글에서는 Proxy
kyujinpy.tistory.com
해당 논문에서는 Swin-UNETR의 구조를 이용하고, 또한 SSL 개념 중 Non-contrastive learning 보다 contrastive-learning과 proxy task를 다루는데, contrastive learning에서는 SimCLR과 loss function이 유사하다.
따라서 위의 개념이 있어야 이해를 쉽게 할 수 있다.
해당 논문 리뷰에서는 위의 논문들을 안다고 가정하고 진행됩니다.
Method


SSL 방법을 설명하기 전에, 이 논문에서 CT image의 segmentation은 기존의 Swin-UNETR과 똑같이 Encoder와 Decoder 구조로 이루어져 있는 Swin-UNETR을 이용해서 segmentation 한다.
여기서 가장 중요한 차이점은,
미리 Swin-UNETR의 Encoder를 pretraining 시킨 후, pretraining 된 것을 가지고 fine-tuning 등등을 하면서 decoder와 같이 학습을 진행한다는 것이다.
Encoder를 pre-training 시킬 때 SSL을 이용하게 되는데 한번 같이 살펴보자!
Swin Transformer Encoder pre-training
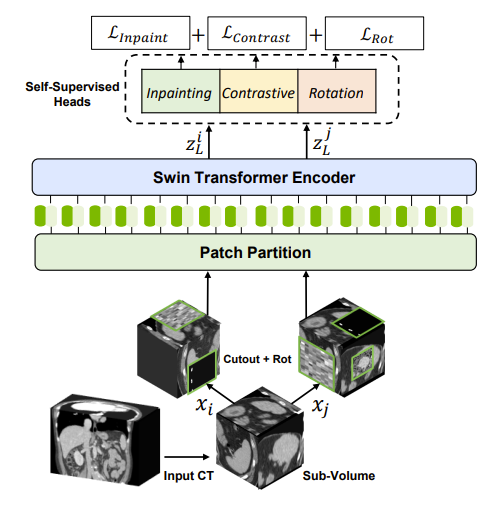
SSL에서 사용되는 학습 방법은 총 3가지이다.
1. Masked Volume Inpainting
2. Image Rotation
3. Contrastive Coding
각각에 대해서 알아보자.
1. Masked Volume Inpainting

데이터를 학습할 때 cutout-augmentation을 진행한다. 즉 volume의 일부분을 잘라낸 augmentation 방법이다.
이 방법을 이용해서, cutout된 CT image의 ROI 부분을 label로 설정하고 학습하는 방법이다.
Swin-UNETR Encoder 부분에 transpose convolution layer를 더해서 output를 만들어 낸 후, output과 cutout 된 부분의 GT를 L1 loss를 이용해서 training한다.
이 학습 방법은 volumetric medical images를 효율적으로 대표화할 수 있도록 도와준다.
2. Image Rotation (Proxy task)

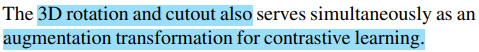
Rotation augmentation을 데이터셋에 적용한 후 학습을 진행할 때,
Swin-UNETR Encoder 마지막 MLP classification head를 붙여서 rotation 각도에 대해서 classification을 진행하여 Softmax로 training 한다.
3D rotation SSL 방법도 위와 마찬가지로 volumetric medical images를 효율적으로 대표화할 수 있도록 도와준다.
3. Contrastive Coding

Contrastive learning은 SSL에서 매우 자주 쓰이는 방법이다.
매우 간단하기도 하고, 대표적인 embedding vector를 만들어낼 수 있기 때문이다.
데이터셋의 volume을 sub-volume으로 augmentation 한 후에 학습을 진행한다.
여기서 같은 volume에서 나온 sub-volume을 positive pairs로 생각한다.
그리고 각각의 sub-volume에 대해서 Swin-UNETR Encoder에서 나온 embedding을 가지고 positive samples과 negative samples에 대한 cosine similarity를 구해서 InfoNCE loss(Contrastive loss)를 이용해서 training 한다.
Contrastive learning은 같은 class를 찾을 수 있도록 도와주고, 클래스 간 분리 기능도 학습할 수 있도록 도와준다.

+) Swin-UNETR Encoder의 loss function은 위의 각각의 loss function을 모두 더한 것이다.
+) Downstream task에 적용할 때는 projection head와 SSL 부분을 모두 이용하지 않는다.
Ablation

SSL에 이용되는 training 종류에 따른 성능 체크이다.
Inpainting, contrastive, rotation 전부 이용했을 때 성능이 가장 좋았다.
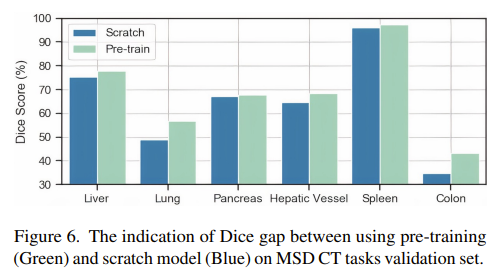
Pre-training 이용했을 때, 각 장기에 대해서 segmentation이 잘 되는 것을 볼 수 있다.

SSL을 학습할 때 이용되는 데이터 수가 많을 수록, 모델의 성능이 증가한다.
Visualization


여러 task에 대해서 높은 segmetation 성능을 보인다!!
- 2023.01.17 Kyujinpy 작성.



