*eXplainable AI의 기초가 되는 논문입니다. 질문이 있다면 댓글로 남겨주세요.
Deep Inside Convolutional Networks paper: [1312.6034] Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (arxiv.org)
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
This paper addresses the visualisation of image classification models, learnt using deep Convolutional Networks (ConvNets). We consider two visualisation techniques, based on computing the gradient of the class score with respect to the input image. The fi
arxiv.org
Contents
- Weakly Supervised Object Localization
Simple Introduction

AI를 만들 때, 우리는 왜 결과물이 좋은지 이해하지 못한다.
무슨 패턴을 보고, 어디를 보고 이러한 output을 도출하는지 모르기 때문에 AI의 성능이 잘 나오거나 잘 나오지 않을 때 원인을 찾지 못한다.
이러한 현상을 Black Box라고 한다.
그렇다면, Black Box를 설명할 수 있는 방법은 없을까?
그것이 바로 XAI(eXplainable AI)이다.
그리고 이번에 소개하는 Saliency Map은 XAI의 basic한 논문이다.
같이 한번 살펴보자.
Method

논문을 파고들기 전에 Saliency Map이 무엇인지 부터 살펴보자.
Saliency Map은 각 좌표의 미분 값을 의미한다. (어떻게 미분하는지는 밑에서 설명)
즉 위의 사진에서 색깔이 밝을 수록, AI가 이 사진을 강아지라고 판단하는데 큰 도움을 줬다는 의미가 된다.
Saliency Map을 보면 강아지의 형태가 보이고, '눈코입'을 주로 보고 강아지라고 판단한다고 얘기할 수 있다.
Class Model Visualization


Class Model Visualization은 이미 사전에 훈련된 ConvNet을 이용해서 진행된다.

Class Model Visualization의 step은 다음과 같다.
1. 처음에 zero-centered image data을 만든다. (쉽게 말해서 noise image)
2. Noise image를 ConvNet에 넣어서 특정한 class c에 대한 값을 얻는다.
- 이것이 바로 Sc(I) 이다.
3. Sc(I)를 loss function으로 설정하고, noise image에 대해서 backpropgation algorithm을 통해서 update한다.
- ConvNet의 weights는 not update.
- Noise image만 update.
- 또한, loss function이 maximize하는 방향으로 image를 update한다. 즉 Gradient ascent이다!
- Image's Gradient Ascent equation: In+1 = In + learning_rate * ∂Sc/∂I
- Image I에 대해서 L2 regularization을 수행한다.
4. 위의 과정을 계속 반복하여서 최종적인 결과를 얻는다.
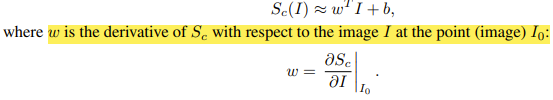
+) 우리가 원하는 결과값은 특정 class에 대해서 pixel들을 gradient(미분)한 것이 된다.
+) 이것이 바로 Saliency Map이다.
Weakly Supervised Object Localization

Weakly Supervised Object Localization은 XAI를 통해서 segmentation을 학습한 적이 없는 모델이 Object를 segmentation 할 수 있다는 뜻이다.
위의 결과를 보면, Saliency Map이 있고 그 옆에 saliency map을 바탕으로 segmentation을 만든 결과값이 있다.
이를 통해서, AI가 객체의 classification을 수행할 때, 객체의 모습을 잘 추정해서 학습한다는 것을 알 수 있다.
Result

Class Model의 시각화 이다.
Noise image를 backpropagation algorithm으로 학습함에 따라, 어떻게 image가 변화하는지 표현한 것인데,
각 객체가 어렴풋이 보인다는 것을 알 수 있다.

+) 좋은 시각화 예제가 있어서 가져왔다.
+) Class각 'flamingo'일 때 어떻게 표현되는 것인지 확인한 것인데, 모습이 어렴풋이 보인다!
+) 그러나 이미지에서 보는 것처럼, noisy하고 low localization이 일어난다는 것이 saliency map의 근본적인 문제이다..
Furthermore
CAM 논문 리뷰: https://kyujinpy.tistory.com/59
[CAM 논문 리뷰] - Learning Deep Features for Discriminative Localization
*XAI에서 가장 대표적으로 쓰이는 CAM 논문 리뷰입니다. 궁금하신 점은 댓글로 남겨주세요. CAM paper: [1512.04150] Learning Deep Features for Discriminative Localization (arxiv.org) Learning Deep Features for Discriminative Loca
kyujinpy.tistory.com
최근 XAI는 대부분 CAM을 기반으로 활용되는 모델들을 많이 이용한다.
더욱 XAI에 대해서 알고 싶다면 CAM을 공부하는 것도 추천한다!
- 2023.01.25 Kyujinpy 작성.



