*Vision Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요!
Vision Transformer paper: https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Contents
Simple Introduction

Transformer의 input은 word vector(embedding) 형태였다.
즉 Sentence가 input이고, 각각의 순서와 위치가 있었다.
이미지는 그러나 단 1개의 input이다.
어떻게 Transformer를 적용할까?
이미지를 여러 조각으로 쪼갠 다음에 그것을 일렬로 나열한다면, 그것은 sentence와 비슷한 형태가 되지 않을까?
그리고 그것을 word matrix를 transformer로 학습하는 것처럼 이미지를 넣어준다면!?
충분히 이미지에 적용히 가능하고, 심지어 SOTA 모델 성능급의 성능을 보였다.
Computer vision 분야에서 CNN의 막이 내려가는 걸 알리는 시점이였다.
과연 이 알고리즘이 정확히 어떻게 작동하는지 살펴보자!
Background Knowledge: Transformer
Transformer 논문 리뷰: https://kyujinpy.tistory.com/2
[Transformer 논문 리뷰] - Attention is All You Need (2017)
Transformer paper: https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also con
kyujinpy.tistory.com
Vision Transformer는 Transformer의 개념을 반드시 알고 있어야 이해가 가능하다!
위의 논문 리뷰나, 다른 곳을 통해서 반드시 공부하고 오자!
*이 논문 리뷰는 Transformer의 개념을 알고 있다고 생각하고 진행됩니다.
Method

Vision Transformer(ViT)는 Image를 patch로 쪼갠다는 개념에서 시작한다.
방법의 순서를 step by step으로 한번 살펴보자.
1. 이미지를 16x16 patch의 크기로 분할한다.
2. 16x16 patch로 잘라진 이미지들을 각각 linear projection을 수행한다. (2D을 1D으로 flatten 시킨다.)
3. Positional encoding을 더해준다.
- 여기에서 [class] token의 embedding을 0번째로 넣어준다!
- 이 [class] token은 learnable 하다. (밑에서 다시 한번 더 언급)
4. Transformer encoder를 통해서 embedding을 생성한다.
5. [class]에 대한 embedding만 이용해서 MLP에 넣어주고 classification을 진행한다.

+) MLP 구조는 두 개의 linear와 GELU를 이용한다.

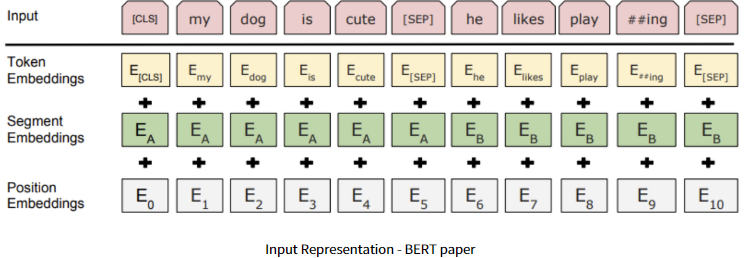
+) BERT 모델을 보면, [class] token이 있다. 이 [class] token은 [sep] token과 주로 NLP task에 자주 쓰이는데, 그 이유는 문장의 첫 시작과 끝 부분을 알려주는 역할을 한다.
+) For example) [cls] I love you. [sep]
+) Vision Transformer에서 쓰인 [class] token도 이와 같은 맥락으로, 실제 NLP 분야에서도 text를 이용한 classification을 할 때 [cls] token만 이용하는데, 여기서도 이와 동일한 역할이다.
Furthermore
Transformer을 이용했다면 Vision Transformer를 이해하는데는 별로 어렵지 않을 것이다.
ViT는 image classificaiton, detection 분야에서는 좋은 성능을 보였지만
세밀하게 영역을 찾아내는 segmentation 분야에서는 좋지 못한 성능을 보였다.
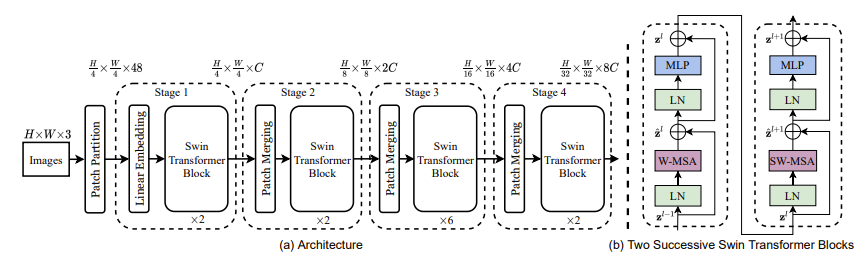
그래서 나온 모델이 Swin-Transformer이다.
Swin-Transformer 모델은 segmentation 뿐만 아니라, 여러 detection 분야와 computer vision 분야에서 여러 SOTA 모델의 베이스 구조를 담당하고 있다.
관심이 있다면 밑에 논문 리뷰 글을 참고하면 좋겠다.
Swin Transformer 논문 리뷰: https://kyujinpy.tistory.com/14
[Swin Transformer 논문 리뷰] - Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
*Swin Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요! Swin Transformer 논문: [2103.14030] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (arxiv.org) Swin Transforme
kyujinpy.tistory.com
- 2022.12.29 kyujinpy 작성.



