*Swin Transformer 논문 리뷰를 위한 글이고, 질문이 있으시다면 언제든지 댓글로 남겨주세요!
Swin Transformer 논문: [2103.14030] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (arxiv.org)
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
Contents
2. Background Knowledge: Transformer, (Vision Transformer)
- Relative positional encoding
Simple Introduction

기존 Vision Transformer의 Window는 고정적이기 때문에 segmentation을 하기 어려웠다.
그러나 Swin Transformer는 window를 세밀하게 쪼개는 것뿐만 아니라, 여러 모양의 window를 이용한다.
또한 window를 단순하게 이용하는 것이 아니라 shift를 적용하고 self attention을 수행한다.
더불어서, Feature pyramid network와 같은 Hierarchical 구조를 구성하면서 segmentaiton, detection 등등의 분야에서 SOTA의 성능을 내기 시작하였다.
Background Knowledge: Transformer, (Vision Transformer)
Transformer 논문 리뷰: https://kyujinpy.tistory.com/2
[Transformer 논문 리뷰] - Attention is All You Need (2017)
Transformer paper: https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also con
kyujinpy.tistory.com
Vision Transformer 논문 리뷰: https://kyujinpy.tistory.com/3
[Vision Transformer 논문 리뷰] - AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(2021)
Vision Transformer paper: https://arxiv.org/abs/2010.11929 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale While the Transformer architecture has become the de-facto standard for natural language processing tasks, its application
kyujinpy.tistory.com
*해당 논문 리뷰는 Transformer, (Vision Transformer)의 개념을 알고 있다고 가정하고 진행됩니다!
두 논문의 개념을 반드시 익히고 오셔야 편히 이해하실 수 있습니다!
Method
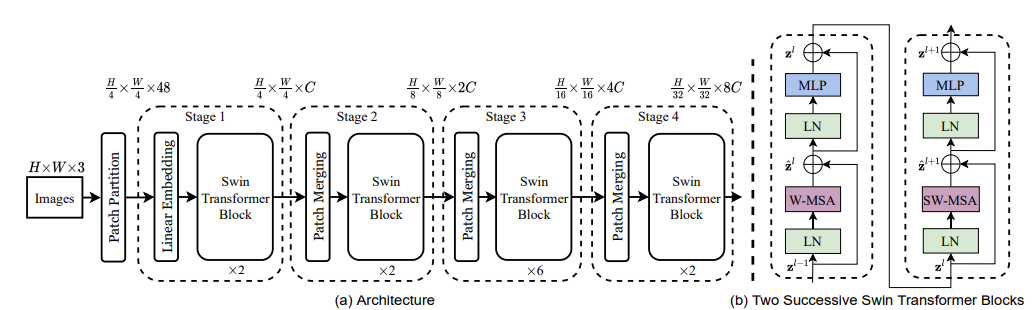
Swin Transformer의 구성이다.
Images를 일단 patch로 만들고 swin transformer block에 넣어주는 형태를 반복한다.
이때 중간에 Patcdh Merging이라는 것이 있는데, patch를 합쳐서 크기를 늘려주는 과정이다.
예를 들어, 이미지 32x32를 patch를 4x4로 쪼개면 조각이 64개가 나오는데, 이것을 16개로 줄이기 위해서는 patch를 8x8 patch로 merging 시켜야 한다.
그리고 Swin Transformer Block를 자세히 보면 W-MSA와 SW-MSA가 있다.
바로 이것이 Swin Transformer의 가장 큰 핵심인데, shift를 MSA에 적용하는 형태라고 볼 수 있다.
한번 천천히 알아보자!
1. MSA vs W-MSA
Swin Transformer에서 말하는 MSA는 Multi-self attention으로 Multi-Head-Attention과 같은 개념이다.
그렇다면 W-MSA는 무엇일까?
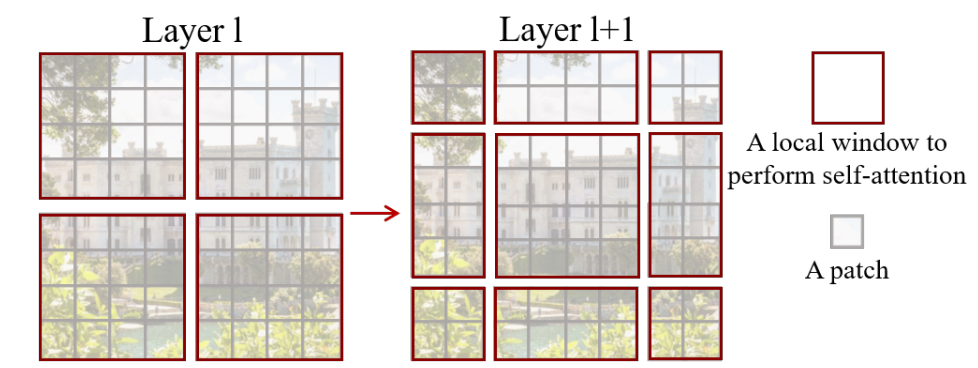
일단 Patch와 Window의 개념을 확실하게 잡고 갈 필요가 있다.
Patch는 image를 구성하는 조각의 개념이고, window는 patch를 묶고 있는 개념이다.
(+window안에 patch size는 4x4이다.)
효율적인 모델링을 만들기 위해서는, self-attention을 window 안에서 수행해주면 된다.
따라서, window는 non-overlapping한 방법으로 균등하게 분할되도록 배열할 수 있다.
이미지는 근처 pixel끼리의 연관성이 매우 높기 때문에, 근처 patches만 이용해서 self-attention을 수행하여 연산량도 줄이고 세밀한 부분에서의 픽셀간의 연관성을 파악하기 위한 목적이 있다.
이것이 바로 W-MSA의 개념이다.

+) 논문의 저자들이 식으로 나타낸 연산량인데, MSA에서 h와 w(이미지의 height와 width)가 클수록 연산량이 급격히 증가한다는 것을 확인할 수 있다.
2. SW-MSA

SW-MSA는 MSA를 적용하기 전에 shift를 시키는 과정이다.
위의 사진에 보면 window가 나눠져 있는데 각자 다른 개수와 dimension을 가지고 있다. 이것을 모두 고려해서 연산을 하게 되면 모델이 매우 복잡해질 것이다.
따라서 cyclic shift를 이용해서 왼쪽에 있는 window를 오른쪽 아래로 이동시킨다.
또한 Masked MSA를 적용하는데, 사진에 있는 A, B, C 구역에 mask를 적용해서 self-attention이 적용되지 못하도록 한다. 그 이유는 A,B,C는 왼쪽에 있는 pixel의 값들이기 때문에 오른쪽에 위치한 pixel과의 연관성이 거의 없다고 볼 수 있다.
Mask MSA 연산이 다 끝난 후, window를 원상복귀 시킨다.
이 SW-MSA를 통해서 window간의 연결성과 위치를 파악할 수 있기 때문에 model이 이미지를 학습할 때 도움이 된다.
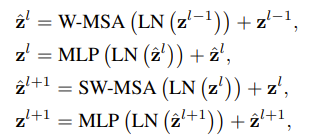

+) 위의 사진은 Swin-Transformer block의 연산 과정이다.
+) MLP는 2개의 linear와 GELU를 적용한다.
3. Relative Position Bias
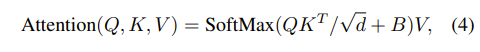
Swin Transformer에서 한가지 더 알아야 하는 점은, 바로 Positional encoding을 처음에 적용하지 않는다는 점이다..!
그러면 어떻게 이미지들의 위치를 파악할까??
바로 Relative Position Bias(B)를 이용해서 attention 연산 과정 중에 더해주는 형태를 취한다.
기존의 Transformer, Vision Transformer와의 차이점이 무엇이냐!
기존의 positional encoding은 absoulute coordinate에 대한 기준이였다면, Relative Position Bias는 relative coordinate에 대한 기준으로 weights을 준다.


+) 실험을 통해서, relative position bias가 다른 방법론에 비해서 좋다는 것을 증명하였다.
+) 여러 Swin Transformation model이 있다. 한번 정보들을 보면서 위에 내용을 상기해보자.
Furthermore
Transformer, Vision Transformer, Swin Transformer 까지 공부하였다면,
앞으로 computer vision 분야에서 Transformer을 적용한 대부분 모델에 대한 이해는 거의 다 할 수 있을 것이다!!
위의 3가지 모델은 반드시 아는 걸 추천하고,
만약 다음 어떤 걸 공부할지 고민된다면 U-Net + Transformer의 구조를 가진 모델을 살펴보길 추천한다!
이 분야는 medical segmentation에서 자주 이용된다.
Medical과 AI를 연관시켜 가고 싶은 사람들은 반드시 알아야 한다!
논문을 자주 찾아보면서 논문 보는 눈을 같이 키워봅시다 ㅎㅎ
- 2022.12.29 kyujin py 작성



