에러코드 전체
'''
RuntimeError: one of the variables needed for gradient computation has been modified by
an inplace operation: [torch.cuda.FloatTensor [1024, 1024]],
which is output 0 of AsStridedBackward0, is at version 2; expected version 1 instead.
Hint: enable anomaly detection to find the operation that failed to compute its gradient,
with torch.autograd.set_detect_anomaly(True)
'''구현하고자 했던 github: https://github.com/ztex08010518/Stylizing-3D-Scene
GitHub - ztex08010518/Stylizing-3D-Scene
Contribute to ztex08010518/Stylizing-3D-Scene development by creating an account on GitHub.
github.com
에러코드가 떴던 github(style-vae; RAIN): https://github.com/RoyalVane/ASM
GitHub - RoyalVane/ASM: ( NeurIPS 2020 ) Adversarial Style Mining for One-Shot Unsupervised Domain Adaptation
( NeurIPS 2020 ) Adversarial Style Mining for One-Shot Unsupervised Domain Adaptation - GitHub - RoyalVane/ASM: ( NeurIPS 2020 ) Adversarial Style Mining for One-Shot Unsupervised Domain Adaptation
github.com
loss.backward()에서 오류 발생
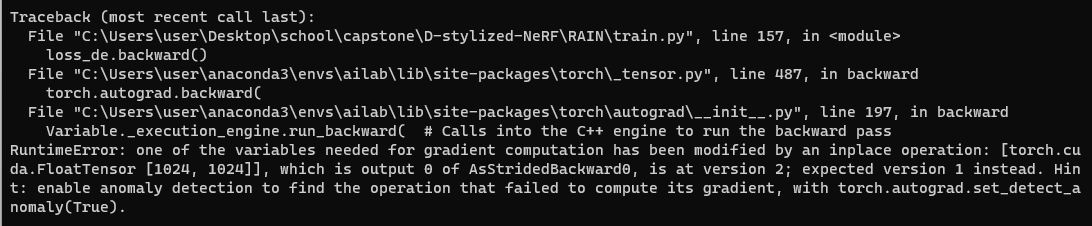
위의 ASM 모델에서 style-vae를 학습하고자 RAIN 모델을 training할려고 하는데
해당 에러를 마주쳤다..!!
처음에는 너무나 난해하고, 에러코드도 복잡하고, 어디서 문제인지 해결방법을 도저히 몰랐다.
하지만 수많은 시행착오와 검색을 통해, 방법을 찾았고, 여러 방법을 공유하고자 한다..!
Method1: inplace operation(+=, *= 등등) 제거하기
Method1은 보통 loss function을 계산할 때 적용해야하는 방법이다.
(만약 자신은 backward() 부분에서 에러가 일어났다면, method2부터 참고하세요..!)
# In RAIN folder
# in net.py
(코드 중략)
def forward(self, content, style, alpha=1.0):
(코드 중략)
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].detach())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.detach())
# Inplace Operation 예시!
for i in range(1, 4):
loss_s += self.calc_style_loss(g_t_feats[i], style_feats[i])
return loss_c, loss_s, loss_l, loss_r여기서 마지막 부분을 보면 '+=' operation이 있는 것을 확인할 수 있다.
따라서 해당 부분을 밑에와 같이 수정하여야 한다.
# In RAIN folder
# in net.py
(코드 중략)
def forward(self, content, style, alpha=1.0):
(코드 중략)
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].detach())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.detach())
# Solution: inplace operation 제거해서 표현하기
for i in range(1, 4):
loss_s = self.calc_style_loss(g_t_feats[i], style_feats[i]) + loss_s
return loss_c, loss_s, loss_l, loss_r즉 +=, *=, /= 등등과 같은 수식(inplace operation)을 없애고, 일반적인 형태(?)로 코드를 수정하자.
Method2: detach() 이용하기
Backward를 할 때, gradient가 적용되면 안되는 tensor가 존재하는데, 그 tensor의 gradient option이 True여서 오류가 일어나는 것이다.
# In RAIN folder
# net.py
(코드 중략)
def forward(self, content, style, alpha=1.0):
(코드 중략)
t = adainwn(content_feat, style_feat_mean_std_recons)
#t = adain(content_feat, style_feats[-1])
t = alpha * t + (1 - alpha) * content_feat
# line 15 -> Problem! (below line)
g_t = self.decoder(t)
g_t_feats = self.encode_with_intermediate(g_t)
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].detach())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.detach())
for i in range(1, 4):
loss_s = self.calc_style_loss(g_t_feats[i], style_feats[i]) + loss_s
return loss_c, loss_s, loss_l, loss_r위의 코드에서 self.decoder(t) 부분에서 현재 오류가 발생했다고 가정해보자.
즉, decoder를 backpropagation할 때, t가 backward되지 않는다는 케이스이다.
따라서 해당 부분을 밑에 코드처럼 변경해야 한다.
# In RAIN folder
# net.py
(코드 중략)
def forward(self, content, style, alpha=1.0):
(코드 중략)
t = adainwn(content_feat, style_feat_mean_std_recons)
#t = adain(content_feat, style_feats[-1])
t = alpha * t + (1 - alpha) * content_feat
# line 15 -> Problem! (below line)
g_t = self.decoder(t.detach()) # Solution: detach() 이용하기
g_t_feats = self.encode_with_intermediate(g_t)
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].detach())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.detach())
for i in range(1, 4):
loss_s = self.calc_style_loss(g_t_feats[i], style_feats[i]) + loss_s
return loss_c, loss_s, loss_l, loss_r위와 같이 해당 부분을 self.decoder(t.detach())로 표현해주면, 문제 없이 코드가 돌아간다!
Method3: clone() 이용하기
Method2가 잘 안된다면, 제가 추천하는 마지막 방법이다(?)
clone은 말 그대로 tensor를 새롭게 할당하지만, 특성을 그대로 가져가는 것을 말한다.
clone이 backpropgation 문제를 어떻게 해결해주는지는 정확히 파악하지 못했지만, 검색했을 때 나와서 소개해본다.
# Original Code
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].detach())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.detach())
# New Code
loss_c = self.calc_content_loss(g_t_feats[-1], t.detach())
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0].clone())
loss_l = self.calc_latent_loss(intermediate_mean, intermediate_std)
loss_r = self.mse_loss(style_feat_mean_std_recons, style_feat_mean_std.clone())위의 코드처럼, input tensor에 clone을 붙이는 방법이다.
loss function에 들어갈 때 사용해도 되고, model에 value를 넣기 전에, value.clone()으로 넣는 방법이 있을 것 같다.
(해결된 코드 자료)
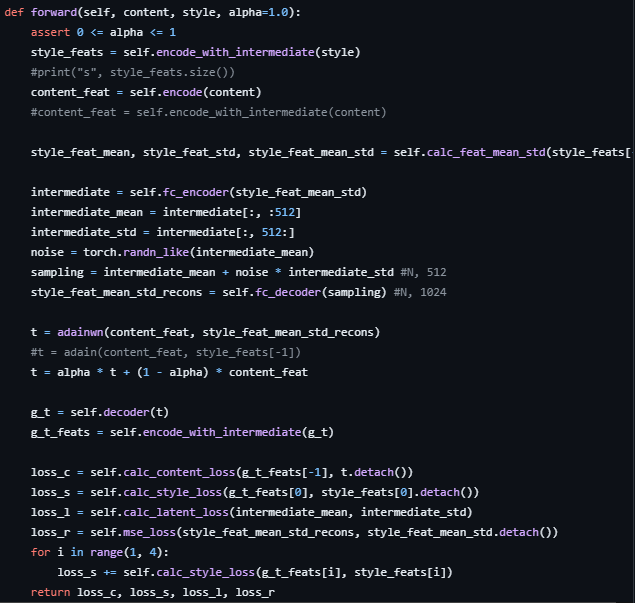
- 초반 코드의 forward 부분.
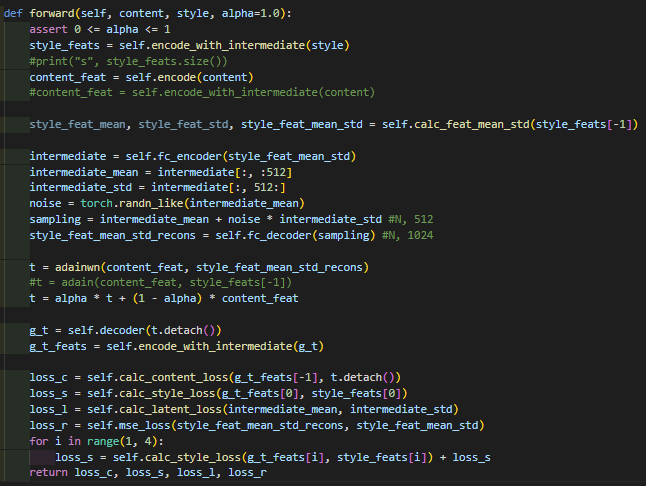
- detach()와 inplace operation을 지워져서 정상적으로 model training을 하도록 만들었다.
2023.05.16 Kyujinpy 작성.



