Github: https://github.com/Marker-Inc-Korea/KoNEFTune
GitHub - Marker-Inc-Korea/KoNEFTune: Random Noisy Embeddings with fine-tuning 방법론을 한국어 LLM에 간단히 적용할
Random Noisy Embeddings with fine-tuning 방법론을 한국어 LLM에 간단히 적용할 수 있는 Kosy🍵llama - GitHub - Marker-Inc-Korea/KoNEFTune: Random Noisy Embeddings with fine-tuning 방법론을 한국어 LLM에 간단히 적용할 수 있는
github.com
Huggingface: https://huggingface.co/kyujinpy/Kosy-Platypus2-13B
kyujinpy/Kosy-Platypus2-13B · Hugging Face
Kosy🍵llama Model Details Model Developers Kyujin Han (kyujinpy) Model Description NEFTune method를 활용하여 훈련한 Ko-platypus2 new version! (Noisy + KO + llama = Kosy🍵llama) Repo Link Github KoNEFTune(not public; wait!): Kosy🍵llama If you
huggingface.co

Github(KoNEFTune): https://github.com/Marker-Inc-Korea/KoNEFTune
안녕하세요!
(주)마커와 (주)미디어그룹사람과숲의 오픈소스 LLM 연구 컨소시엄의 지원을 받아서 연구하고 있는 Kyujin입니다😄
최근에 나온 NEFTune 논문에서 random noise embedding방법을 적용하여 LLM을 tuning시키는 연구를 보게 되었습니다! 간단한 방식이지만, Noise embedding 활용한 instruction fine-tuning 방법이 성능을 향상시킨다는 흥미로운 내용이었습니다!
이를 바탕으로, noise embedding을 활용하여서 실제 훈련에 적용해보고, 논문처럼 정말 성능 향상에 기여할지 테스트를 해보았습니다!

기존에 원본 github에서 훈련을 돌리기 위해서는 여러 과정이 필요했습니다. 이를 간소화 하기 위해서 기존의 transformers module에 직접 noise embedding을 할 수 있는 코드를 추가하여서 모듈을 따로 제작하였습니다!
이후에 만들어진 kosy_transformers 모듈을 활용하여서 ko-platypus을 훈련시킨 방법에서 Noise embedding만 추가하여 훈련시킨 후 성능비교를 진행하였습니다!
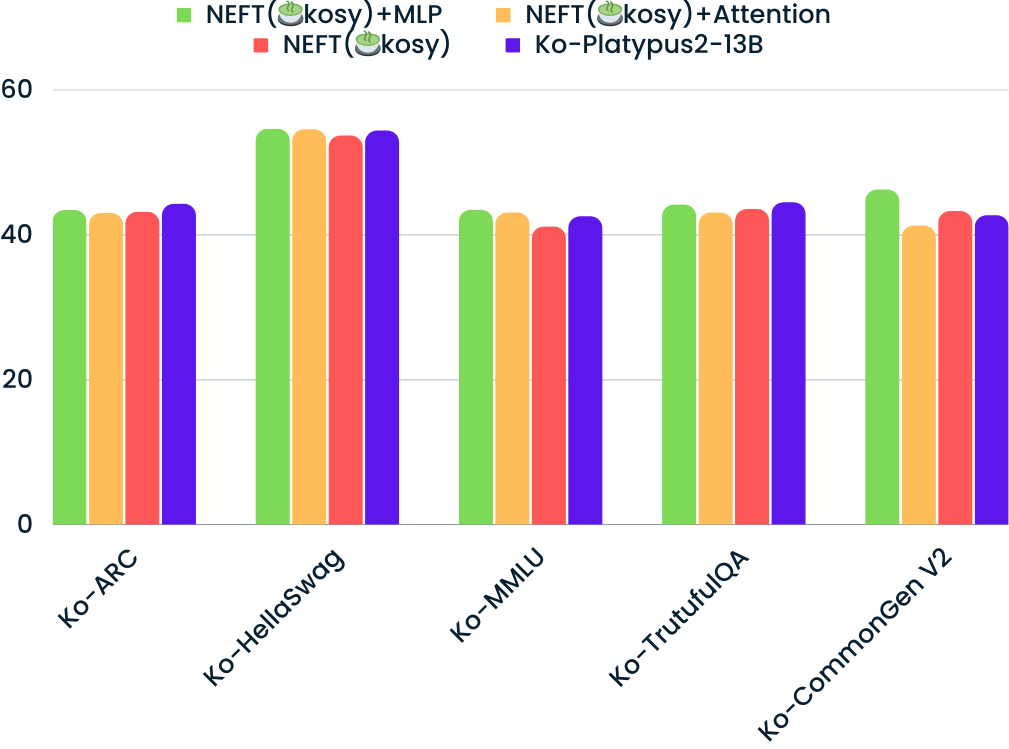
Noisy embedding을 MLP Layer, Attention Layer, 그리고 All Layer에 각각 fine-tuning시키면서 테스트를 진행하였습니다.
결과적으로, MLP Layer만 non-freeze 상태로 fine-tuning시킨 결과가 가장 높은 성능을 낸다는 사실을 알게 되었습니다..!
(물론 하이퍼 파라미터마다 결과값이 달라질 수도 있겠습니다..ㅎㅎ)
NEFTune 방법을 이용하는 코드는 github에 자세하게 설명과 코드를 업로드 하여서 이용 가능합니다!
많은 관심 주셔서 감사합니다!
'AI > LLM project' 카테고리의 다른 글
| [🌸Sakura-SOLAR] - SOLAR 10.7B 모델을 base로 하여 merge와 DPO 방법론을 활용한 LLM (27) | 2023.12.28 |
|---|---|
| [Upstage와 함께 하는 글로벌 OpenLLM 리더보드 1위 모델 리뷰 & LLM 모델 Fine-tuning] (10) | 2023.11.24 |
| [🐳KO-LLM 첫 50 돌파🥮] (7) | 2023.10.15 |
| [🐳Korean-OpenOrca Model 등장🐳] (11) | 2023.10.10 |
| [Poly-platypus-ko] - Polyglot-ko + Ko-Platypus (0) | 2023.10.02 |



