[KoChatGPT 코드 리뷰] - KoChatGPT: ChatGPT fine tuning with korean dataset
References: GitHub - airobotlab/KoChatGPT: ChatGPT의 RLHF를 학습을 위한 3가지 step별 한국어 데이터셋
GitHub - airobotlab/KoChatGPT: ChatGPT의 RLHF를 학습을 위한 3가지 step별 한국어 데이터셋
ChatGPT의 RLHF를 학습을 위한 3가지 step별 한국어 데이터셋. Contribute to airobotlab/KoChatGPT development by creating an account on GitHub.
github.com
My code colab: https://colab.research.google.com/drive/1p6SVWfqgLDYTrQYkfFAxMUbDKtGuhyMl?usp=sharing '
kochatgpt_code_230517
Colaboratory notebook
colab.research.google.com
*제가 references를 참고하여 만든 코드는 기존의 KoChatGPT 코드와 약간 다릅니다. Tokenizer와 prompt format 등등을 수정하였습니다.
Introduction: ChatGPT
ChatGPT Introduction: https://kyujinpy.tistory.com/79
[ChatGPT, InstructGPT 리뷰] - GPT와 Reinforcement Learning Human Feedback
*ChatGPT에 대해서 설명하는 글입니다! 궁금하신 점은 댓글로 남겨주세요! InstructGPT: https://openai.com/research/instruction-following#guide Aligning language models to follow instructions We’ve trained language models that are mu
kyujinpy.tistory.com
코드를 이해하기 전에 ChatGPT에 대해서 전반적으로 이해하고 온다면 보다 깊은 코드를 짤 수 있을 것이다..!
Code Review
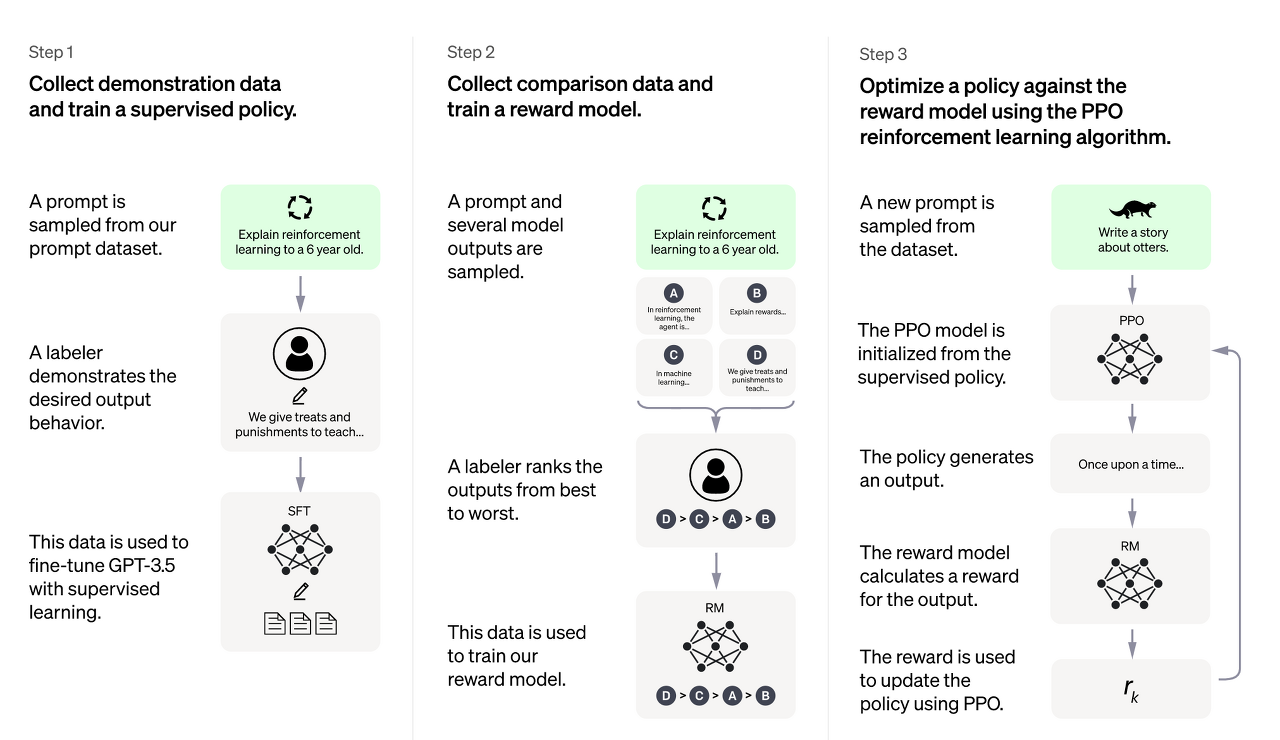
ChatGPT가 훈련 방식인 RLHF를 토대로,
1. SFT(Supervised fine tuning)
2. RM(Reward model) Training
3. PPO(Proximal Policy Optimization)
순으로 Code review를 진행해보겠다!
SFT Code
(Update soon...)
RM Training Code
(Update soon...)
PPO Code
(Update soon...)
2023.05.xx Kyujinpy 작성.